

7 Best AI cloud providers for full-stack AI/ML apps
Most AI platforms help you run models. Few help you build products. If you're fine-tuning LLMs, deploying APIs, or launching full-stack ML apps, you need more than access to GPUs. You need a cloud platform that supports the full pipeline from training and inference to CI/CD, staging, and production.
Big providers like AWS and GCP offer the compute, but can slow you down with overhead. Lighter platforms feel fast, but fall short when you need control. That’s where platforms like Northflank come in, offering modern GPU orchestration with real developer workflows built in.
This guide breaks down the top AI cloud providers in 2026 and how they stack up for model deployment, full-stack apps, and production-ready ML infrastructure.
If you're short on time, here are the top picks for 2026. These platforms are optimized for full-stack ML development, model deployment, and LLM app delivery, not just spinning up GPUs.
| Provider | What It Offers | Best For |
|---|---|---|
| Northflank | GPU workloads, APIs, full-stack deployments, CI/CD, secure environments, Bring your own cloud | Production-grade platform for deploying AI apps — GPU orchestration, Git-based CI/CD, Bring your own cloud, secure runtime, multi-service support, preview environments, secret management, and enterprise-ready features. |
| AWS (SageMaker, Bedrock) | Managed model training, serverless inference, deep cloud integration | Enterprises, hybrid workflows, scaling LLMs |
| Google Cloud (Vertex AI) | MLOps tooling, prebuilt pipelines, TPU + GPU support | Training + deploying with Google-native ML stack |
| Azure (ML Studio, OpenAI services) | Model deployment, enterprise security, Microsoft integrations | Regulated workloads, internal Copilots, Office integration |
| Replicate | Turn models into APIs, deploy from GitHub repos | Lightweight model hosting, indie devs, community demos |
| Anyscale | Built on Ray, runs distributed model jobs at scale | Large-scale fine-tuning, Python ML infra |
| Modal | Run functions in the cloud with GPU/CPU autoscaling | Serverless inference, LLM utilities, lightweight compute jobs |
AI cloud providers today are expected to be full platforms, not just infrastructure layers. That means going beyond GPU access to include deployment workflows, secure runtimes, automation, and developer experience. Here’s what matters most:
- Access to modern accelerators: H100, L40S, MI300X, and TPUs needs to be available, with fast provisioning and real capacity.
- Model deployment pipelines: Support for staging, production, and versioned model endpoints. Deployments should be automated and reproducible.
- Environment isolation and secrets: Teams need isolated environments for dev, staging, and prod, with secure secrets and configuration management.
- CI/CD for ML workflows: Git-based deploys, preview environments, rollback support, and runtime observability all matter in production AI.
- Native ML integrations: Hugging Face, PyTorch, Triton, Jupyter, Weights & Biases, and containerized runtimes should be first-class citizens.
- Transparent billing and usage tracking: Per-second GPU usage, fixed pricing tiers, and built-in observability reduce cost surprises.
- Bring Your Own Cloud: For teams with compliance or infra preferences, support for hybrid or BYOC setups is essential.
This section goes deep on each AI cloud provider in the list. You’ll see what types of GPUs they offer, what they’re optimized for, and how they actually perform in real workloads. Some are ideal for researchers. Others are built for production.
💡Note on GPU pricing
We haven’t included exact pricing here because GPU costs change frequently based on region, demand, and available hardware.
That said, Northflank offers some of the most competitive GPU pricing for production workloads without requiring large upfront commitments.
For providers like AWS and GCP, competitive rates often require long-term reservations or high minimum spend. In contrast, Northflank provides flexible, on-demand access with transparent pricing and real availability, making it a strong option for teams of all sizes.
Northflank brings the full DevOps experience to AI. It combines autoscaling GPU workloads with full-stack application support, CI/CD pipelines, environment separation, and infrastructure automation. You can deploy your model, backend, frontend, and database on a managed cloud or your own VPC.
