

What is a cloud GPU? A guide for AI companies using the cloud
A cloud GPU is a graphics processing unit that you access remotely through a cloud provider like AWS, Google Cloud, Azure, or a developer platform like Northflank.
Cloud GPUs are designed to handle highly parallel workloads like training machine learning models, generating images, or processing large volumes of data.
For example, let’s assume you’re building a generative AI product and your team needs to fine-tune a model on customer data. So, what do you do?
- Do you buy a high-end GPU, set up a local machine, worry about cooling, drivers, and power usage, and hope it scales as your needs grow?
- Or do you spin up a cloud GPU in minutes, run your training job in an isolated environment, and shut it down when you’re done?
Which option did you go for? I’m “95%” sure you picked the second one because that’s what most teams do. Cloud GPUs give you the flexibility to focus on your model, not your hardware.
And that’s why cloud GPUs have become a core part of modern AI workflows. I mean, you could be:
- Fine-tuning an open-source model like LLaMA
- Deploying a voice generation API
- Or parsing thousands of documents with an LLM
Chances are you’re using a GPU somewhere in that stack.
For most AI companies, running those workloads in the cloud is faster, easier, and far more scalable than trying to do it locally.
TL;DR:
-
A cloud GPU gives you remote access to high-performance graphics cards for training, inference, and compute-heavy workloads, without owning the hardware.
-
AI teams use cloud GPUs to fine-tune models, run LLMs, deploy APIs, and spin up notebooks.
-
Platforms like Northflank let you attach GPUs to any workload, while also running your non-GPU infrastructure like APIs, databases, queues, and CI pipelines in the same place.
Run both GPU and non-GPU workloads in one secure, unified platform:
Get started for free or book a live demo
Questions about cloud GPU capacity? If you're planning cloud GPU deployments with specific availability or capacity requirements, request GPU capacity here.
Next, I’ll walk you through how cloud GPUs work, so that your team can decide how to best run AI workloads without getting stuck in hardware complexity.
Cloud GPUs work a lot like any other cloud resource. See what I mean:
- You request access to a GPU through a provider
- You define what you want to run (could be a training script or a container)
- The provider provisions the GPU, runs your workload, and tears everything down when it’s done.
