

Claude Code: Rate limits, pricing, and alternatives
Claude Code can get expensive at scale. The alternative is self-hosting open-source models on Northflank. You can get started here, by deploying models like Qwen3 and DeepSeek.
Claude Code is powerful, but closed models come with two constraints: rate limits and cost ceilings.
Claude's new pricing and rate limits restrict usage at key moments, especially for high-throughput apps and AI-native products.
There's a better way: self-host open-source models with Northflank. You get lower cost, no rate limits, and full control over performance.
Claude is Anthropic’s family of AI models, known for their conversational ability, large context windows, and safety-oriented alignment. Claude 4 Opus, Sonnet, and Haiku are positioned as general-purpose assistants for reasoning, coding, and text generation.
Claude Code, launched as part of Anthropic's platform, is an agentic coding assistant capable of reading code, editing files, performing tests, and pushing GitHub commits. It quickly became popular among developers for its ability to handle extended coding sessions and complex development tasks.
Many teams use Claude Code for LLM-generated code, but they’re now running into a wall: rate limits.
- Free Plan: Limited daily messages (varies by demand)
- Pro Plan: $20/month - approximately 45 messages every 5 hours
- Max Plan: Two tiers at $100/month (5x Pro usage) and $200/month (20x Pro usage)
- Team Plan: $30/user/month (minimum 5 users)
- Enterprise Plan: Custom pricing starting around $50,000 annually
- Claude 4 Opus: $15.00 input / $75.00 output
- Claude 4 Sonnet: $3.00 input / $15.00 output
- Claude 3.5 Haiku: $0.80 input / $4.00 output
Claude Code calls are heavier than chat. They include large system instructions, full file contexts, long outputs, and often multiple steps per user interaction. Which means:
- You burn through tokens faster
- Subscription tiers don’t save you on programmatic use
- You still pay standard per-token API rates on top of any subscription fees
Even at $200/month, you're just buying more throttled access, not control. For teams running agents, IDEs, devtools, or anything programmatic, Claude pricing is both expensive and unstable.
Rate limits are restrictions that API providers implement to control request volume within specific timeframes.
Anthropic implements these Claude rate limits for several important reasons:
- Server Resource Management: Preventing any single user from consuming too many computational resources
- Equitable Access: Ensuring fair distribution of API access across all users
- Abuse Prevention: Protecting against malicious activities like scraping or DDoS attacks
- Service Stability: Maintaining overall system performance during peak usage times
Claude API implements several types of rate limits:
- Requests per minute (RPM) - Limits the number of API calls within a 60-second window
- Tokens per minute (TPM) - Caps the total tokens (both input and output) processed within a minute
- Daily token quota - Restricts the total tokens processed within a 24-hour period
API users also face tier-based restrictions, with higher tiers offering more generous limits after meeting spending thresholds.

In a post on X, Anthropic announced that it's introducing new weekly rate limits to paid subscribers after it says a small handful of users abused their privileges and, essentially, ruined it for everyone else.
