

Best serverless GPU providers in 2026
Serverless GPU platforms have matured into serious infrastructure for deploying and scaling AI workloads.
Teams now expect persistent environments, hybrid cloud flexibility, and full-stack support, not just GPU runtime.
This guide provides a technically grounded comparison of the top serverless GPU platforms in 2025, including detailed breakdowns of their runtimes, orchestration capabilities, and suitability for production systems.
But first, let’s go through the basics.
Serverless GPU capacity questions? If you're planning production deployments and need to ensure GPU availability, request GPU capacity here.
Serverless GPUs let you run GPU-powered workloads without manually provisioning infrastructure. Instead of renting full-time access to GPU machines, you submit a job or deploy a container, and the platform assigns a GPU for just the time you need.
You don’t manage servers, install CUDA drivers, or configure autoscaling. The platform handles that. You only focus on your model, script, or API.
These platforms usually rely on containerized or microVM-based runtimes with access to attached GPUs (e.g. A100s, H100s, L4s). Most charge per second or per job, and many scale automatically based on demand.
Using serverless GPUs solves three key problems:
- Provisioning complexity: No need to manage VMs, AMIs, or GPU quotas across cloud providers.
- Cost efficiency: You don’t pay for idle GPUs. Useful for bursty or on-demand jobs like inference, fine-tuning, or image generation.
- Developer velocity: Most platforms offer simple SDKs, Git integration, and APIs that allow fast iteration and deployment.
You can build:
- Model inference APIs
- Image or video generation pipelines
- Audio transcription endpoints
- Interactive notebooks or agents
- Secure user-submitted code sandboxes
With the right platform, you can handle all of the above with proper orchestration, sandboxing, and observability.
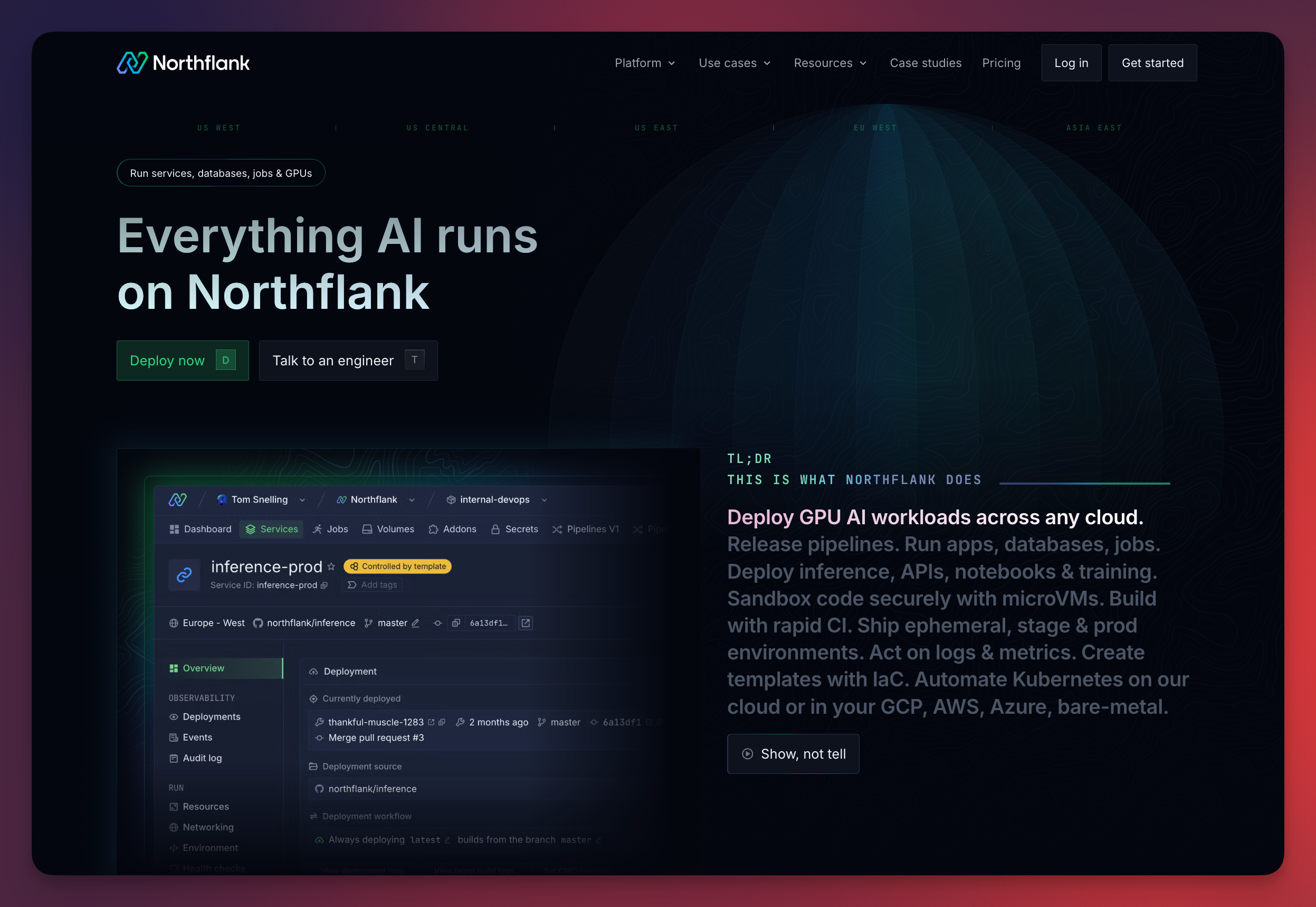
Northflank ranks highest among all current platforms. It’s the only one that offers secure microVM isolation, persistent GPU runtimes, CI/CD integration, BYOC support, and full-stack orchestration across services and jobs.
Where most platforms stop at "run a container on a GPU," Northflank gives you a full environment:
- Inference endpoints with autoscaling
- Cron jobs and background processes
- Secure sandboxed runtimes for untrusted code
- Real-time logs, metrics, and alerts
Whether you’re running a Transformer model on H100s or chaining CPU+GPU tasks in a multi-service setup, Northflank delivers both the infrastructure and the operational layer.
It depends on what you're optimizing for:
- Best all-around infrastructure: Northflank
- Best for Python-only batch jobs: Modal
- Best for public model inference: Replicate
- Best for model dashboards: Baseten
If you're shipping production systems that require long-lived APIs, job queues, notebooks, or secure execution, Northflank is the most robust and future-proof option.
| Compute type | Northflank | Modal | Baseten | Replicate | RunPod | Koyeb |
|---|---|---|---|---|---|---|
| A100 | $1.42/ h | $2.50 / h | $4.00 / h | $5.04 / h | $2.72 / h | $2.0 / h |
| B200 | $5.87 / h | $6.25 / h | $9.98 / h | N/A | $5.99 / h | N/A |
| H100 | $2.74/h | $3.95 / h | $6.50 / h | $5.49 / h | $4.18 / h | $3.30 / h |
| H200 | $3.15 / h | $4.54 / h | N/A | N/A | $5.58 / h | N/A |
| L4 | Coming soon | $0.80 / h | $0.8484 / h | N/A | $0.69 / h | $0.70 / h |
| T4 | Coming soon | $0.59 / h | $0.6312 / h | $0.81 / h | N/A | N/A |
*Prices are approximations as of mid-2025 and subject to change
**For Modal and Replicate, you also have to pay for CPU and memory on top of GPUs.
Northflank is a full-stack platform built for secure, production-grade GPU orchestration. It combines serverless execution with microVM-based isolation, making it ideal for running inference APIs, fine-tuning pipelines, and GPU-powered agents at scale.
Pros:
- Runs GPU workloads inside a secure runtime environment so you can run untrusted AI generated code
- Persistent services with volume support and background jobs
- CI/CD pipelines with GitHub/GitLab integration
- Multi-service orchestration with GPU + CPU coordination
- BYOC and VPC deployment support
Cons:
- More infrastructure primitives to learn compared to plug-and-play platforms
- Overhead of configuration may not suit extremely simple demos
Best for: Teams deploying AI systems that need orchestration, multi-cloud control, and production-grade observability.
Northflank supports long-running services, scheduled jobs, and CI/CD pipelines, all with GPU-backed compute. Northflank can run LLMs on demand, host fine-tuning pipelines with persistent storage, and execute untrusted code inside isolated microVMs.
It supports multiple isolation types, gVisor, Kata, Firecracker, and lets users deploy across both managed infrastructure and private cloud environments. It integrates natively with GitHub, GitLab, and container registries.

Modal provides a Python-native SDK to run GPU-backed batch jobs and workflows. It prioritizes developer simplicity, letting engineers define functions and run them on A10 or A100 GPUs with minimal boilerplate.
Pros:
- Easy to define GPU workflows via Python decorators
- Fast cold start times for stateless jobs
- Good for chaining CPU/GPU steps in data pipelines
Cons:
- No persistent services or API endpoints
- No storage volume support or runtime customization
- Limited CI/CD and observability tools
Best for: Python engineers experimenting with short-lived inference or data jobs who don’t need orchestration or persistent infrastructure.
Modal focuses on a Python-native interface to GPU jobs. You write Python functions, decorate them with @stub.function(gpu="A10"), and Modal handles packaging and execution.
But it lacks long-lived runtimes, persistent volumes, job queues, or background workers. Every job is stateless. That makes it a better fit for model experimentation than for running anything user-facing.

Baseten is a hosted model serving platform focused on abstracting infrastructure. It lets users upload models and exposes them as HTTP endpoints with built-in autoscaling, dashboards, and alerts.
Pros:
- UI-driven deployment with minimal setup
- Automatic scaling and request monitoring
- Supports Hugging Face and PyTorch models
Cons:
- No support for background workers or job queues
- Limited visibility into runtime and GPU configuration
- Lacks secure sandboxing or BYOC support
Best for: Teams shipping internal model APIs or dashboards that want a simple way to host and monitor inference endpoints without building infra.
Baseten abstracts infrastructure entirely. You upload a model, configure the API, and expose it to users. Baseten manages autoscaling, logging, and basic metrics.
Baseten lacks CI/CD integration, orchestration, or secure isolation. It doesn’t expose underlying container logic, GPU configurations, or billing granularity. It’s a fit for simplicity over flexibility.

Replicate offers instant access to pre-hosted open-source models through public HTTP endpoints. Users don’t deploy code; they simply select a model and call it via API.
Pros:
- Zero-config deployment for hundreds of models
- Fast API setup for demos and prototypes
Cons:
- No control over execution, hardware, or environment
- No support for custom models or model weights
- Not suitable for secure or scalable workloads
Best for: Quick testing of public models, MVP demos, or hobby projects that don’t require customization, privacy, or observability.
Replicate gives developers hosted endpoints for popular models. You don’t manage infrastructure at all. Just pick a public model and call an API.

RunPod gives users low-cost access to dedicated GPU machines with optional container orchestration. You can launch notebooks or long-running containers with encrypted volumes.
Pros:
- Wide GPU selection including H100, A100, 4090
- Persistent runtimes with attached volumes
- Spot instance pricing and low hourly rates
Cons:
- Manual setup required for orchestration and monitoring
- Slow startup latency for bare metal nodes
- Lacks native CI/CD and service autoscaling
Best for: ML engineers running training jobs or internal workloads who want flexible, raw GPU compute at a low price point.
RunPod offers raw GPU machines at low prices. You can spin up a container or Jupyter notebook on a 4090, A100, or even H100, paying by the hour. For persistent workloads, it supports encrypted volumes and keeps jobs running across sessions.
Unlike true serverless platforms, you’re responsible for job lifecycle, retries, and cleaning up idle instances. RunPod is cheap, flexible, and infrastructure-heavy.
Koyeb recently added GPU support to its serverless container platform. It's positioned toward lightweight web services that occasionally require GPU acceleration.
Pros:
- Simple deployment model with GitHub integration
- L4 and V100 GPU support in private preview
- Integrated HTTP routing and autoscaling
Cons:
- GPU runtime is limited and non-persistent
- No orchestration, volume support, or secure isolation
- Lacks visibility and infra-level control
Best for: Web or backend developers deploying basic inference models or GPU-enhanced features in global serverless environments.
Koyeb recently added GPU support as part of its broader serverless platform. Currently in preview, its GPU offering is focused on web apps or inference endpoints needing L4-class performance.
There’s no support yet for long-running training jobs, multi-container orchestration, or microVM isolation.
Choosing the right serverless GPU provider in 2025 depends on what you’re building and how much control you need. The market has grown past basic batch jobs, teams now demand secure execution, orchestration, and flexible GPU runtime environments.
If you need a lightweight way to run public models or quick batch jobs, tools like Replicate and Modal still serve a purpose. But if you’re running anything mission-critical, LLM inference, fine-tuning pipelines, and a platform that takes care of your entire engineering lifecycle, Northflank is the way to go. Especially given its most affordable pricing on GPUs.
No matter what your use case is, whether you're evaluating the top serverless GPU services, comparing pricing across A100 and H100 instances, or searching for the best serverless GPU platforms for inference pipelines, this guide should give you a technically sound starting point.
What is the cheapest serverless GPU option for A100s or H100s?
Northflank has, by far, the competitive pricing for A100 and H100 GPUs (and across all types of GPUs). H100s are $2.74/hour and A100s are $1.42/hour.
Which serverless GPU provider is best for inference APIs?
Northflank and Baseten both support GPU-backed inference APIs. Northflank is better for long-lived, autoscaling APIs with persistent volumes and job queues. Baseten is simpler but more limited.
Are there serverless GPU platforms that let me bring my own cloud (BYOC)?
Northflank supports BYOC and allows you to deploy GPU workloads into your own VPC on AWS, GCP, or Azure. This gives teams full infrastructure control, network visibility, and integration flexibility, all while keeping the developer experience consistent.
Do any serverless GPU providers support GPU+CPU coordination for hybrid workloads?
Only Northflank offers true multi-service orchestration where GPU and CPU containers can work together, which is critical for agentic workflows and multi-modal inference.


