

Top 7 Hyperbolic AI alternatives for GPU workloads in 2026
Hyperbolic AI alternatives provide different approaches to deploying GPU workloads, from specialized inference services to comprehensive infrastructure platforms.
If you need multi-cloud deployment, complete application stack management, or specific compliance requirements, understanding your options helps you choose the platform that matches your technical and operational needs.
See this quick summary of the top 7 Hyperbolic AI alternatives
-
Northflank - Deploy GPU workloads alongside your entire application stack (databases, APIs, jobs, CI/CD) across AWS, GCP, Azure, Oracle Cloud, Civo, or bare-metal from one platform.
Northflank stands out as a unified cloud platform where you deploy GPU workloads alongside your databases, APIs, and CI/CD pipelines, all from one interface with Git-based workflows.
With true BYOC (Bring Your Own Cloud) support across AWS, GCP, Azure, Oracle Cloud, Civo, and bare-metal, you can run GPU capabilities as part of your complete application stack rather than managing separate platforms for compute, hosting, and deployment.
-
Together AI - Access 200+ open-source models through serverless inference APIs with fine-tuning capabilities
-
Fireworks AI - Specialized inference engine with low-latency serving and multi-modal model support
-
CoreWeave - Kubernetes-native GPU infrastructure for training and inference at scale
-
Lambda Labs - 1-Click Clusters designed for academic researchers and AI teams
-
RunPod - Community and Secure Cloud options across 30+ global regions
-
Replicate - Container-based model deployment for prototyping and production
-
AWS/GCP/Azure - Traditional hyperscalers with GPU instances integrated into broader cloud ecosystems
Before examining specific platforms, understanding evaluation criteria helps you match alternatives to your requirements.
-
Infrastructure control and deployment flexibility:
Can you deploy in your own cloud accounts? Some platforms lock you into their infrastructure, while others support deploying in your AWS, GCP, or Azure environments. BYOC (Bring Your Own Cloud) capabilities matter for teams with existing cloud commitments, compliance requirements, or cost management needs.
-
Complete stack deployment versus specialized GPU access:
Do you need just GPU compute, or are you deploying complete applications? Platforms differ in scope; some focus exclusively on GPU provisioning and model serving, while others integrate GPU workloads with databases, application hosting, and deployment automation.
-
Developer workflow integration:
Does the platform support your development process? Git integration, automated builds, preview environments, and CI/CD capabilities affect how quickly teams ship changes. Some platforms require external tools for these workflows, while others provide them natively.
-
Observability and cost transparency:
Can you monitor GPU utilization, track costs across providers, and debug performance issues? Built-in logging, metrics, and cost analytics reduce the need for separate monitoring tools and help identify optimization opportunities.
-
Security and compliance capabilities:
Does your use case require specific security features? Private networking, VPC deployment, audit logs, RBAC, and compliance certifications (SOC 2, HIPAA) become essential for regulated industries or enterprise environments.
We'll review the top Hyperbolic AI alternatives based on infrastructure control, stack integration, developer workflows, and deployment flexibility to help your team make an informed decision.
Northflank approaches GPU deployment differently than specialized providers by treating GPU workloads as components within your complete application architecture rather than isolated resources.
The platform lets you deploy GPU services alongside managed databases (PostgreSQL with pgvector, MySQL, MongoDB, Redis), web applications, APIs, background jobs, and scheduled tasks.
When building a RAG application, for example, you deploy your Next.js frontend, FastAPI backend, PostgreSQL database with vector extensions, and GPU-powered inference service from the same Git repository using the same workflow.