🚨 The new limits, effective August 28, 2025, include:
- Weekly caps that reset every seven days
- Separate limits for overall usage and Claude Opus 4 specifically
- Max subscribers can purchase additional usage, beyond what the rate limit provides, at standard API rates
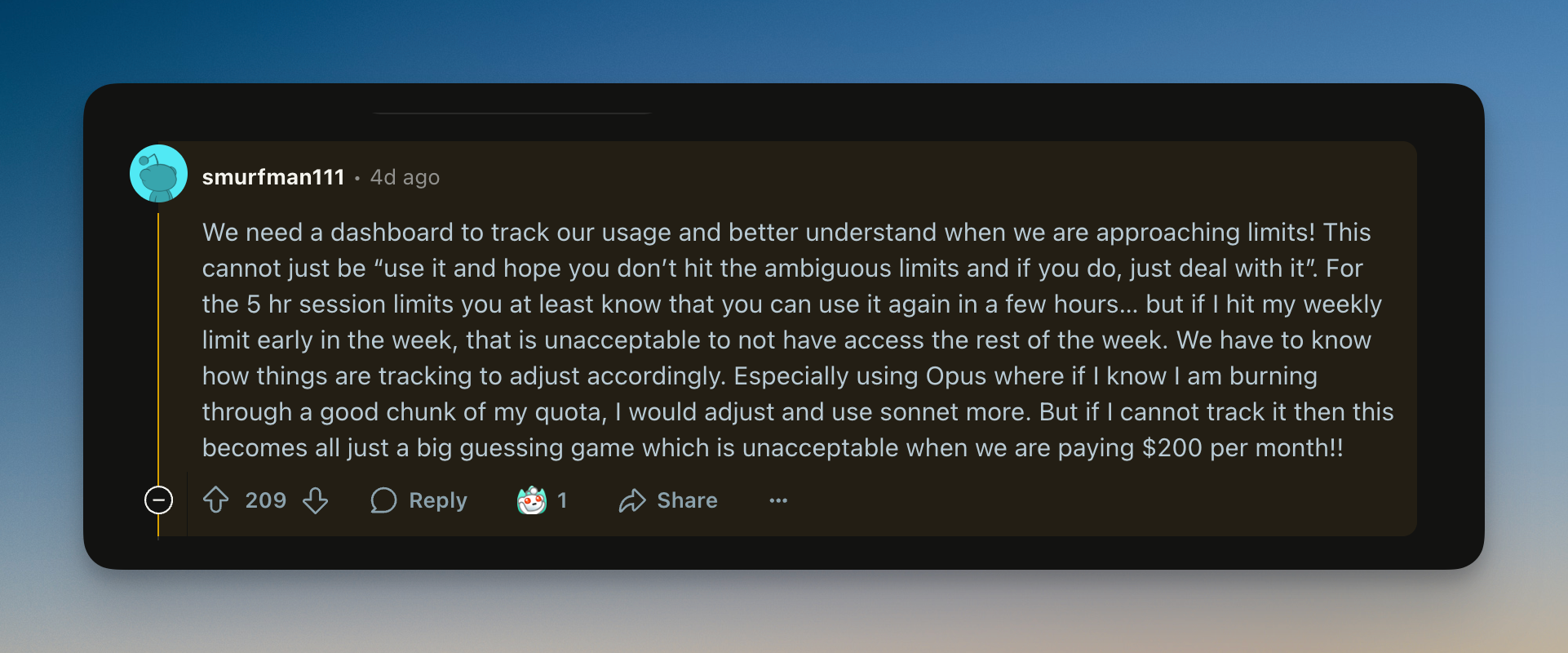
Whether you’re using Claude Code through the web interface or via API, the outcome is the same:
- You don’t control the upper bounds
- Throughput varies based on Anthropic’s internal policies
- You might get full-speed access one moment, then dropped or downgraded the next
This creates major friction for:
- LLM-native devtools that require fast, repeated completions
- Autonomous agents running multi-step reasoning
- Real-time coding assistants that rely on low-latency responses
- Teams scaling prompt workloads across dozens or hundreds of users
The issue isn’t that Claude is too expensive or too slow. It’s that you don’t control it.
Even if you’re paying for Claude Code at enterprise scale, Anthropic can:
- Throttle your usage at unpredictable times
- Impose stricter token limits based on aggregate load
- Prioritize other customers with higher commitments
This makes it difficult to build real-time codegen systems, multi-agent setups, or LLM-native developer tools with guaranteed performance.
More fundamentally, as pointed out here, these rate limits signal a broader issue with the entire closed model ecosystem:
You don’t own the performance. You rent it, and it gets rationed.
Not to mention security implications.
When you send code or context to Claude Code, you're handing sensitive logic, sometimes proprietary codebases or real-time user input, over to a black-box system. You can’t control where the data lands, how long it's retained, or who else might gain access to metadata about your requests. Claude promises privacy, but it's still a third-party API with unknown internal telemetry.
