

Top 7 Fluidstack alternatives in 2026
Fluidstack offers enterprise-grade GPU infrastructure for large-scale AI workloads, but you might need an alternative that provides more transparent pricing, developer-friendly workflows, or full-stack application support.
This guide helps you find the right GPU cloud platform based on your team's specific requirements, from self-service access and infrastructure control to a complete development environment beyond raw compute.
If you're evaluating Fluidstack alternatives, here's what you need to know:
-
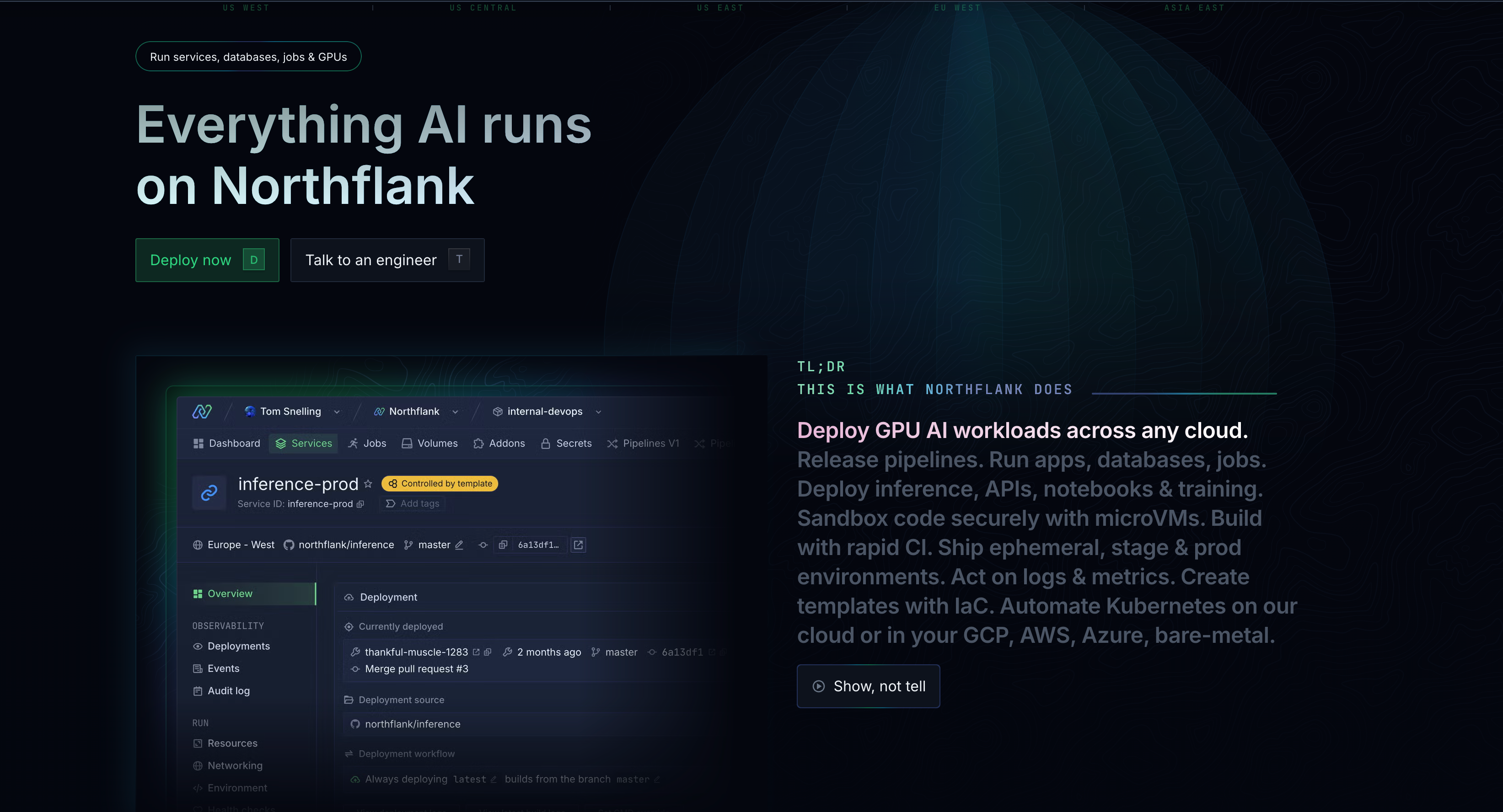
Northflank is a unified cloud platform that supports both GPU and CPU workloads, providing access to H100, H200, B200, A100, L4, and more alongside Git-based CI/CD, databases, APIs, BYOC (Bring Your Own Cloud) deployment, and more modern DevOps features.
You can deploy in your own cloud (AWS/GCP/Azure/Oracle/Civo/bare-metal) or use Northflank's managed infrastructure with transparent per-second billing from $2.74/hour for H100s. You can request GPU clusters directly or start with the free sandbox tier. Best for teams building complete AI applications who need a platform that handles their entire stack.
-
RunPod provides on-demand GPU access with serverless capabilities across Community Cloud and Secure Cloud tiers.
-
Lambda Labs offers GPU infrastructure with pre-configured ML stacks and 1-Click Clusters.
-
Vast.ai operates a marketplace model connecting you with distributed GPU providers.
-
Together AI specializes in serving open-source models through managed inference endpoints.
-
TensorDock focuses on marketplace-based GPU access with VM control.
-
Modal provides serverless compute for Python-based ML workflows.
When evaluating GPU cloud platforms, the right choice depends on how you actually build and deploy AI applications, not just access to hardware. Consider these criteria:
- GPU availability and variety - Access to current GPU models including H100, H200, B200, A100, and L4 cards with availability that matches your timeline. Your team shouldn't wait months for hardware access when you're ready to scale.
- Pricing transparency - Hidden fees for data transfer, storage, or support can multiply your actual costs well beyond advertised GPU rates. Platforms with per-second billing and bundled resources give you predictable expenses.
- Infrastructure control - Can you deploy in your own cloud account? Do you have access to your VPC, networking, and security configurations? Teams working with sensitive data or strict compliance requirements need this level of control.
- Development workflow integration - Git-based deployments, automated CI/CD pipelines, preview environments, and rollback capabilities should feel native to the platform, not bolted on as afterthoughts.
