Inference, training, notebooks
Same delightful DevEx
GPU workloads as first-class citizens
Select a GPU type, deploy your container, and start training or serving models. The same, consistent experience across AWS, GCP, Azure, Oracle, CoreWeave, and any neocloud.
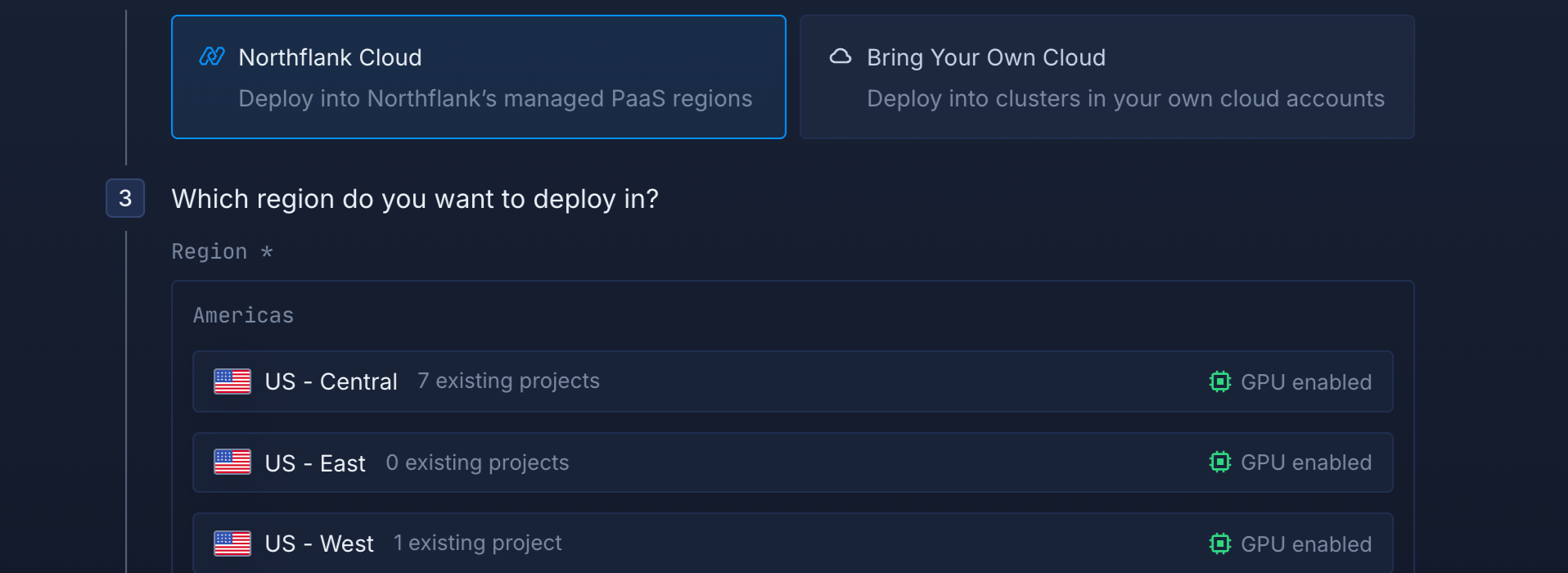
So fast you might miss it
Northflank handles GPU attachment, CUDA driver setup, and cluster provisioning. Your container gets immediate GPU access without infrastructure setup.Same delightful experience
GPUs are just another resource in Northflank. Use the same UI, CLI, and API for CPU and GPU workloads. Same Git integration, CI/CD, and monitoring.Works with any Kubernetes cluster
Deploy on AWS EKS, GCP GKE, Azure AKS, Oracle OKE, CoreWeave, Civo, or any managed Kubernetes with GPU nodes. Northflank abstracts cloud differences so you get the same workflows across all providers.Multi-cloud deployments
Run AI workloads across different hyperscalers & neo-clouds. Aggregate your GPUs easily, switch providers based on GPU availability, pricing, or latency. Without vendor lock-in, consistent experience everywhere.Every AI workload supported
From training to inference to agents
If it runs in a container and needs a GPU, Northflank runs it. LLM training and fine-tuning, real-time inference APIs, batch processing, computer vision, video generation, STT, TTS, agents, and notebooks.
