

H100 vs A100 comparison: Best GPU for LLMs, vision models, and scalable training
When you're training deep learning models at scale, the GPU you choose affects everything from speed to cost. NVIDIA’s A100 and H100 are two of the most capable options available, built for serious workloads but designed for different problems.
The A100 has become the default for large-scale training and inference. It offers stable performance, strong framework support, and efficient throughput for a wide range of models. The H100 is built for what comes next. Its architecture is tuned for transformers, FP8 precision, and high-throughput training at scale.
If you’re running these workloads in the cloud, the difference matters. At Nothflank, we see teams using A100s to power production inference and others pushing H100s to train massive LLMs. This guide breaks down the differences, starting with a quick side-by-side comparison.
If you're short on time, here’s a quick look at how the A100 and H100 compare side by side.
| Feature | A100 | H100 |
|---|---|---|
| Architecture | Ampere | Hopper |
| Process node | 7nm | TSMC 4N |
| Tensor cores | 3rd Gen | 4th Gen + Transformer Engine |
| Memory type | HBM2e | HBM3 |
| Max memory bandwidth | ~2.0 TB/s | ~3.35 TB/s |
| Precision support | FP64, TF32, BF16, FP16, INT8 | FP64, TF32, BF16, FP16, INT8, FP8 |
| Transformer acceleration | No | Yes (Transformer Engine) |
| Multi-instance GPU (MIG) | First Generation (7 instances) | Second Generation (7 improved slices) |
| Hardware video decode | JPEG + NVDEC acceleration | Included but not explicitly highlighted |
| Key use Cases | General AI/ML, CV, inference | LLMs, FP8 training, large-scale HPC |
| Cost on Northflank (July 2025) | 40GB VRAM - $1.42/hr, 80GB VRAM - $1.76/hr | 80GB VRAM - $2.74/hr |
What is Northflank?
Northflank is a full-stack AI cloud platform for building, training, and deploying AI applications, with GPU workloads, APIs, frontends, and databases all running in one place.
Sign up to get started or book a demo to see how it fits your stack.
The A100 has been a core part of modern deep learning infrastructure since it launched. Built on NVIDIA’s Ampere architecture, it powers everything from large-scale training to production inference pipelines. It supports TF32, FP16, and BF16 precision and comes with third-generation Tensor Cores that speed up deep learning operations across a wide range of models.
It uses high-bandwidth HBM2e memory with up to 2 terabytes per second of bandwidth and supports Multi-Instance GPU (MIG), which allows you to split the GPU into isolated slices. This makes it ideal for teams that need flexibility in how they allocate compute resources.
A100s are widely used for deploying inference at scale, and running distributed workloads. If you're working across a range of architectures and need stable, high-throughput compute, the A100 remains a strong, reliable choice.
The H100 introduces a new Hopper architecture designed specifically for the scale and complexity of today’s largest models. With support for FP8 precision and NVIDIA’s Transformer Engine, it enables faster training and better efficiency on LLMs and generative models without requiring major changes to your code.
Its HBM3 memory delivers over 3.3 terabytes per second of bandwidth, which means faster data movement and better performance under heavy workloads. Fourth-generation Tensor Cores and second-generation MIG support give you even more control over how compute is distributed.
If you're fine-tuning large transformers, or pushing batch sizes and sequence lengths beyond what was previously possible, the H100 is built to meet that demand.
Now that we’ve looked at how the A100 and H100 perform on their own, it’s worth breaking down what actually makes them different. The two GPUs aren’t just built for different generations of hardware; they reflect a shift in how teams train and scale deep learning models. Here's how they stack up across architecture, memory, precision, and deployment.
The A100 is based on the Ampere architecture. It uses third-generation tensor cores that support TF32, FP16, and BF16. That setup works well for most deep learning pipelines. The H100 is built on Hopper and introduces fourth-generation tensor cores along with a transformer engine. That engine brings native FP8 support and dynamically mixes precision during training. If you’re working with large transformers or LLMs, this gives H100 a clear edge in speed and efficiency.
A100 uses HBM2e memory and reaches about 2 TB per second of memory bandwidth. H100 upgrades to HBM3, pushing bandwidth beyond 3.3 TB per second. That alone can reduce training time on large batch sizes. H100 also bumps NVLink from 600 GB per second (on A100) to 900 GB per second, which is a major win for multi-GPU training and model parallelism.