- Full-stack capabilities - For teams building production applications, you need more than GPU compute. Look for platforms that support databases, APIs, background jobs, and observability tools alongside your GPU workloads.
- Scalability options - From one GPU for prototyping to hundreds for production training, the platform should accommodate teams at any stage without forcing you into massive cluster commitments.
- Support and compliance - Production AI workloads require responsive support, security certifications (SOC 2, ISO 27001), and compliance capabilities. Evaluate SLAs and whether you get direct access to technical experts.
We've evaluated the following alternatives based on deployment flexibility, developer experience, and scalability to help you find the best fit for your requirements.
Northflank is a unified cloud platform combining GPU compute with complete infrastructure management and multi-cloud flexibility. Built for teams needing more than raw GPU access, Northflank lets you deploy your entire stack, including GPU workloads, databases, applications, APIs, background jobs, and CI/CD pipelines, across multiple clouds from a single platform.
Key features
- Multi-cloud GPU deployment - Deploy GPU workloads on AWS, GCP, Azure, Oracle Cloud, Civo, or bare-metal from a unified platform. Choose from 6+ cloud regions or 600 BYOC regions without vendor lock-in. Run on Northflank's managed cloud or bring your own cloud account (BYOC) to maintain existing cloud relationships and billing.
- Transparent, predictable pricing - Simple usage-based pricing with per-second billing for CPU, GPU, memory, and storage. No hidden fees for networking, monitoring, or data transfer. Compare costs across providers in real-time and optimize spending with built-in cost analytics.
- Unified infrastructure platform - Deploy GPU compute alongside managed databases (PostgreSQL, MySQL, MongoDB, Redis), applications, APIs, background jobs, and CI/CD pipelines on the same platform. Create complete environments with GPUs and supporting infrastructure together.
- Developer-first workflows - Git-based deployments with automatic builds on every commit. Preview environments for pull requests to test changes safely. Connect locally using Northflank CLI without exposing infrastructure publicly. Support for custom Docker containers and popular ML frameworks.
- Built-in observability - Real-time log tailing with filtering and search. Performance metrics for GPU utilization, memory, network, and storage displayed in intuitive dashboards. Configure alerts via Slack, email, or webhooks.