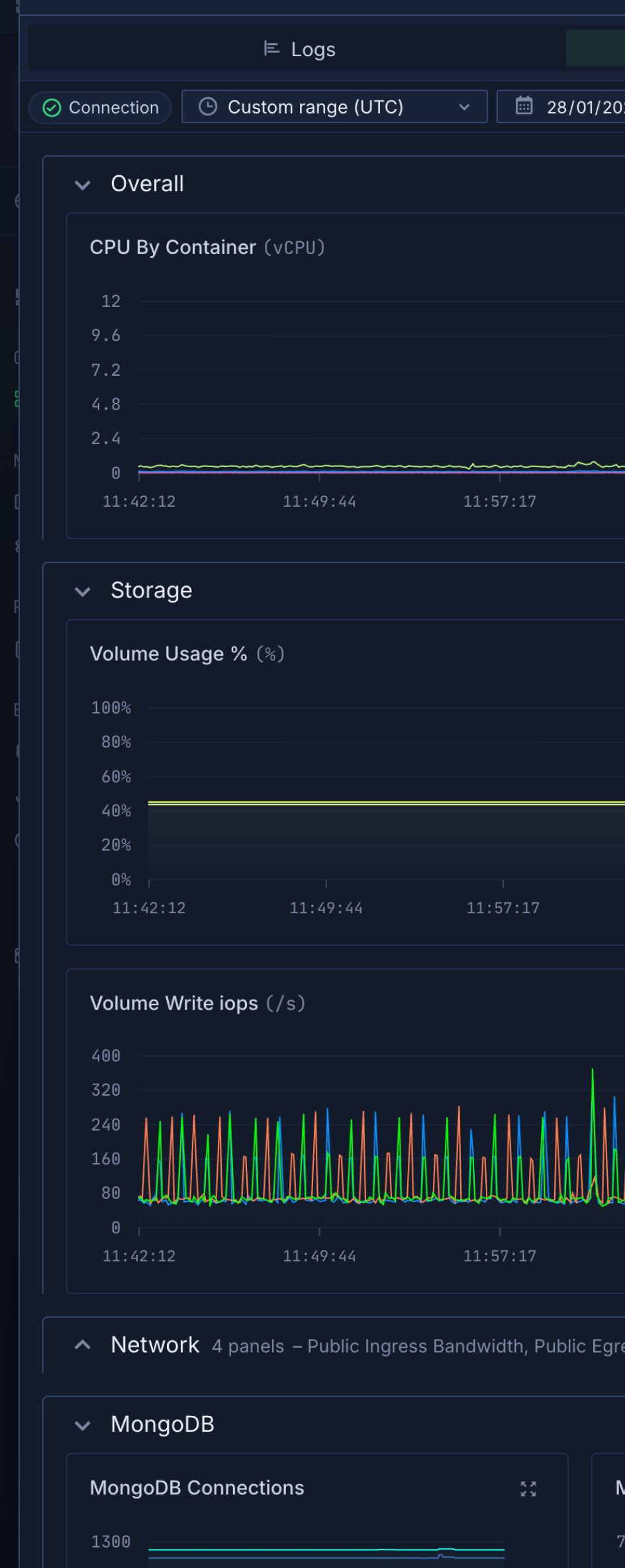
LLM training & fine-tuning
Train foundation models on multi-GPU clusters or fine-tune any open weight model on your data. Support for PyTorch, DeepSpeed, FSDP, and Ray. Checkpoint management and experiment tracking built-in.Real-time inference APIs
Deploy production inference endpoints for text generation, embeddings, or chat completions. Auto-scaling from zero to hundreds of GPUs based on traffic. Sub-100ms latency with automatic batching and model caching.Computer vision & image generation
Run object detection, image classification, segmentation models, or diffusion models for image generation. Deploy Stable Diffusion, DALL-E variants, or custom vision models with GPU acceleration.Video processing & generation
Process video streams, generate synthetic video, or run video understanding models. Transcode at scale, apply ML filters in real-time, or generate video from text prompts with GPU-accelerated pipelines.Code generation & autonomous agents
Run code-generation models, autonomous agents executing tasks, or multi-step reasoning systems. Deploy GitHub Copilot alternatives, coding assistants, or agent frameworks with dedicated GPU resources.Interactive notebooks & experiments
Spin up Jupyter notebooks with GPU access for rapid experimentation. Perfect for data science teams iterating on models. Start and stop on-demand, paying only when actively using GPUs.On-demand, no commit
Scale to 1,000s of GPUs
Choose from NVIDIA H100, H200, B200, A100, L4, L40S, TPUs, and more. Select the right GPU for your workload and budget. Provision in minutes, pay per-second, scale elastically. No waitlists, no long-term contracts, no infrastructure engineering.