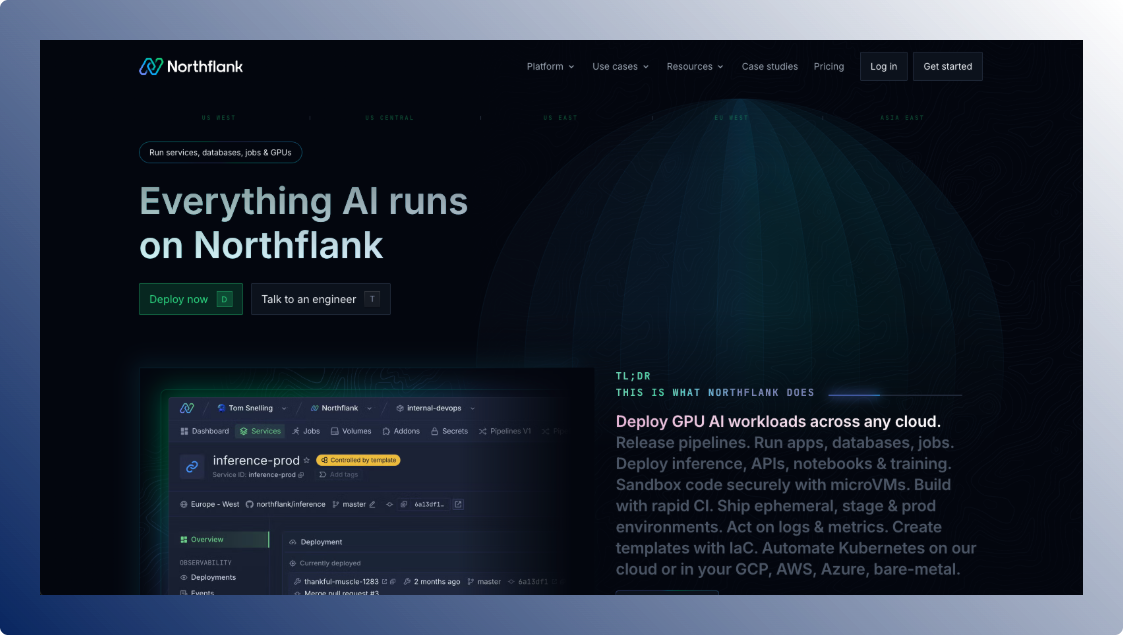
What you can run on Northflank:
- GPU training, fine-tuning, and inference jobs
- Full-stack LLM products (UI, API, DB)
- Background workers, schedulers, and batch jobs
- Secure multi-env deployment (dev, staging, prod)
What GPUs does Northflank support?
Northflank offers access to 18+ GPU types, including NVIDIA A100, H100, L4, L40S, AMD MI300X, TPU v5e, and Habana Gaudi. View the full list here.
Where it fits best:
If you're building production-grade full-stack AI products or internal AI services, Northflank handles both the GPU execution and the surrounding app logic. It’s a strong fit for teams who want Git-based workflows, fast iteration, and zero DevOps overhead.
See how Cedana uses Northflank to deploy GPU-heavy workloads with secure microVMs and Kubernetes
AWS gives you deep flexibility through SageMaker and Bedrock. You get access to model training pipelines, inference endpoints, fine-tuning tools, and enterprise-scale compute with access to H100 and L40S instances.
What you can run on AWS:
- Fine-tuning with Hugging Face or JumpStart
- Fully managed inference endpoints
- Enterprise LLM integrations (Anthropic, Meta, Mistral)
What GPUs does AWS support?
AWS supports a wide range of GPUs, including ****NVIDIA H100, A100, L40S, and T4. These are available through services like ****EC2, SageMaker, and Bedrock, with support for multi-GPU setups.
Where it fits best:
For large companies already in the AWS ecosystem, or teams needing scale with control over infrastructure.
Vertex AI brings together Google’s AI tooling, including TPUs, prebuilt pipelines, and support for TensorFlow and PyTorch. It supports end-to-end ML workflows, including model registry, training, and deployment.