With open models like Qwen3, DeepSeek, LLaMA, and Kimi K2 you can avoid this entire category of limitations.
You choose:
- The exact model you want (code-focused, long-context, parameter count, etc.)
- The GPU it runs on
- The context length
- The batch size
- The latency budget
You can deploy these models using vLLM, Ollama, or with your own custom code, and run them on your own infra with no rate limits and no API surprises.
Northflank supports hosting popular open-source AI models that compete directly with closed-source alternatives. Here's what you can run:
Deepseek Family
- Deepseek R1 - Advanced reasoning model (matches OpenAI o1)
- Deepseek R1 32B - Smaller reasoning model (matches o1-mini)
- Deepseek v3 - General-purpose powerhouse (matches Claude Sonnet 3.5)
Qwen3 Family
- Qwen3 Thinking 235B - Top-tier reasoning (matches Claude Opus 4, GPT-4)
- Qwen3 32B - Versatile mid-size model (matches GPT-4.1)
- Qwen3 30B - Fast and efficient (matches GPT-4o/Gemini Flash)
- Qwen3 Coder - Specialized for programming (matches/exceeds Claude for coding)
Llama 4 Family
- Llama 4 Maverick - Large general model
- Llama 4 Scout - Smaller, faster variant
Coming soon
- Kimi K2 - Next-generation model
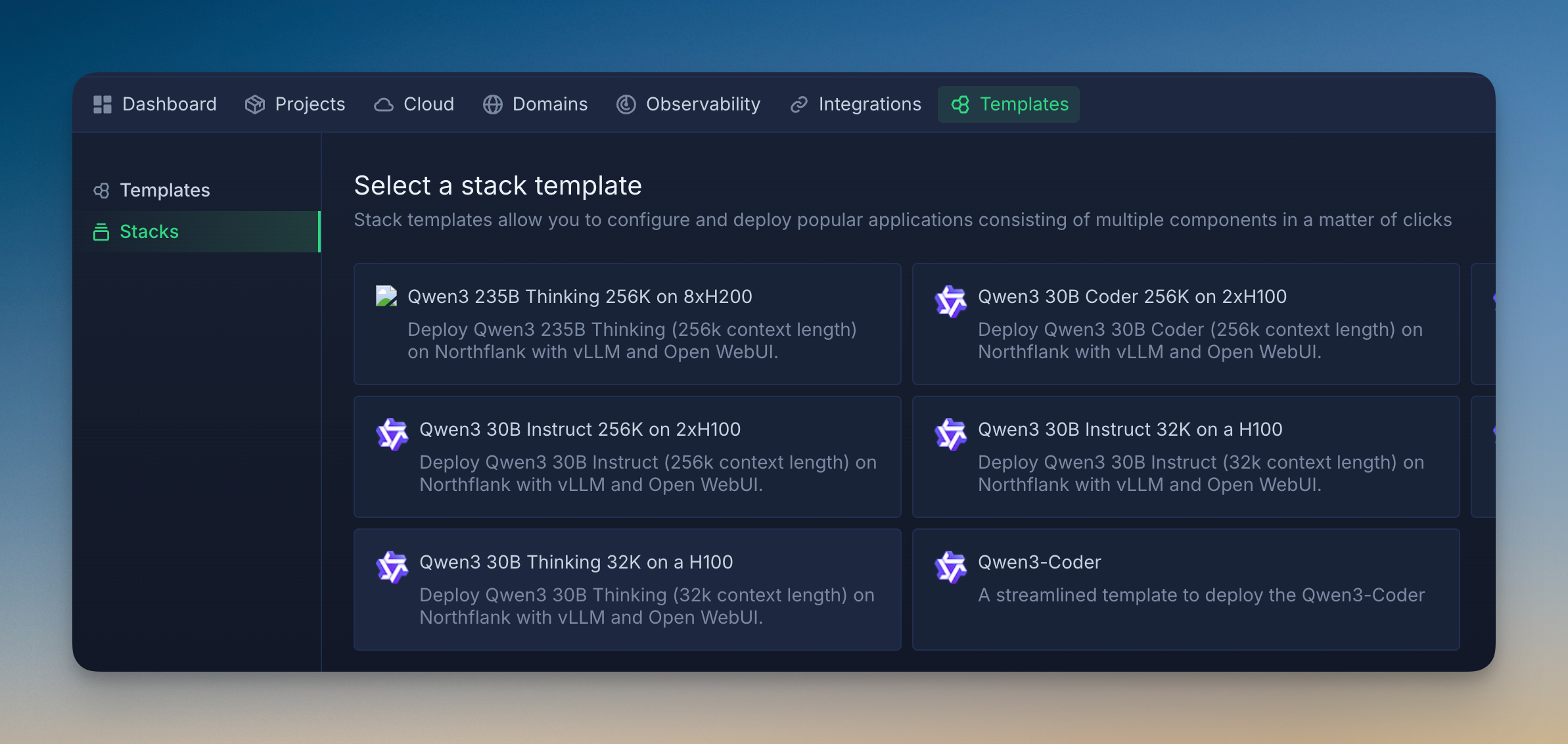
Let’s take self-hosting Deepseek v3 on Northflank, as an example.
- A100 (80GB): $1.76/hour
- H100 (80GB): $2.74/hour
- H200 (141GB): $3.14/hour
- B200 (180GB): $5.87/hour
Let’s walk through Deepseek v3 as an example:
Step 1: Calculate hourly GPU cost
- Requires: 8 × H200 GPUs
- Cost: 8 × $3.14 = $25.12/hour
Step 2: Convert to cost per second
- $25.12 ÷ 3,600 seconds = $0.006978/second
Step 3: Measure processing speeds
- Input tokens: 7,934 tokens/second
- Output tokens: 993 tokens/second
Step 4: Calculate per-token costs
- Input: $0.006978 ÷ 7,934 = $0.0000008795 per token
- Output: $0.006978 ÷ 993 = $0.0000070265 per token