Latest NVIDIA & AMD hardware
Deploy on GB300, B200, H100, H200, A100, or L4 for inference, fine-tuning, and training. 18+ GPU types across performance tiers and price points.Per-second billing, instant provisioning
Pay only for GPU seconds used, no hourly minimums. Provision GPUs in minutes, not months. Perfect for bursty workloads, experiments, and production deployments. Scale from 1 to 1,000 GPUs on-demand.GPU time-slicing for efficiency
Run multiple workloads on single GPUs with NVIDIA time-slicing. Share expensive H100s across development, testing, and small inference workloads. Improve utilization by 2-4x, reduce costs dramatically.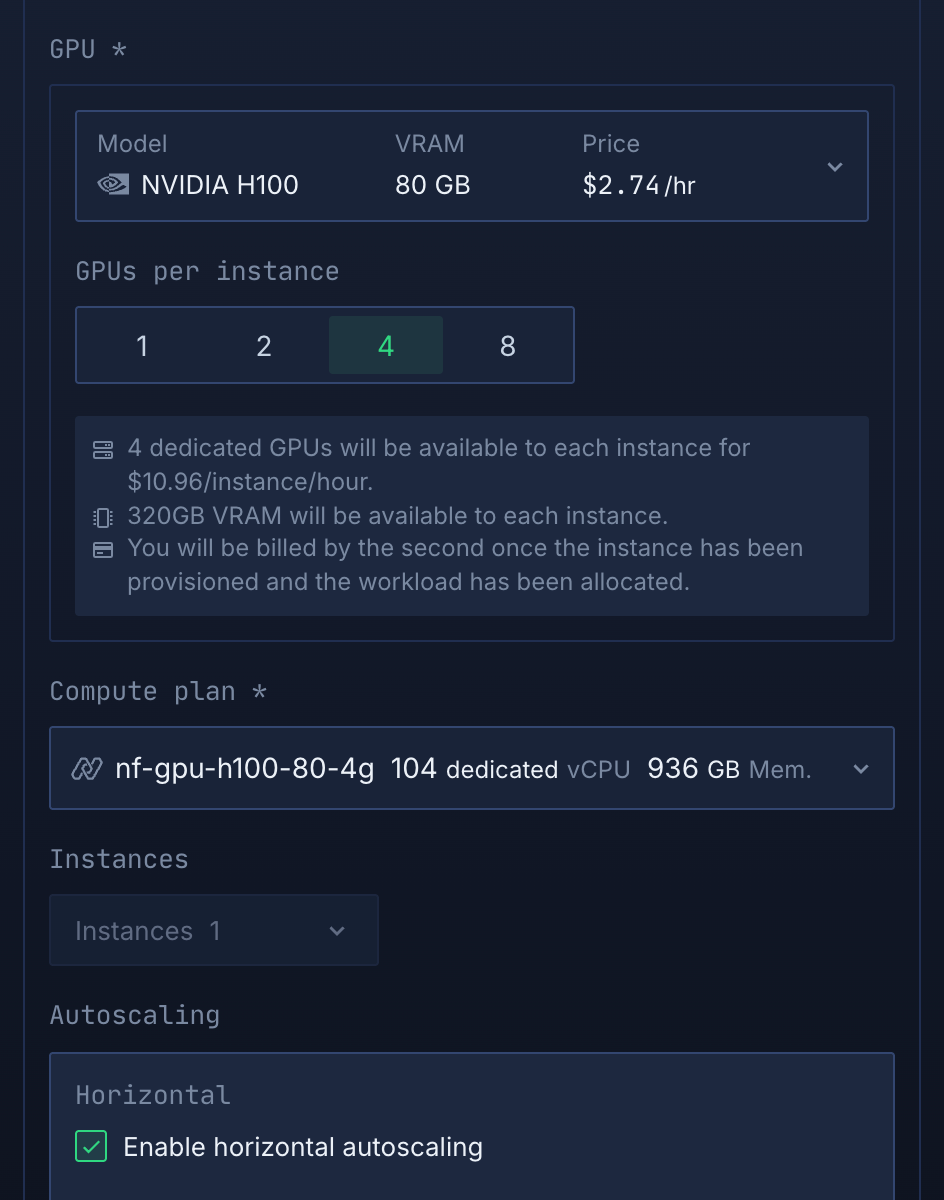
Testimonials from Sentry
From the front lines
Northflank is way easier than gluing a bunch of tools together to spin up apps and databases. It’s the ideal platform to deploy containers in our cloud account, avoiding the brain damage of big cloud and Kubernetes. It’s more powerful and flexible than traditional PaaS – all within our VPC. Northflank has become a go-to way to deploy workloads at Sentry.