What you can run on GCP:
- Custom model training on GPUs or TPUs
- Pretrained model deployment via AI Studio
- Data pipelines and managed notebooks
What GPUs does GCP support?
GCP offers NVIDIA A100 and H100, along with Google’s custom TPU v4 and v5e accelerators. These are integrated with Vertex AI and GKE for optimized ML workflows.
Where it fits best:
Ideal for teams that rely on Google-native tools or want integrated MLOps pipelines with TPU acceleration.
Azure focuses on integrating OpenAI’s APIs with enterprise systems. You can fine-tune models, deploy endpoints, and integrate with internal systems through the Microsoft stack (Teams, Office, Outlook).

What you can run on Azure:
- OpenAI GPT endpoints and fine-tuned models
- Internal Copilot agents
- Secure multi-tenant deployments
What GPUs does Azure support?
Azure supports NVIDIA A100, L40S, and AMD MI300X, with enterprise-grade access across multiple regions. These GPUs are tightly integrated with Microsoft’s AI Copilot ecosystem.
Where it fits best:
For enterprises needing compliance, internal tooling, and secure model deployments within Microsoft environments.
Replicate lets developers deploy models from GitHub repos and run them as hosted APIs. It’s ideal for fast iteration and demo apps using community or custom models.
What you can run on Replicate:
- Hugging Face models as hosted APIs
- Inference endpoints with GPU usage billed per second
- Community demos and shareable LLM tools
What GPUs does Replicate support?
Replicate supports a variety of NVIDIA GPUs, including A100, H100, A40, L40S, RTX A6000, RTX A5000, and more.
Where it fits best:
Best for indie builders and devs looking to turn models into working demos or tools without infrastructure setup.
Anyscale is built on Ray, which means it excels at large-scale Python AI tasks that require parallelism. It abstracts away infrastructure and supports autoscaling jobs.
What you can run on Anyscale:
- Hyperparameter search
- Multi-node training jobs
- Distributed inference or data pipelines
What GPUs does Anyscale support?
Replicate supports a variety of NVIDIA GPUs, including A100, Tesla V100, and more.
Where it fits best:
For ML engineers and researchers building large custom pipelines or distributed AI workloads.
Modal offers a Python-native way to run functions in the cloud with GPU/CPU autoscaling. It’s minimalistic but powerful for AI engineers working on tooling, APIs, and small apps.

What you can run on Modal:
- Inference functions (image, text, audio)
- LLM utilities and embedding pipelines
- GPU batch jobs triggered via API
What GPUs does Anyscale support?
Modal supports a variety of NVIDIA GPUs, including the T4, L4, A10G, A100, H100, and L40S.
Where it fits best:
When you want to run lightweight ML workloads without provisioning infra or containers manually.
There’s no single “best” provider, only what fits your stack, team, and product goals. Here’s a quick guide by use case.
| Use Case | Priorities | Providers to consider |
|---|---|---|
| End-to-end LLM product deployment | CI/CD, environment separation, API support, observability, full-stack deployments | Northflank |
| Model training and fine-tuning | H100/TPU access, job orchestration, pipeline automation | Northflank, GCP, AWS, Azure, Anyscale |
| Serverless inference at scale | Low-latency APIs, autoscaling, per-call billing | Northflank, Modal, Replicate |
| Enterprise Copilot-style tools | Compliance, hybrid cloud, Microsoft/OpenAI integrations | Azure, AWS, Northflank |
| Distributed AI research | Ray support, multi-node GPU orchestration | Anyscale, GCP, AWS, Northflank |
Most platforms help you run models. The better ones help you build real products. This guide covered the top AI cloud providers that support everything from training and fine-tuning to deployment, versioning, and full-stack delivery.
If you're building something beyond a single endpoint, such as internal tools, AI-powered products, or multi-service applications, platforms like Northflank offer more than just access to GPUs. You get fast provisioning, strong developer workflows, and the flexibility to deploy across environments without extra overhead.
Try Northflank or book a demo to see how it fits your stack.