To make that clearer, see a simple illustration of what that process usually looks like:
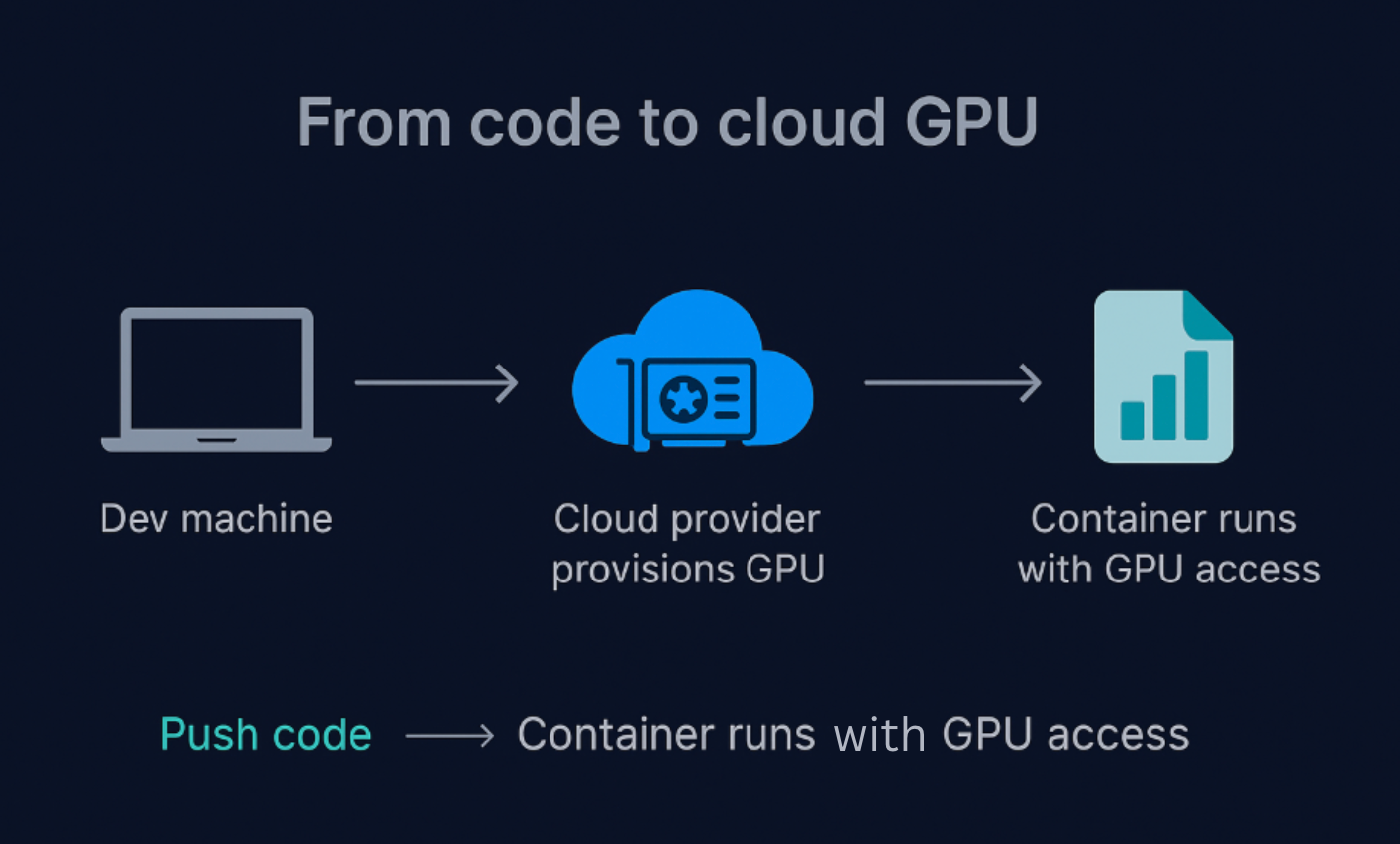 From code to cloud GPU: How your container gets GPU access in the cloud.
From code to cloud GPU: How your container gets GPU access in the cloud.
Once your container is running, your code has full access to the GPU. That could mean:
- Training a model from scratch
- Fine-tuning a foundation model
- Running inference behind an API
- Or scheduling batch jobs with specific GPU needs
The best part is that you don’t have to touch hardware, install CUDA drivers, or manage infrastructure because the cloud handles all of that. So, your team can focus on building and shipping AI, not troubleshooting machines.
Next, we’ll talk about why cloud GPUs are used in AI and what makes them so useful for training, inference, and more.
AI workloads are so much compute-intensive and not in the way a typical web server or database is. For instance, training a model like LLaMA or running inference across thousands of prompts requires what we call “parallel computation,” which is something GPUs are designed for.
Okay, so what does that mean?
You could think of it this way: CPUs are built to handle a few tasks at a time, which is great for general-purpose stuff like running a database or serving an API.
Now, GPUs, on the other hand, are built for scale. They’re designed to run thousands of operations in parallel, which is exactly what deep learning tasks like matrix multiplication or backpropagation need.
That’s why Cloud GPUs have become a go-to for AI teams. A few common examples include:
- Fine-tuning open-source models like LLaMA or Mistral
- Deploying inference APIs that respond to real-time requests
- Running background jobs or scheduled training tasks
- Spinning up Jupyter notebooks for quick experimentation
And because it’s all in the cloud, your team can scale up or down on demand, without owning a single server.
💡Note: Some platforms treat GPU workloads as a separate category, with different setup steps, tools, or workflows. Platforms like Northflank don’t. With Northflank, you attach a GPU and run your job the same way you would for a CPU-based service.
That consistency applies to fine-tuning jobs, inference APIs, notebooks, and scheduled tasks, without needing to reconfigure how your team works. Logs, metrics, autoscaling, and secure runtime are already built in.
Next, we’ll break down how GPUs compare to CPUs, so you can understand what each one is really built for.