- Enterprise-ready security - Private networking between services without complex VPC configurations. TLS/SSL encryption enabled by default. Fine-grained role-based access controls. Deploy in your own Kubernetes clusters (EKS, GKE, AKS) for maximum control. 24/7 enterprise support.
- Flexible GPU options - Access NVIDIA A100, H100, H200, B200, L4, L40S, and other GPU types across multiple cloud providers. Scale from single GPUs for development to multi-GPU instances for training.
Pricing
Sandbox tier
- Free resources to test workloads
- 2 free services, 2 free databases, 2 free cron jobs
- Always-on compute with no sleeping
Pay-as-you-go
- Per-second billing for compute (CPU and GPU), memory, and storage
- No seat-based pricing or commitments
- Deploy on Northflank's managed cloud (6+ regions) or bring your own cloud (600 BYOC regions across AWS, GCP, Azure, Civo)
- GPU pricing: NVIDIA A100 40GB at $1.42/hour, A100 80GB at $1.76/hour, H100 at $2.74/hour, H200 at $3.14/hour, B200 at $5.87/hour
- Bulk discounts available for larger commitments
Enterprise
- Custom requirements with SLAs and dedicated support
- Invoice-based billing with volume discounts
- Hybrid cloud deployment across AWS, GCP, Azure
- Run in your own VPC with managed control plane
- Secure runtime and on-prem deployments
- Audit logs, Global back-ups and HA/DR
- 24/7 support and FDE onboarding
Use the Northflank pricing calculator for exact cost estimates based on your specific requirements, and see the pricing page for more details
Why choose Northflank
Northflank addresses common GPU cloud challenges:
- Multi-cloud freedom - Deploy GPU workloads anywhere without infrastructure lock-in. Switch providers or go multi-cloud without infrastructure rewrites.
- Unified platform advantage - Manage GPU compute with databases, applications, and CI/CD in one place instead of piecing together separate GPU cloud and infrastructure providers.
- Transparent costs - Predictable per-second billing with real-time cost visibility. No surprises from networking or egress fees.
- Developer velocity - Git-based workflows, preview environments, and integrated CI/CD reduce time from code to GPU-powered production. No separate orchestration tools required.
- Enterprise flexibility - BYOC (Bring Your Own Cloud) deployment on your own AWS, GCP, Azure, Civo, Oracle Cloud, or bare-metal infrastructure maintains cloud commitments while gaining unified infrastructure control.
- Flexible scaling - Start with one GPU and scale to hundreds without massive cluster minimums or enterprise contracts.
Learn more: GPU Workloads on Northflank | GPU instances on Northflank | Documentation | Request your GPU cluster
RunPod provides GPU cloud with deployment across multiple regions. Offering GPU instances across 30+ regions, RunPod serves developers and teams needing access to GPUs.

Key features
- GPU deployment across 30+ regions
- Secure Cloud and Community Cloud options
- Serverless GPU with automatic scaling
- Support for custom Docker containers and pre-built templates
- CLI and API for automation and CI/CD integration
- Spot instances for interruptible workloads
Best for
Individual developers, ML teams, prototyping, and inference serving.
Lambda Labs offers GPU cloud infrastructure with emphasis on ML workloads. Known for 1-Click Clusters that provision interconnected GPUs, Lambda serves research teams and AI startups.

Key features
- On-demand NVIDIA HGX B200, H100, A100, and GH200 instances
- 1-Click Clusters with pre-configured networking
- Pre-installed ML stack with PyTorch, TensorFlow, CUDA, and Jupyter
- Lambda Private Cloud for dedicated GPU clusters
- NVIDIA Quantum-2 InfiniBand networking for distributed training
- Used by research institutions
Best for
Academic researchers, AI startups, teams prototyping models, and organizations wanting GPU access without complex cloud configurations.
Vast.ai operates a marketplace model connecting users with GPU providers globally. The platform aggregates spare GPU capacity from data centers and individual providers.

Key features
- Marketplace with bid-based pricing
- Access to NVIDIA GPUs including H100, A100, and consumer cards
- Docker container deployment
- SSH access to instances
- Search and filter by GPU specs, bandwidth, and storage
Best for
Experimentation, research projects, and workloads that can tolerate interruptions.
Together AI specializes in serving open-source models through managed inference endpoints. The platform focuses on deploying pre-trained models rather than training infrastructure.

Key features
- Managed endpoints for open-source models
- Support for LLaMA, Mistral, Mixtral, and other popular models
- API-based access with OpenAI-compatible endpoints
- Automatic scaling based on demand
- Integration with popular ML frameworks
Best for
Teams deploying pre-trained models, inference serving, and applications needing model APIs without infrastructure management.
TensorDock provides marketplace-based GPU access with full VM control. The platform offers both on-demand and reserved instances.

Key features
- Marketplace model for GPU access
- Full VM control with Windows and Linux support
- NVIDIA GPUs including H100, A100, and RTX series
- KVM virtualization for isolation
- SSH and RDP access
Best for
Teams wanting VM-level control, specific OS configurations, or security isolation beyond containers.
Modal provides serverless compute for Python-based ML workflows. The platform handles infrastructure automatically while you define functions and dependencies.

Key features
- Serverless execution model
- Python-native API
- Automatic scaling from zero
- GPU support including A100 and H100
- Container-based isolation
- Integration with popular ML libraries
Best for
Python developers, batch processing, serverless inference, and teams wanting infrastructure abstraction.
Use this comparison to identify which alternative aligns with your technical requirements and deployment needs.
| Alternative | Best for | Key advantages | GPU options | Pricing model |
|---|---|---|---|---|
| Northflank | Startups to enterprises needing multi-cloud flexibility and unified infrastructure (both CPU and/or GPU workloads) | Multi-cloud deployment across AWS, GCP, Azure, Oracle Cloud, Civo, and bare-metal; unified platform with databases and CI/CD; BYOC option; Git-based workflows | B200, H200, H100, A100, L4, L40S, GH200, and more | Per-second billing; H100 at $2.74/hr, H200 at $3.14/hr, B200 at $5.87/hr |
| RunPod | Individual developers and ML teams | Community and Secure Cloud options; serverless capabilities | H100, A100, RTX 4090, and more | Varies by cloud tier and GPU type |
| Lambda Labs | Researchers and AI startups | 1-Click Clusters; pre-installed ML stack | B200, H100, A100, GH200 | Varies by instance type |
| Vast.ai | Budget-conscious experimentation | Marketplace with bid-based pricing | H100, A100, consumer GPUs | Pay-by-the-second marketplace rates |
| Together AI | Inference serving for pre-trained models | Managed model endpoints; OpenAI-compatible APIs | Managed infrastructure | Per-token usage-based |
| TensorDock | Teams needing VM control | Full VM access with KVM isolation | H100, A100, RTX series | Hourly and monthly rates |
| Modal | Python-based batch processing | Serverless execution; automatic scaling | A100, H100 | Pay-per-execution |
For teams evaluating alternatives to Fluidstack's infrastructure, several options provide different approaches to GPU cloud computing.
Northflank stands out as a unified cloud platform (both CPU and GPU workloads), not just a GPU provider. You get multi-cloud flexibility to deploy on AWS, GCP, Azure, Oracle Cloud, Civo, or bare-metal from a single interface.
Unlike specialized GPU clouds locked to their own infrastructure, Northflank lets you run your entire stack in one place: GPU workloads alongside databases, applications, APIs, background jobs, and CI/CD pipelines. This removes the need to manage separate tools for GPU compute and infrastructure, while transparent per-second billing ensures cost predictability across providers.
From GPUs for training models to databases for your application, everything is managed from one platform with Git-based workflows and preview environments.
- Start with a free account or go straight to request your GPU cluster
- Test workloads and infrastructure
- Book a demo with an expert engineer
- Calculate savings with the pricing calculator
- Learn more: GPU Workloads on Northflank | GPU instances on Northflank | Documentation


