
Scaling 30,000 deployments with 100% uptime. How Clock uses Northflank to simplify infrastructure.
Clock, a digital agency working with household names like Riot Games, Epic Games, Times Plus and Critical Role, has a knack for delivering. Their engineering team built a reliable infrastructure that had served them well for years. But as new client requests surged and project complexity grew, the cracks began to show. Environments took longer to provision, scaling demanded hands-on coordination, and costs weren’t always transparent.
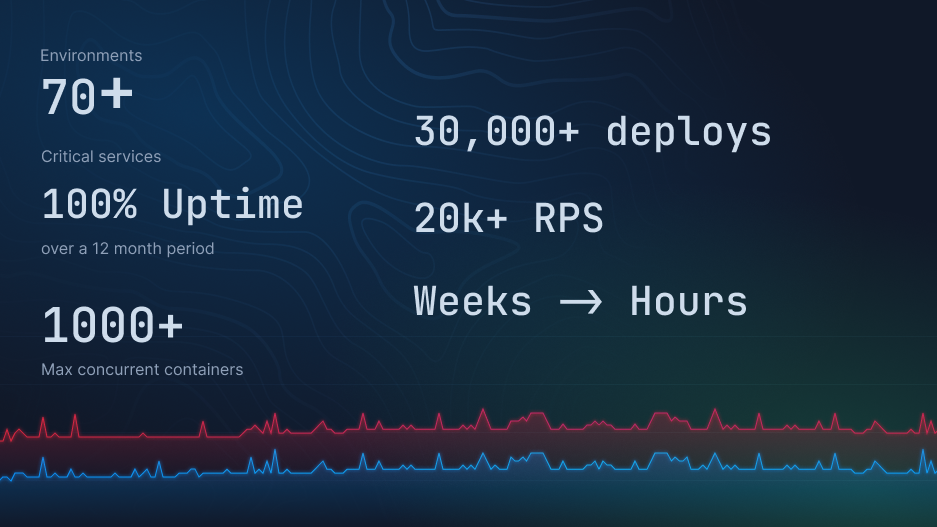
As they grew, their tech stack wasn’t exactly aging like fine wine. With over 70 environments they needed infrastructure as reliable and innovative as their own work. Enter Northflank.
(Now, we know this is a case study, and yes, we’re about to toot our own horn. But when someone like Clock tells us we’ve changed the way they work, we can’t help but feel a little proud.)

Clock’s in-house infrastructure was good—built on robust principles and a dedicated ops team. As they took on more enterprise clients and high-traffic launches, however, the system required more manual oversight.
-
Prolonged staging provisioning: Even with a seasoned engineering team, rolling out staging environments could balloon into a weeks-long process. In a fast-moving agency culture, this delay added overhead and slowed product teams that thrived on quick feedback loops.
-
Scaling demands: Many of Clock's customers would see massive concurrent audiences, pushing Clock to scale hundreds of containers in minutes on bare-metal. While they had a functional process for this, it required heavy involvement from the ops team each time.
-
Opaque costs: Hosting bills would arrive as a lump sum, making it tough to pinpoint which projects or environments drove usage. This made forecasting and client cost breakdowns more difficult.
-
Limited self-service: Though the system was reliable, in-depth logs, backups, and debugging tools often needed ops involvement. This created bottlenecks when product engineers needed immediate insights to troubleshoot issues.
When Clock started exploring alternatives, Northflank stood out immediately. Our platform-as-a-service (PaaS) approach makes complex infrastructure tasks intuitive, accessible, and fast.
“We looked at other solutions like AWS Fargate and App Runner, but they all felt like trying to assemble IKEA furniture without instructions. Northflank was different—it just made sense,” Ash says.

Northflank, on the other hand, felt intuitive from day one. Our platform-as-a-service approach offered exactly what Clock was looking for:
- Ease of use: Developers could spin up services, pipelines, and environments without needing a PhD in cloud computing.
- Flexibility: Whether deploying to Northflank's Managed Cloud, AWS, Google Cloud, or Azure, Northflank made it easy to adapt to clients’ unique requirements.
- Empowerment: With tools like self-service backups, real-time logs, and autoscaling, every developer—from junior to senior—gained hands-on infrastructure experience.
Here's what made us stand out 😇
Staging in hours, not weeks
Creating new environments became as simple as clicking a few buttons. “Before Northflank, staging was an ordeal. Now, I can spin up a fully functional environment in minutes. It’s a game-changer.”
Effortless scaling
For creator economy streams, we automatically scaled services to over 200 containers, handling up to 20,000 requests per second. “We don’t even think about it anymore. Northflank just works.”
Integrated code and infrastructure
With GitOps, developers could bundle infrastructure changes with application code, ensuring deployments were always aligned. “It’s beautiful,” Beth says. “We can now easily see what's running in each environment and where there might be differences and promoting releases from stage to prod is seamless”
Transparent costs
We broke down hosting costs by project and client, giving Clock full visibility for the first time. “We finally have a granular cost breakdown per client, project and service. That alone has been worth it.”

Two years into their Northflank journey, Clock’s workflow has transformed. Deployments are faster, scaling is seamless, and the entire team has gained confidence in their infrastructure.
- Speed: New environments are live in hours, not weeks.
- Reliability: Some workloads have achieved 12+ months of 100% uptime.
- Scalability: Autoscaling effortlessly handles major client launches without manual intervention.
- Developer Happiness: Logs, backups, and metrics are now self-service, empowering every engineer.
“We’ve gone from infrastructure being a constant headache to it being invisible. That’s the highest compliment I can give,” Ash says.

Ash agrees. “It’s rare to find a platform that genuinely empowers your team while making your life easier. With Northflank, we’ve found that. I can’t recommend it enough.”
When a customer says something like this, it reminds us why we do what we do here at Northflank.
If you want to solve your infrastructure woes and give your team the tools to move faster, book a live demo with Northflank today. We can make your work easier, too. 🙂

- 30,000+ deployments since adopting Northflank
- 35 projects managed across Clock’s team.
- 350+ services running on the platform.
- Scaling to 250+ containers during a creator economy launch, handling 20,000+ RPS.
- 12 months of 100% uptime on most workloads.
- Weeks reduced to hours for provisioning new environments

- Services & addons: Simplifies deployments across hundreds of services and databases.
- Pipelines & release flows: Enabled smooth CI/CD workflows and infrastructure automation.
- Templates: Made creating and duplicating environments fast and reliable.
- Autoscaling: Scaled services to handle 100s of containers at peak load at over 20,000 RPS.
- GitOps: Integrated infrastructure changes with application code for seamless deployments.
- Backups & observability: Allowed self-service backups and visibility into logs, CPU, and network metrics.
- Slack notifications: Centralized alerts for scaling, failures, backups, failed builds and traffic spikes.
- Multi-Read/Write volumes: Managed complex data replication needs.
- BYOC (Bring Your Own Cloud): Supported deployments across AWS, Google Cloud, and Azure with ease.
- Docker SHM Size: Provided enhanced Docker container configurations for high-performance needs.