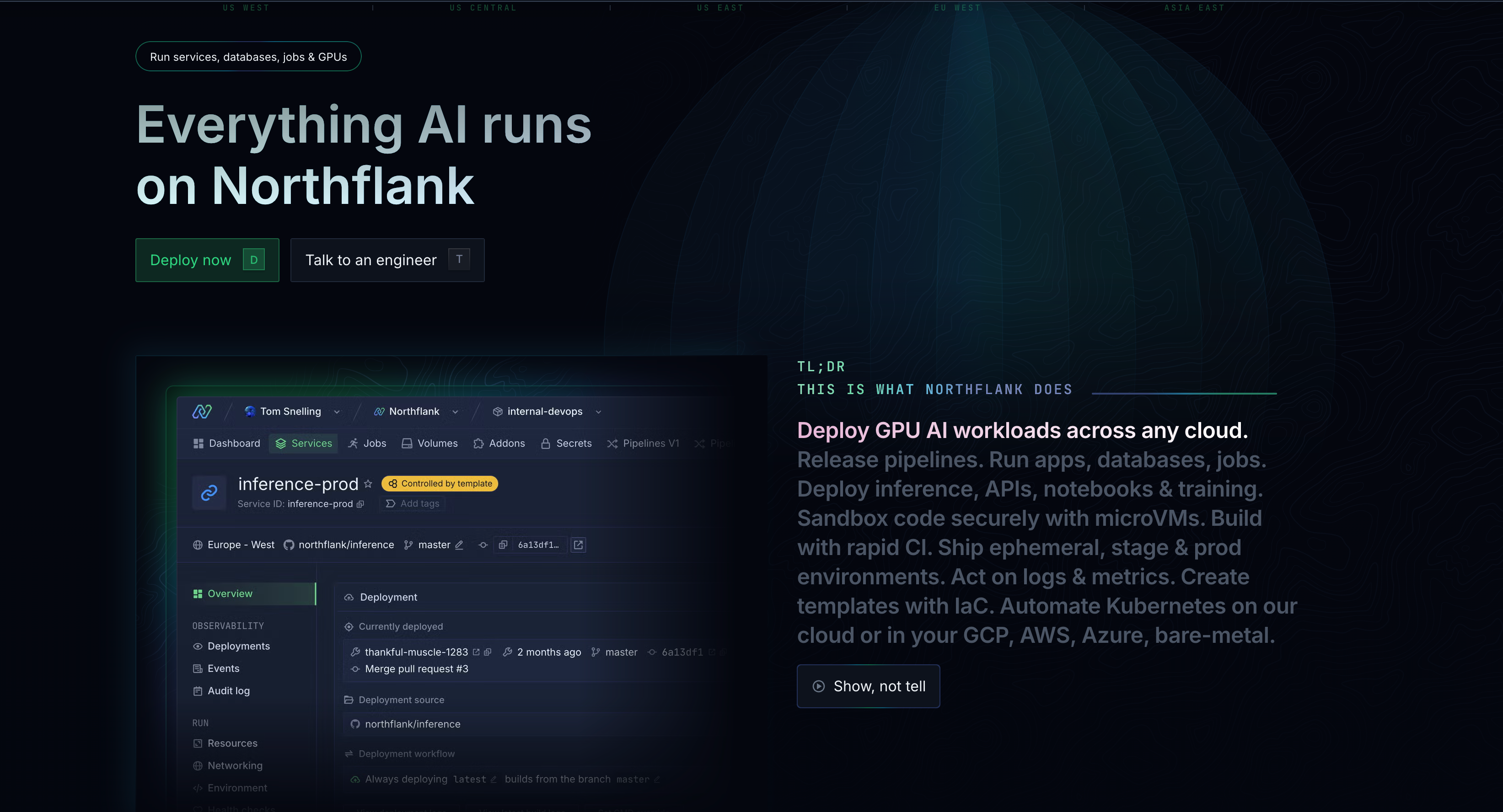
Key capabilities of Northflank for teams building AI applications
- Multi-cloud deployment: Works across AWS, GCP, Azure, Oracle Cloud, Civo, and bare-metal without vendor lock-in. You can deploy on Northflank's managed cloud or connect your own cloud accounts (BYOC) to maintain existing relationships and billing structures. The platform provides access to 600 regions through this multi-cloud approach.
- Git-based deployments: Connect to GitHub, GitLab, or Bitbucket repositories. Each commit triggers automated builds and deployments. Preview environments automatically spin up for pull requests, giving you isolated testing environments before merging changes. This workflow applies to your entire stack, including GPU workloads.
- Built-in observability: Includes real-time log tailing with filtering and search, performance metrics for GPU utilization, memory usage, network traffic, and storage. Cost analytics show spending across different providers. Alerts integrate with Slack, email, or webhooks. These capabilities work without configuring separate monitoring tools.
- Security features: Include private networking between services, VPC support, role-based access controls, audit logs, and SAML SSO. You can deploy in your own Kubernetes clusters (EKS, GKE, AKS) for maximum control.