We’ve talked about how GPUs are better suited for AI tasks like training models or running inference, but what really makes them different from CPUs?
Let’s see a quick breakdown:
| Feature | CPU | GPU |
|---|---|---|
| Cores | Few cores, optimized for low latency | Thousands of cores, optimized for throughput |
| Use case | General-purpose tasks (web, I/O, DBs) | Parallel computation (e.g. ML, deep learning) |
| Ideal for | Web servers, databases, CI jobs | Model training, LLM inference, vector search |
| Architecture | Complex control logic and branching | Simple cores executing many tasks in parallel |
Let’s also break that down with a few common questions you most likely have:
It depends on the workload, but for deep learning tasks like matrix multiplication or training with large datasets, a single GPU can be a lot faster than a CPU. That’s because GPUs are built to execute thousands of operations at once, while CPUs handle tasks sequentially or in small batches.
Usually yes.
Even when you’re training or fine-tuning a model on a GPU, there’s always a CPU managing orchestration tasks like loading data, handling API requests, or storing checkpoints. So, GPU is like the heavy-lifter, and the CPU is like the coordinator.
Deep learning involves operations like matrix multiplications, convolutions, and activation functions across massive datasets. These are highly parallel operations, something GPUs are made for.
CPUs are better at logic-heavy or branching tasks (like handling web requests), but they can’t match the raw parallelism needed for model training.
💡Note: In most production setups, teams need to run both types of workloads, web services on CPUs and training or inference on GPUs. Some platforms separate those paths entirely, but others, like Northflank, let you run CPU and GPU workloads side by side using the same tools and workflows.
Next, we’ll look at how GPUs made the jump from gaming hardware to powering today’s cloud-based AI workloads.
GPUs didn’t start in AI; they started in games.
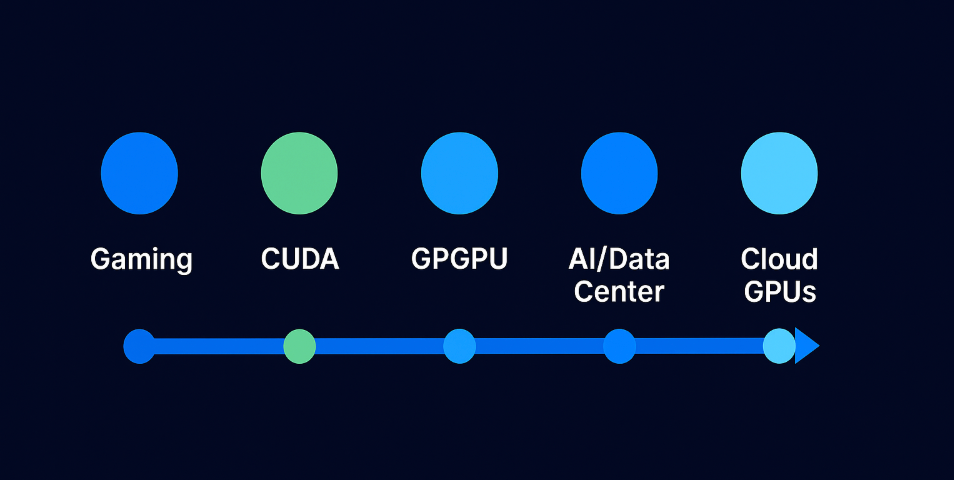 Timeline of GPU evolution: from gaming to CUDA, GPGPU, and the cloud
Timeline of GPU evolution: from gaming to CUDA, GPGPU, and the cloud
In the early 2000s, GPUs were designed almost exclusively for rendering graphics like lighting effects, shading, and 3D transformations in video games. These tasks required processing thousands of pixels in parallel, so hardware vendors like Nvidia built GPUs with hundreds or thousands of tiny cores optimized for this kind of parallel work.
Then something changed.
Researchers and developers realized these same GPU cores could accelerate scientific and data-heavy computations, not only graphics.
Even in a recent Reddit thread, early adopters reflect on how GPUs were pushed beyond gaming long before it went mainstream.