Step 5: Scale to millions
- Input: $0.88 per million tokens
- Output: $7.03 per million tokens
Output tokens are ~8x more expensive because the model generates them much slower (993/second vs 7,934/second). This is why the input/output ratio matters for this use case.
Compared to Claude Sonnet 3.5 ($3 input, $15 output):
- Deepseek v3 is 3.4x cheaper for input
- Deepseek v3 is 2.1x cheaper for output
Step 1: Choose your model
- For general use: Deepseek v3 (matches Claude Sonnet 3.5)
- For reasoning: Deepseek R1 or Qwen3 Thinking
- For coding: Qwen3 Coder
- For speed: Qwen3 30B variants
Step 2: Pick your deployment method
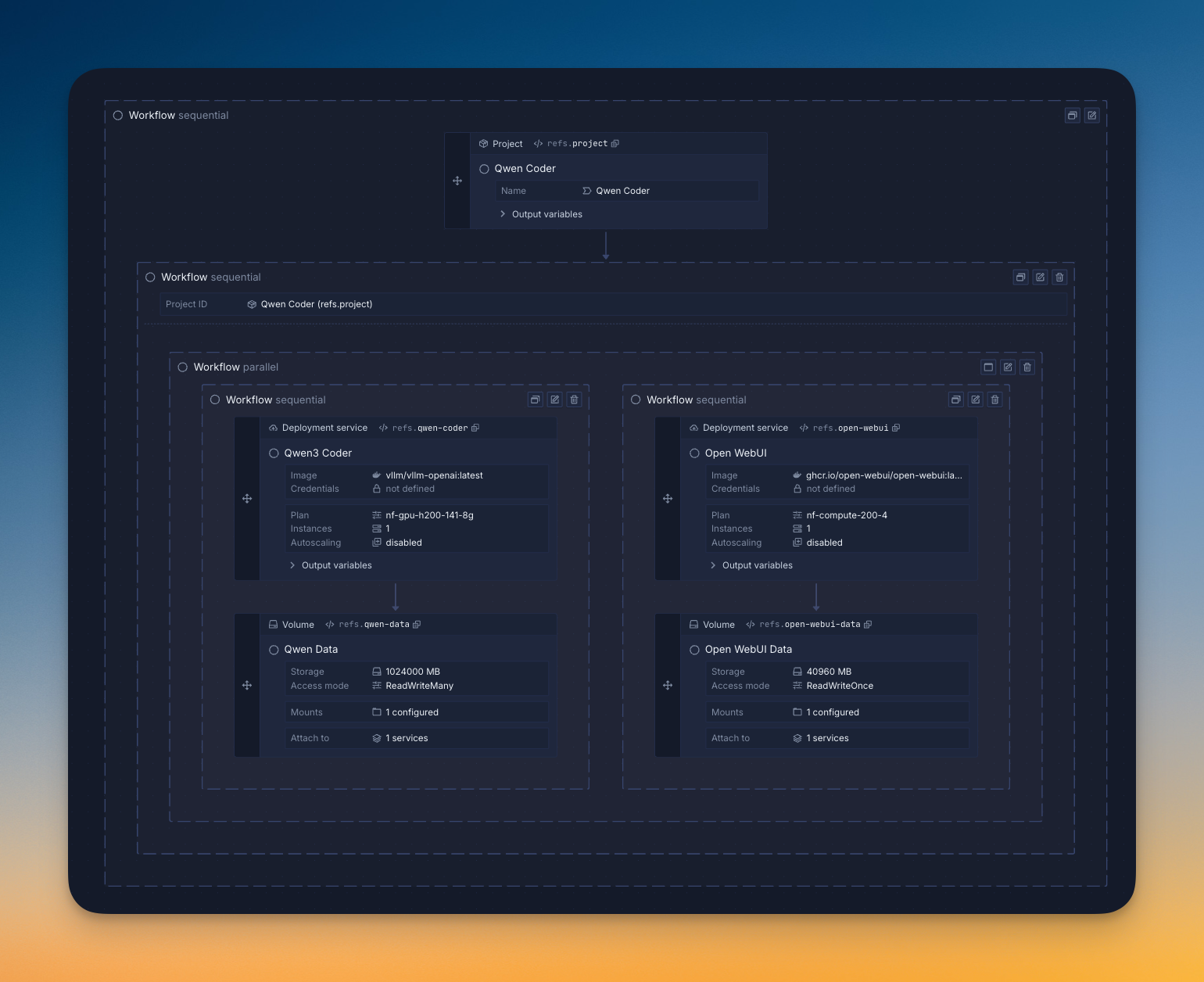
- One-click templates: Deploy popular models with pre-configured settings in minutes
- Manual setup: Full control over model parameters and GPU selection
- Bring Your Own Cloud: Use your existing AWS/GCP/Azure account for maximum control