Everything where you expect it to be
Optimized for developer happiness
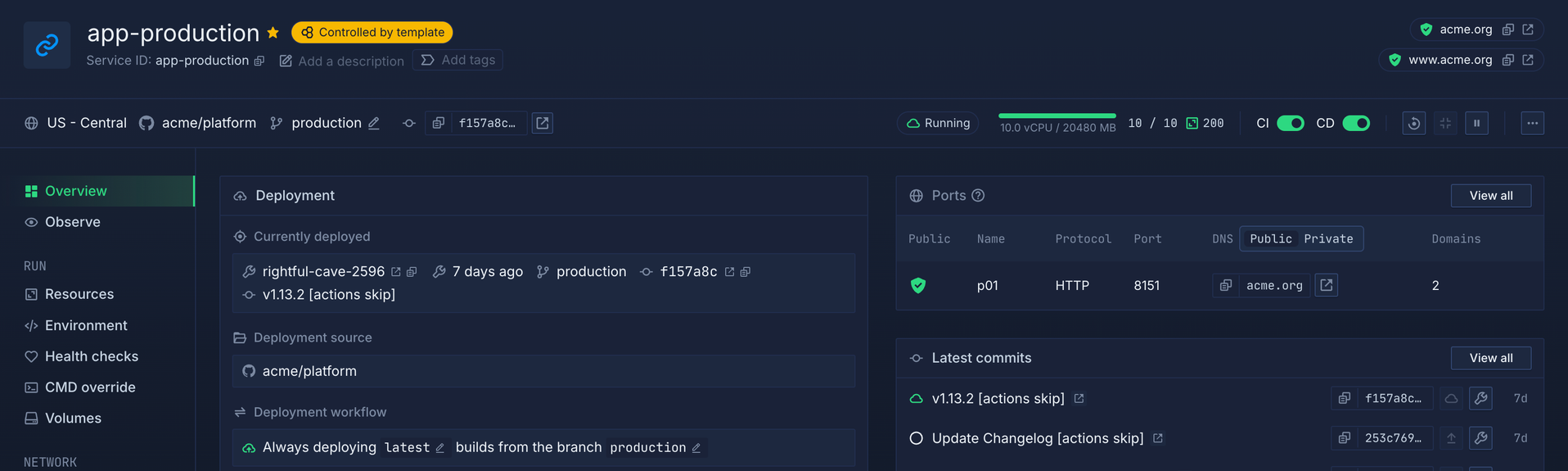
Built for scale
You’re in good company
Since 2019, teams have used Northflank to run everything from enterprise products to high-scale AI infrastructure. Whether it’s one container or one thousand, Northflank holds the line.