 Reddit user explaining how GPUs were first repurposed for scientific computing around 2009–2010
Reddit user explaining how GPUs were first repurposed for scientific computing around 2009–2010
That’s when the idea of using graphics cards for general-purpose computing called GPGPU started to gain traction.
You might ask:
“What is GPGPU, and how is it different from traditional GPUs?”
GPGPU (General-Purpose GPU) refers to using the GPU’s cores for non-graphics tasks like simulations, numerical computing, or training machine learning models. Traditional GPUs were focused solely on rendering, but GPGPU lets you write programs that use the GPU for broader computation.
Now, the turning point came in 2007 when Nvidia launched CUDA, a developer framework that made GPGPU programming much more accessible.
 Nvidia’s 2007 forum post announcing CUDA 1.0 - a turning point in GPU programming
Nvidia’s 2007 forum post announcing CUDA 1.0 - a turning point in GPU programming
So, rather than hacking graphics APIs to run compute tasks, developers could now write C-like code to run directly on GPUs.
That move made GPU compute mainstream.
Cloud providers began adding GPUs to their infrastructure. AI frameworks like TensorFlow and Pytorch integrated CUDA support. Over time, GPU instances became a standard part of cloud offerings, not only for rendering but also for deep learning, training LLMs, and other high-throughput compute workloads.
You might be wondering:
”What is GPU compute used for today?”
Beyond graphics, GPUs now power workloads like:
- Model training
- Real-time inference
- Data science notebooks
- Voice/image generation
- High-speed simulations.
In many AI use cases, they’ve become essential infrastructure.
So, this journey from gaming to general-purpose compute, and then to cloud workloads, laid the foundation for how we use GPUs today in AI.
Next, we’ll break down the difference between the GPUs powering your gaming laptop and the ones running in AI data centers.
On the surface, both types of GPUs do similar things: they accelerate parallel processing. However, in practice, they’re built for very different environments and workloads.
Let’s see a breakdown of how they compare:
| Feature | Desktop GPU | Server GPU |
|---|---|---|
| Performance | Great for burst-heavy tasks like gaming and video rendering | Tuned for high-throughput, 24/7 compute-heavy workloads (e.g. model training, inference) |
| Memory | Often uses standard GDDR memory, non-ECC | Includes ECC (Error-Correcting Code) memory to catch and fix data corruption |
| Form factor & cooling | Compact, fan-based cooling, consumer PCIe size | Larger, often passively cooled, designed for rack-mounted systems with external airflow |
| Uptime | Not designed for continuous full-load operation | Built for non-stop performance in data centers |
A server GPU (like Nvidia A100, H100, or older Tesla V100 cards) is designed specifically for enterprise workloads like deep learning, large-scale inference, simulations, and cloud-native compute. These GPUs live in data centers and power everything from ChatGPT to autonomous vehicle training.
They usually come with:
- More cores
- More memory (often 40–80 GB+)
- ECC memory
- Support for NVLink or PCIe Gen 4
- Compatibility with multi-GPU clustering
You’re not just paying for raw power; you're paying for reliability, scalability, and specialized features. These GPUs:
- Include ECC memory (adds cost)
- Are validated for long-running jobs
- Have better thermal tolerances
- Often ship with enterprise warranties and driver support
Nvidia also segments pricing based on use case. For example, gaming GPUs may cost $800–$2000, while data center cards often range from $10,000 to $40,000+ per unit.
Technically? Sometimes. But it’s not practical.
Server GPUs often:
- Lack video outputs (no HDMI/DisplayPort)
- Require different drivers or kernel modules
- Are tuned for sustained workloads, not real-time rendering
- May not support consumer gaming APIs out of the box
So, unless you’re doing machine learning on the side, you’re better off with a high-end desktop GPU for gaming.
Server-grade GPUs aren’t about frame rates; they’re about raw compute, stability, and memory at scale.
💡Run workloads on high-grade GPU hardware without buying it
With Northflank, you can access enterprise-grade GPUs like A100s on demand, making it well-suited for model training, inference, or background workers. You don’t have to install a server or purchase the hardware yourself.