- GPU options on Northflank: The platform supports NVIDIA B200, H200, H100, A100, L4, L40S, and other GPU types across multiple cloud providers. GPU time-slicing and NVIDIA MIG let you run multiple independent workloads on provisioned GPUs to optimize resource utilization
Northflank’s pricing structure
Sandbox tier
- Free resources to test workloads
- 2 free services, 2 free databases, 2 free cron jobs
- Always-on compute with no sleeping
Pay-as-you-go
- Per-second billing for compute (CPU and GPU), memory, and storage
- No seat-based pricing or commitments
- Deploy on Northflank's managed cloud (6+ regions) or bring your own cloud (600 BYOC regions across AWS, GCP, Azure, Civo)
- GPU pricing: NVIDIA A100 40GB at $1.42/hour, A100 80GB at $1.76/hour, H100 at $2.74/hour, H200 at $3.14/hour, B200 at $5.87/hour
- Bulk discounts available for larger commitments
Enterprise
- Custom requirements with SLAs and dedicated support
- Invoice-based billing with volume discounts
- Hybrid cloud deployment across AWS, GCP, Azure
- Run in your own VPC with managed control plane
- Secure runtime and on-prem deployments
- Audit logs, Global back-ups and HA/DR
- 24/7 support and FDE onboarding
Use the Northflank pricing calculator for exact cost estimates based on your specific requirements, and see the pricing page for more details
When to choose Northflank over Hyperbolic AI alternatives
Northflank fits teams building complete AI products rather than just calling inference APIs. If your application includes a frontend, backend, database, and GPU-powered features, managing these components on separate platforms creates coordination overhead.
The platform works for teams with existing cloud commitments who need to use their AWS, GCP, or Azure accounts while gaining better GPU management and unified infrastructure control. Companies requiring specific data residency, compliance certifications, or VPC deployment also benefit from BYOC capabilities.
Development teams wanting Git-to-production workflows, preview environments for every PR, and integrated CI/CD find Northflank reduces context switching between tools. The unified dashboard covers deployment, monitoring, and cost management across your entire stack.
Try Northflank free | Request your GPU cluster | View documentation | Explore GPU workloads
Together AI provides serverless access to over 200 open-source language, vision, and embedding models through API endpoints. The platform handles infrastructure scaling automatically, letting developers focus on building applications rather than managing GPU clusters.

Key features
- Model library and fine-tuning: Includes LLaMA, Mistral, BLOOM, Stable Diffusion with fine-tuning and Weights & Biases integration.
- OpenAI-compatible endpoints: Switch from proprietary APIs to open-source models by changing a few lines of code.
- GPU infrastructure: 10K+ GPUs with InfiniBand networking for distributed training and automatic job scheduling.
Best for: Teams focused on model experimentation who need access to hundreds of pre-configured models without managing infrastructure, and applications requiring serverless autoscaling for variable traffic.
Fireworks AI specializes in serving open-source models through optimized inference infrastructure with proprietary FireAttention CUDA kernels.
Key features
- Multi-LoRA serving: Deploy multiple fine-tuned variants of a model without separate hosting.
- Multi-modal support: Text, image, and audio models with FireLLaVA for processing text and visual inputs.
- Compliance and security: HIPAA and SOC2 certifications with VPC and VPN connectivity for private networking.
Best for: Teams needing optimized model serving with low latency, though BYOC deployment requires enterprise contracts and the platform doesn't support complete application deployment.
CoreWeave provides GPU infrastructure designed around Kubernetes orchestration for AI training and inference workloads, operating data centers with NVIDIA H100, H200, GB200 NVL72, and enterprise GPUs.

Key features
- Bare-metal Kubernetes: Performance without virtualization overhead with Mission Control software for automated operations.
- InfiniBand networking: NVIDIA Quantum-2 for high-bandwidth, low-latency connections between GPU nodes.
- Reserved capacity: Guaranteed GPU availability for production workloads with extended training or continuous inference.
Best for: AI labs and research organizations training foundation models with Kubernetes expertise who need large-scale GPU clusters with specialized networking.
Lambda Labs targets academic researchers and AI teams through pre-configured GPU access designed for machine learning workflows.

Key features
- 1-Click Clusters: Interconnected GPUs with pre-installed PyTorch, TensorFlow, CUDA, and Jupyter.
- GPU options: NVIDIA HGX B200, H100, A100, and GH200 instances with Lambda Private Cloud available.
- InfiniBand networking: NVIDIA Quantum-2 for distributed training across multiple GPU nodes.
Best for: University research groups and academic projects who need ML-ready environments without infrastructure setup complexity, though teams need separate solutions for databases and production infrastructure management.
RunPod offers GPU deployment across 30+ geographic regions through Secure Cloud (tier-3/tier-4 data centers) and Community Cloud (individual GPU providers).