Millions
of containers
130B+
Requests processed
$24M+
Raised in funding
100k+
Developers in production
330+
Availability zones
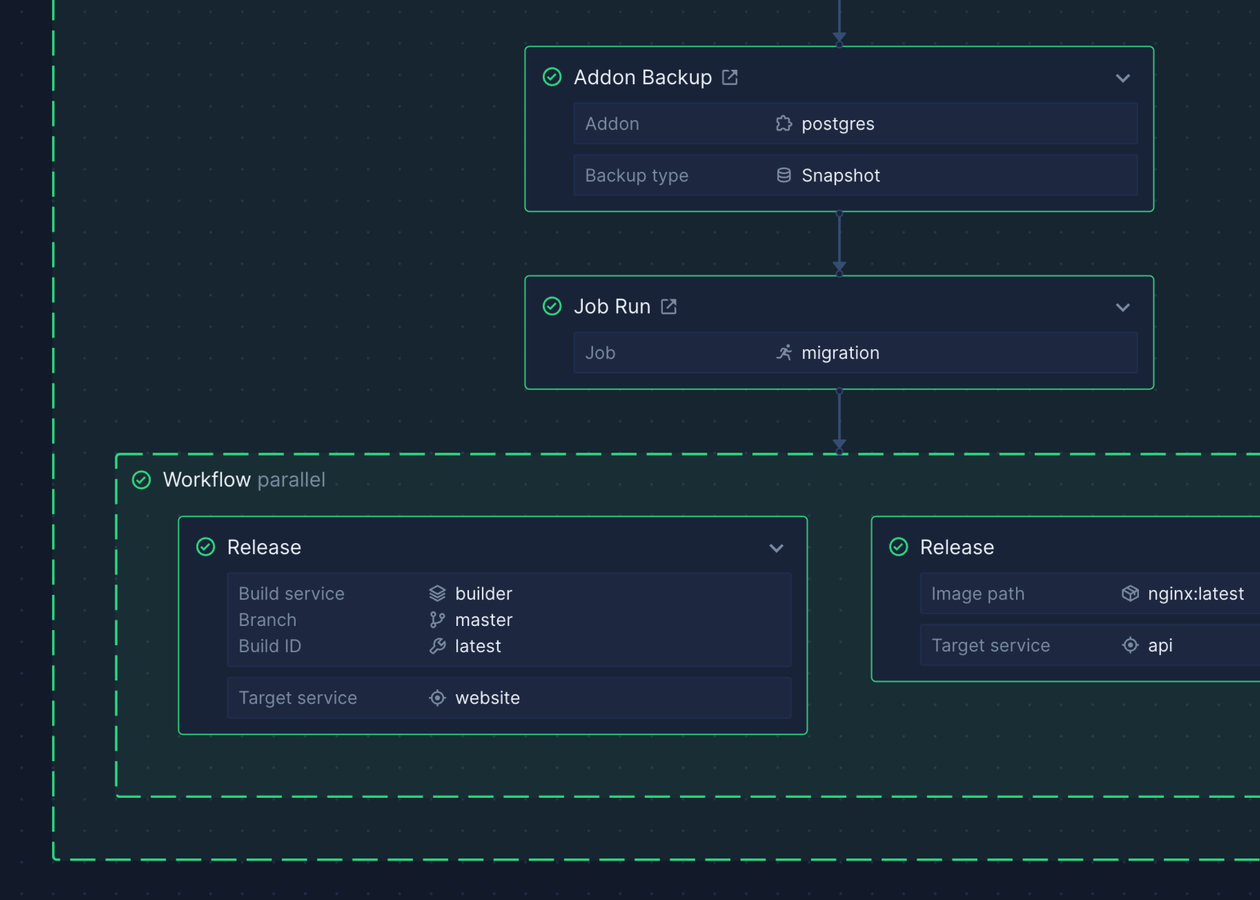
Git-based workflows for ML models
CI/CD that understands GPU workloads
Push code to Git and deploy automatically to GPUs. We handle Docker builds, provisioning, and deployment. Preview environments for model experiments, gradual rollouts for inference APIs, rollbacks when needed.
Deploy ML models from Git
Use Git and CI/CD with Dockerfiles for container-based DevEx in model development, training, and production. Or use Northflank’s SSH and volumes for remote development and experiments. Version control for models, data pipelines, and deployment configs.Integrated storage for datasets
Co-locate GPU compute with managed databases, S3-compatible object storage, and persistent volumes. Low-latency data access for training. Store model weights, checkpoints, and datasets alongside compute.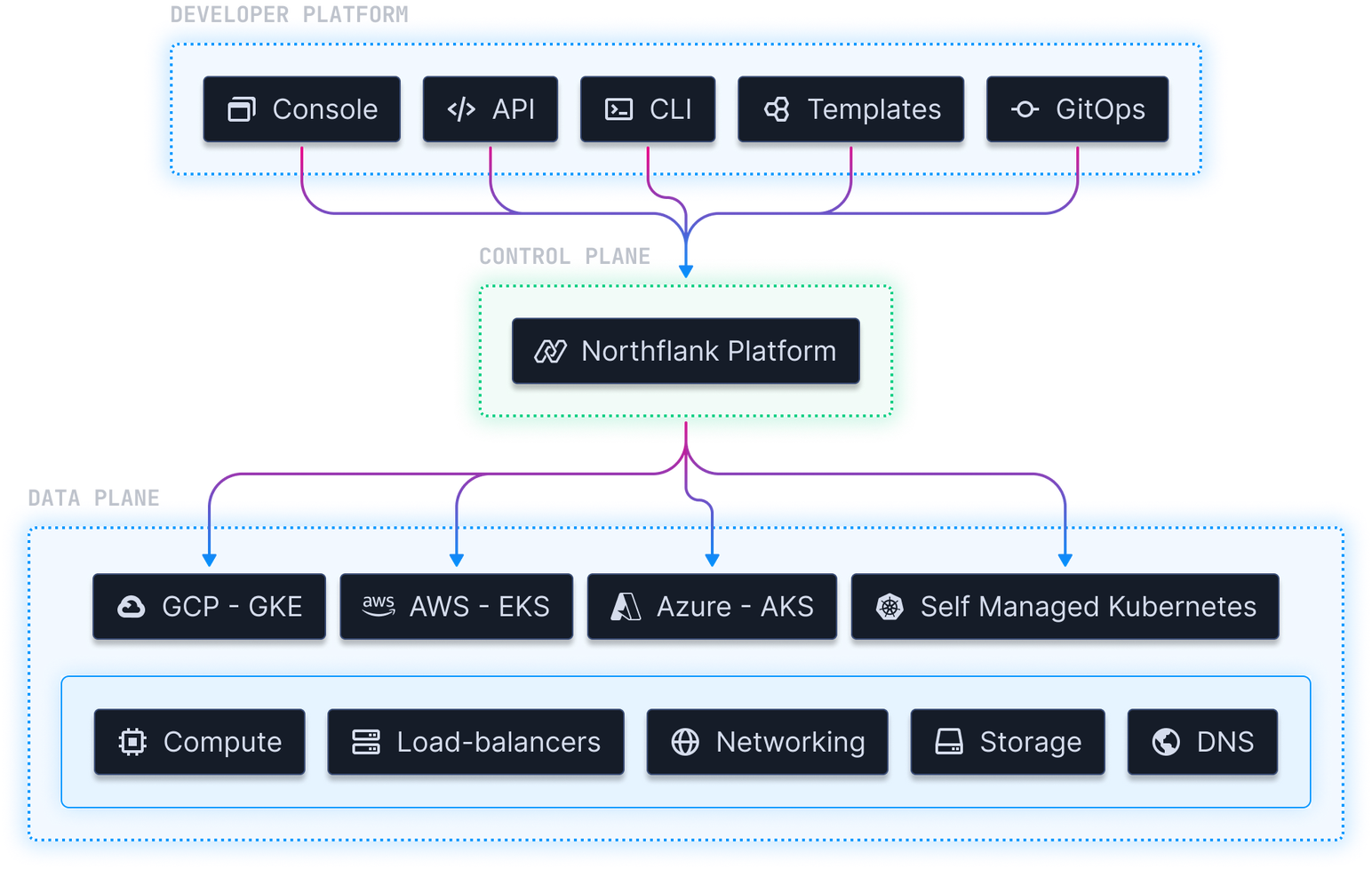
Auto-scaling
Inference endpoints scale from zero to hundreds of GPUs based on traffic. Handle viral traffic spikes automatically. Scale down during quiet periods to minimize costs. Intelligent queuing prevents request drops.Observability
Real-time GPU utilization, memory usage, and temperature monitoring. Track inference latency, throughput, and costs per workload. Integrated logging for training runs and debugging inference issues.Testimonials from Pebblebed
From the front lines
Northflank is the first batteries-included developer platform that doesn’t suffer from the invisible ceilings that hover over its competitors. We could have built all of Slack with Northflank – and we would have, had it been available.


Features
Developer experience
Developer experience
- Choice of UI, CLI, APIs & GitOps
- Runs on AWS, GCP, Azure, Oracle
- Build re-useable templates
Polyglot platform
Polyglot platform
- Run any language or framework
- All envs, from preview to production
- Works with GitHub, GitLab and Bitbucket
Run your AI
Run your AI
- Scale GPUs across clouds
- Run untrusted code at scale
- Serve your inference & models
- Support fractional GPU workloads
We fixed Kubernetes
We fixed Kubernetes
- Kubernetes-ready app platform
- Run anywhere, on any Kubernetes cluster, on any cloud
- EKS, GKE, AKS, Rancher, OpenShift, Tanzu ready
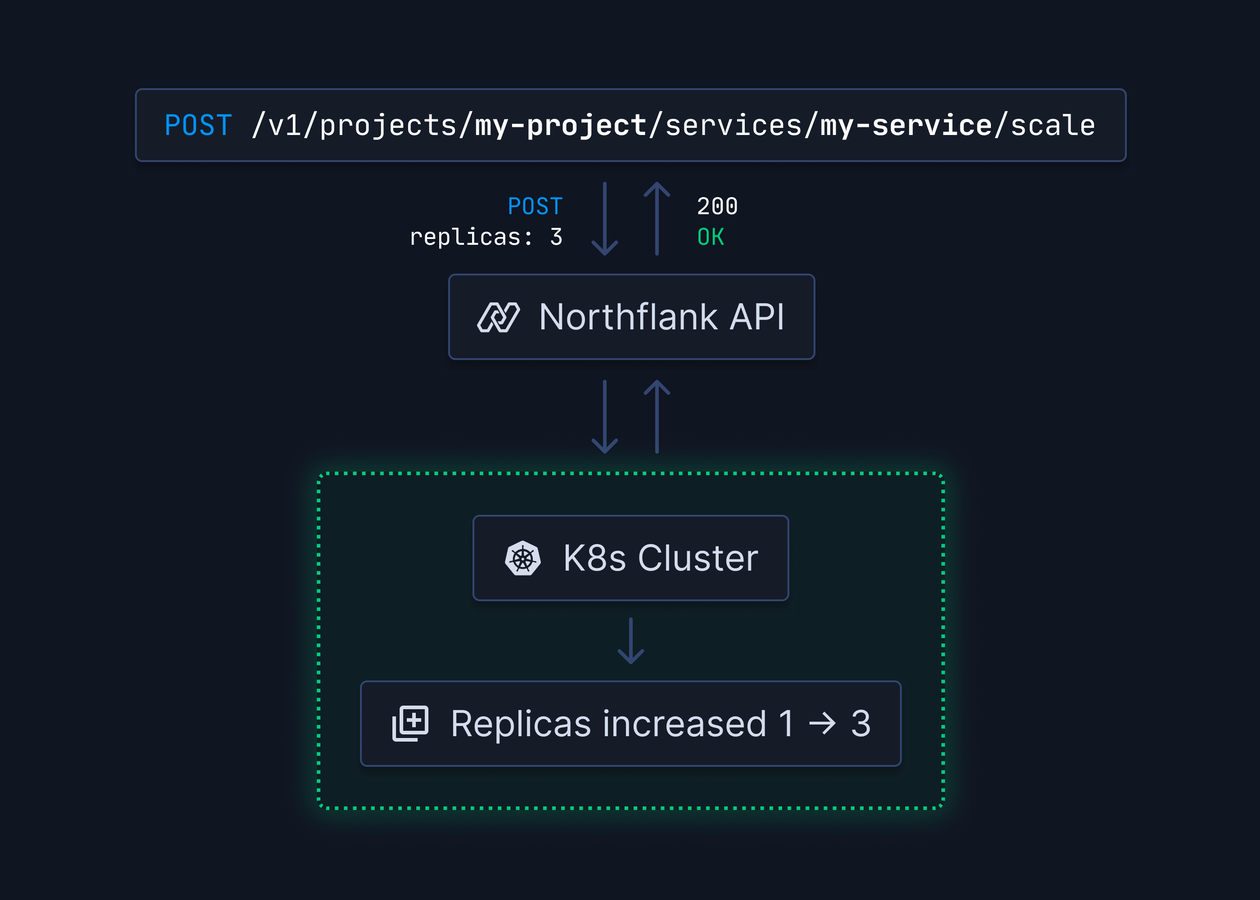
If name-dropping helps, here you go.