Step 3: Select your GPU
- Small models (< 50GB): 1-2 GPUs
- Medium models (50-100GB): 2-4 GPUs
- Large models (100GB+): 8+ GPUs
- Northflank offers A100, H100, H200, and B200 options
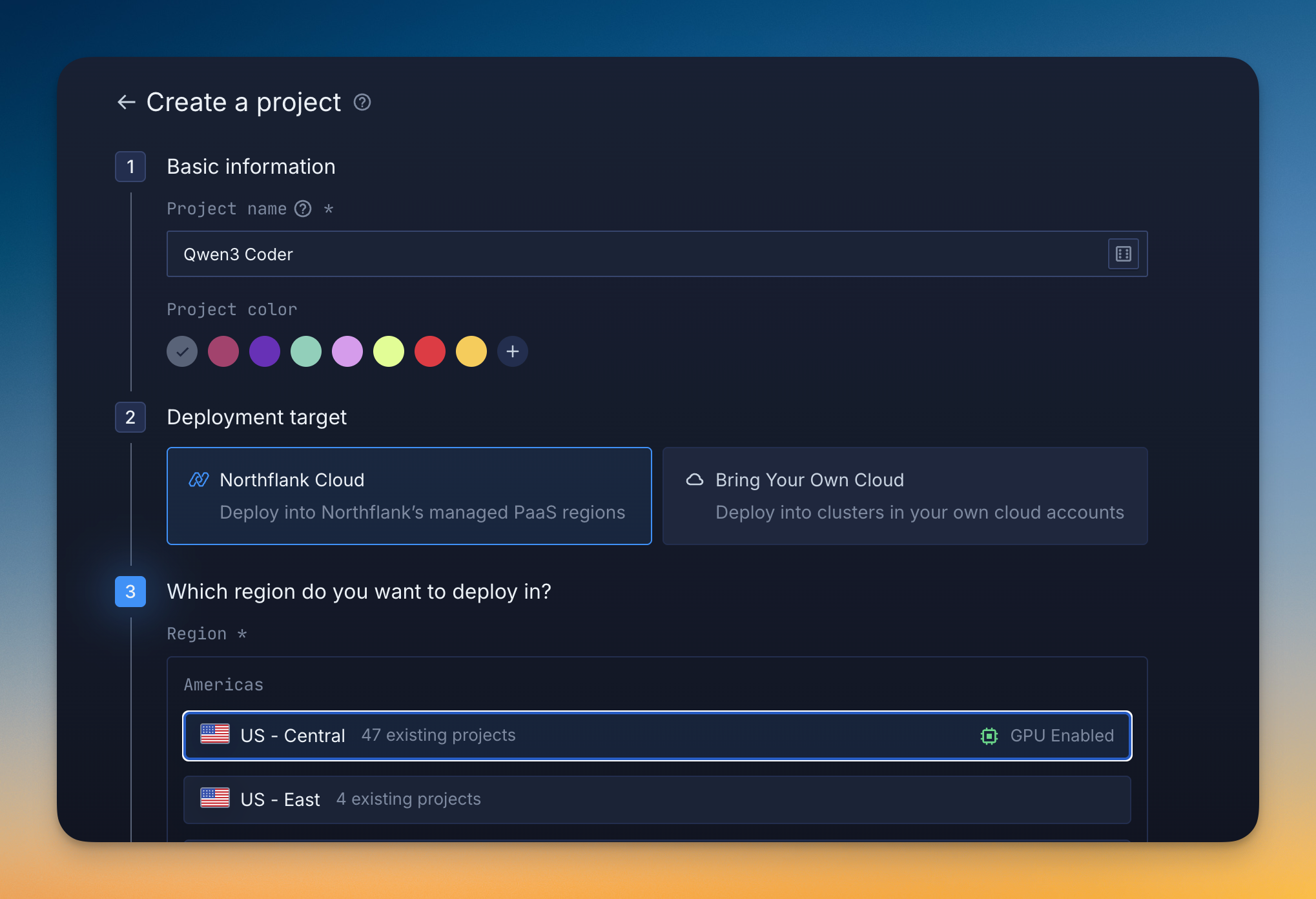
- Sign up for a Northflank account
- Create a GPU-enabled project in your preferred region
- Deploy from a template or create a custom vLLM service
- Access via API using OpenAI-compatible endpoints
Most models are serving requests within 30 minutes of starting deployment.
- A Northflank account (free to create)
- Basic understanding of APIs (for integration)
- Your use case requirements (tokens/month, latency needs)
Ready to cut your AI costs and have complete control over models? Sign up for Northflank and deploy your first open source model today. Our templates make it as easy as clicking "deploy," no GPU expertise required.
For detailed guides on specific models, reach out to the Northflank team.