While A100 can handle FP16 and BF16 well, it doesn’t support FP8. H100 does, and that opens up a new level of compute density. It means you can push larger models or use larger batch sizes without running into memory ceilings. And because the transformer engine handles the precision scaling internally, you don’t need to make low-level changes to your code.
Both cards are available in PCIe and SXM form factors, but there’s a big difference in how they run. PCIe is what you’ll see in most cloud platforms. SXM is typically for high-density setups and offers higher power limits, better thermal efficiency, and full NVLink support. H100 in SXM form can reach up to 700 watts, while PCIe versions are capped lower.
Both GPUs run the standard CUDA stack, but H100’s features rely on the latest versions of CUDA and cuDNN. If you're still on older drivers or toolchains, A100 will likely be more forgiving. To get the most out of H100, especially FP8 support and the transformer engine, you need to be on CUDA 12 and above.
A100 is still widely used and highly capable, especially for computer vision models, reinforcement learning, and vision model training. H100 is where teams are going for large-scale language models, diffusion models, or anything that hits a memory or throughput wall on A100. It’s not just about being faster; it unlocks workflows that weren’t practical before.
When scaled across multi-GPU clusters, the H100 delivers up to 30× more performance than the A100 in real-world workloads like GPT-3 training, inference, and genomics.
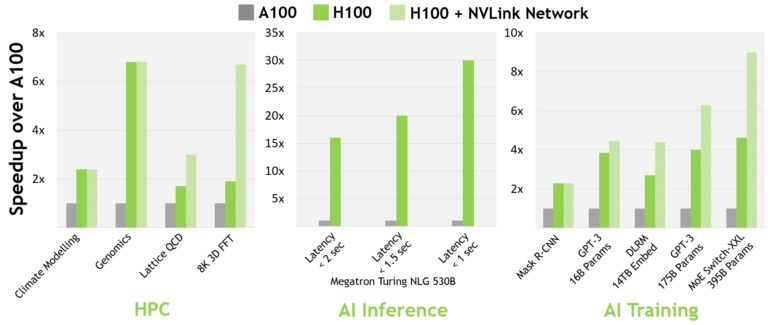 H100 offers up to 30× speedup over A100 (source).
H100 offers up to 30× speedup over A100 (source).
After comparing each GPU, the next question is usually pricing. not the sticker price, but what it actually costs to run them in the cloud.
Northflank offers both A100 and H100 GPUs at affordable prices. no commitments, and you have full control over how you scale. Here's what that looks like today: (July 2025)
- A100 40GB: $1.42/hr
- A100 80GB: $1.76/hr
- H100 80 GB: $2.74/hr
The A100 is still the most cost-efficient option for stable training runs, fine-tuning, and production inference. It’s fast, reliable, and easy to scale across dozens of instances.
The H100 comes in when you’re fine-tuning at the frontier. Large batch sizes, FP8-heavy workloads, and transformer-based models benefit from the extra memory bandwidth and throughput. Even though it costs more per hour, it can bring total training time down, which often means better value in the long run.
By now, you’ve seen how the A100 handles a broad range of workloads and how the H100 pushes the limits on model size and training speed. Both are powerful, but they serve different needs. The right choice depends on what you're running, how you scale, and where performance matters most. Here’s a breakdown to help you decide.
| Use Case | Recommended GPU |
|---|---|
| Training vision models | A100 |
| Fine-tuning transformer LLMs | H100 |
| Mixed precision Inference | A100 |
| FP8 optimized Fine-tuning | H100 |
| Multi-tenant GPU usage | Both (MIG support) |
| Budget-conscious deployments | A100 |
| Maximum performance at scale | H100 |
The A100 remains a reliable choice for a wide range of workloads. It’s proven, efficient, and still powers production at scale. But if you're working with transformer-heavy models, large-scale LLMs, or need the speed to shorten training cycles, the H100 brings a different level of performance.
This guide broke down the architectural differences, performance benchmarks, and real-world cost of each GPU. If you're ready to test them in your stack, Northflank gives you access to both. You can launch cloud GPU instances in minutes or book a quick demo to see how it fits your workflow.