Key features
- Serverless GPU: Automatic scaling and idle shutdown for variable workloads with pay-per-use pricing.
- Custom containers: Docker containers for exact runtime environments or pre-built templates for common frameworks.
- Automation tools: CLI and API for integration with CI/CD pipelines and programmatic deployment.
Best for: Teams needing distributed deployment options, though Community Cloud may have lower uptime guarantees and the platform focuses on GPU compute without integrated databases or comprehensive development workflows.
Replicate enables model deployment through containerized infrastructure, letting developers package models with dependencies and serve them as HTTP APIs.

Key features
- Container workflow: Push code and weights for automatic building, GPU allocation, and endpoint exposure.
- Public model library: Pre-deployed models for immediate use covering image generation, language processing, and speech recognition.
- Automatic scaling: Resource adjustment based on request volume and scales to zero when not in use.
Best for: Solo developers and small teams prototyping and experimenting without dedicated DevOps resources, though building production applications requires additional platforms for databases and application logic.
Traditional cloud providers offer GPU instances as part of comprehensive cloud platforms with deep integration across storage, networking, security, and managed services.
AWS capabilities: P5 instances with H100 GPUs, SageMaker, and integration with S3, Lambda, and RDS.
GCP capabilities: A2 and A3 instances with A100/H100 GPUs, TPU alternatives, Vertex AI, and BigQuery integration.
Azure capabilities: NC-series with NVIDIA GPUs, Azure ML integration, and Microsoft ecosystem connectivity.
Best for: Enterprises with existing cloud investments who need GPU capabilities within current infrastructure and established compliance frameworks, though GPU availability can be constrained during high-demand periods and pricing structures include multiple fees.
Use the comparison table above to match your deployment needs, existing infrastructure, and application architecture with the platform that addresses your specific requirements.
| Alternative | Best for | Key advantages | GPU options | Best for use case |
|---|---|---|---|---|
| Northflank | Teams building complete AI applications across multiple clouds | Multi-cloud deployment with unified platform for GPUs, databases, apps, jobs, and CI/CD; BYOC (Bring Your Own Cloud) support; Git-based workflows | B200, H200, H100, A100, L4, L40S, GH200 and more GPU types | Products with frontend, backend, database, and AI features needing unified deployment |
| Together AI | Serverless inference and model fine-tuning | 200+ models; fine-tuning capabilities; OpenAI-compatible endpoints | Access through managed service | Model experimentation, testing, and prototyping without infrastructure management |
| Fireworks AI | Low-latency inference with multi-modal support | Optimized inference engine; multi-LoRA serving; HIPAA/SOC2 certified | Access through managed service | Optimized model serving with compliance requirements |
| CoreWeave | Kubernetes-native training and inference at scale | Bare-metal Kubernetes; InfiniBand networking; reserved capacity | H100, H200, GB200 NVL72, RTX PRO 6000 | Organizations needing fine-grained workload management and container orchestration control |
| Lambda Labs | Academic researchers and ML teams | Pre-configured ML environments; 1-Click Clusters; Jupyter notebooks | HGX B200, H100, A100, GH200 | Research teams and academic projects focused on experimentation over production |
| RunPod | Distributed deployment across many regions | 30+ regions; Community and Secure Cloud; serverless option | Various NVIDIA GPUs | Teams needing geographic distribution with flexible deployment options |
| Replicate | Container-based model deployment | Public model library; automatic scaling; developer-friendly API | Access through managed service | Solo developers and small teams prototyping without DevOps resources |
| AWS/GCP/Azure | Organizations with existing cloud infrastructure | Deep service integration; global regions; compliance certifications | H100, A100, various NVIDIA GPUs | Enterprises with existing cloud investments and established compliance requirements |
Hyperbolic AI alternatives provide different approaches to GPU workloads based on your specific requirements. Specialized inference platforms focus on model serving, Kubernetes-native solutions offer container orchestration control, and comprehensive platforms address complete application deployment.
Northflank stands out by treating GPU workloads as components within your full application stack rather than isolated resources. Deploy your databases, APIs, background jobs, and GPU services from the same Git repository using unified workflows across AWS, GCP, Azure, Oracle Cloud, Civo, or bare-metal.
Start by creating a Northflank account to test GPU workloads alongside your application infrastructure, or request your GPU cluster to discuss specific requirements. Learn more about GPU workloads on Northflank, explore available GPU instances, or review the documentation for implementation details.