Next up, we’ll look at how these GPUs run in the cloud and what makes cloud GPU infrastructure different from running them on-prem.
Once you understand how GPUs power modern workloads, the next question is: should you run them locally or in the cloud?
A local GPU is one that’s physically installed in your own device, like your laptop, desktop, or on-prem server.
A cloud GPU is rented remotely from a provider like AWS, Azure, GCP, or CoreWeave and accessed over the internet.
Look at the table below:
| Feature | Local GPU | Cloud GPU |
|---|---|---|
| Location | On your machine or server | Runs remotely in the cloud |
| Upfront cost | High (hardware purchase) | None (pay-as-you-go) |
| Setup & maintenance | You manage drivers, cooling, power | Handled by the provider |
| Performance | Limited to your hardware | Choose from high-end GPUs on demand |
| Scalability | Static (fixed to one machine) | Dynamic (scale up/down based on workload) |
For many startups and AI teams, cloud GPUs are the obvious choice when you're training large models, scaling inference workloads, or collaborating across regions. See why:
- Scalability: Need 1 GPU today and 16 tomorrow? Easy.
- Pay-as-you-go pricing: No need to commit thousands upfront.
- No hardware maintenance: You don’t worry about drivers, power supply, or failures.
Example: Startups building LLMs or fine-tuning models often spin up multiple A100s on demand, then tear them down when done, something you can’t do with local GPUs.
If your work depends on large-scale training or burst workloads, then yes, cloud GPUs let you scale without buying expensive hardware. For tasks like running Jupyter notebooks, small model experiments, or inference at low volume, a local GPU may be enough (and cheaper long-term).
TL;DR:
- Training large models or scaling up? Use cloud GPUs.
- Running small experiments or budget-conscious? Local GPU might do the job.
💡With platforms like Northflank, you can deploy cloud GPU workloads without managing infrastructure. Attach GPUs to any job or service, scale them on demand, and run your entire stack, from CPU to GPU workloads, on a unified platform.
Next, we’ll look at how virtual GPUs compare to physical ones, and what that means for performance, cost, and isolation when choosing cloud infrastructure.
If you're looking into cloud GPUs, you'll often come across the terms physical GPU and vGPU. These aren’t interchangeable; they represent different ways to allocate GPU power.
I’ll define the differences clearly:
- Physical GPU: A dedicated graphics card installed on a server or workstation. When you use it, you get direct, full access to the hardware.
- Virtual GPU (vGPU): A physical GPU that’s been virtualized and shared between multiple users or virtual machines. Platforms like NVIDIA GRID make this possible.
For example:
A physical GPU is like owning a car. A vGPU is like using a ride-sharing service where you share the same resource, but get your own seat.
Look at the table below:
| Feature | Physical GPU | Virtual GPU (vGPU) |
|---|---|---|
| Performance | Highest (full access to GPU cores) | Slightly reduced (shared with other users) |
| Cost | Higher (dedicated hardware) | Lower (shared usage) |
| Isolation | Full (your workload runs in isolation) | Shared (can impact consistency) |
| Flexibility | Less flexible, but predictable | More flexible, but variable performance |
While physical vs virtual GPUs describe how compute is allocated, it’s also important to think about the infrastructure these GPUs run on, such as bare metal or virtual machines.
This ties into the broader infrastructure choice:
- Bare metal means you're using physical hardware directly, which is better for maximum GPU performance and predictable latency.
- Virtual machines (VMs) run on top of hypervisors and can access vGPUs, which are easier to scale, but with some overhead.
So, if you’re running latency-sensitive tasks like real-time inference, then physical GPUs on bare metal might be a better fit.
Then, for experimentation or running many smaller workloads, vGPUs on VMs could be more cost-efficient.
💡Provisioning bare metal GPUs is only one piece of the puzzle. To run containers reliably, teams also need orchestration, usually with tools like Kubernetes. However, getting Kubernetes to manage GPU workloads efficiently is complex on its own.
That’s where platforms like Northflank help. You get a Kubernetes-based abstraction that removes the setup overhead and gives you GPU-ready orchestration out of the box. It's ideal for deploying AI jobs, inference APIs, and background workers without managing infrastructure complexity.
And beyond infrastructure, you’ll want to think about access: should you rent GPUs on-demand or invest in your own?
I’ll go straight to the point:
- Buy if you need consistent access, have stable workloads, or want to avoid ongoing cloud costs.
- Rent if your usage is spiky, project-based, or if you need access to high-end GPUs you can’t afford outright.
TL;DR
- Physical GPUs = full control and consistent performance
- vGPUs = lower cost and greater flexibility, with some trade-offs
- Match your choice to your workload’s scale, duration, and sensitivity
💡Choose the right GPU setup for your workload
Northflank supports physical GPUs and cloud providers offering virtualized GPUs, so you can pick what fits best for cost, performance, and team needs.
Next, we’ll look at what happens when you’re not just choosing between physical or virtual GPUs, but trying to build and run an entire AI workload on top of them.
AI teams need more than raw GPU access; they need a platform that lets them run full stacks: notebooks, training jobs, inference APIs, background workers, and everything in between.
That’s where Northflank comes in.

Northflank isn’t only about attaching a GPU to a container; it’s about helping you manage the entire lifecycle of your workloads, securely and at scale. See what I mean:
-
Attach GPUs to any job or service
You can run GPU-backed training notebooks, inference APIs, or long-running background jobs. GPU support works across all types of workloads.
-
Support for both CPU and GPU workloads
Run mixed environments in a single deployment. Some jobs can use GPU acceleration while others run on standard CPU nodes.
-
Bring Your Own Cloud (BYOC) and spot GPU marketplace
Deploy to your own cloud account (like AWS or GCP) or use Northflank’s GPU marketplace to find cost-efficient spot capacity.
-
Secure runtime by default
GPU workloads are sandboxed, isolated, and protected from unsafe code execution.
-
RBAC, audit logs, and cost tracking
Control access by team role, track usage across services, and get a clear breakdown of GPU costs.
💡Your full AI infrastructure, beyond the GPU
Northflank runs the services around your model too: APIs, queues, databases, workers, and CI/CD, all with GPU support when you need it.
Next, we'll break down when it’s worth using a GPU compared to running your workload on a CPU.
Not every workload needs a GPU. While cloud GPUs can deliver massive speedups, they’re not always the right fit.
If your workload involves matrix-heavy operations like training or running deep learning models, a GPU can reduce execution time significantly. However, if you're running a standard web server or handling transactional data, sticking to CPUs is more practical.
See the table below:
| Workload type | Use GPU? | Why |
|---|---|---|
| Model training | Yes | Parallel math across large datasets |
| Real-time inference | Yes | Faster response, lower latency |
| Batch data processing | No | Often CPU-bound and linear |
| Web apps or APIs | No | Low parallelism, better on CPU |
| Databases | No | Optimized for CPU |
Let’s make that difference clearer with a simple cost and speed comparison.
Let’s say you’re running an AI inference task that returns results from a fine-tuned model. For example:
| Resource | Inference Time | Cost per Hour (est.) |
|---|---|---|
| CPU (8 vCPUs) | ~500ms | $0.35 |
| GPU (A100) | ~50ms | $3.10 |
If you’re handling high traffic and low latency is essential, the GPU pays off. For small-scale or non-latency-critical workloads, CPUs may be more economical.
To wrap up, the answer is simple:
Cloud GPUs give AI teams the flexibility to scale, the speed to train and serve models faster, and access to enterprise-grade compute, without being locked into costly on-prem hardware.
However, the GPU itself is only part of the story.
Modern AI workloads depend on more than raw compute. They need the infrastructure around it: APIs, queues, CI/CD pipelines, job schedulers, and secure runtimes that can handle both GPU and CPU workloads.
That’s one of the areas where platforms like Northflank help.
Northflank isn’t only a place to get a GPU. It’s a platform built for real-world AI workloads that gives you full control with BYOC (Bring your own cloud), secure execution, team access controls, and flexible deployment workflows across your stack.
Start from here:


