

Fireworks AI vs Together AI: Which platform fits your stack?
You've deployed your first LLM endpoint. Inference is fast, costs are manageable, and your demo impressed the stakeholders.
However, now you need to ship the actual product, including frontend, backend APIs, databases, background workers, CI/CD pipelines, and staging environments. Suddenly, your inference-only platform feels limiting.
This comparison reviews Fireworks AI vs Together AI and examines Northflank as a production-ready alternative that handles GPU workloads alongside your entire application stack
If you're evaluating these platforms, you'll understand which one matches your workflow and growth trajectory.
Before we go into detail, see this quick comparison below:
| Feature | Fireworks AI | Together AI | Northflank |
|---|---|---|---|
| Primary focus | Fast LLM inference | Open-source model hosting support | Full-stack apps & AI workloads |
| Deployment model | Serverless + on-demand | Serverless + dedicated | Containerized services |
| GPU support | H100, H200, A100, L40S | H100, H200, GB200, B200 | H100, H200, B200, A100 (40GB/80GB), L40S, A10. See more supported GPUs here |
| Model catalog | 100+ models | 200+ models | Bring your own (1 click deploy templates available) |
| Fine-tuning | LoRA, multi-LoRA serving | LoRA & full fine-tuning | Any containerized approach |
| BYOC (Bring Your Own Cloud) | Enterprise plans | Enterprise plans | Self-service (AWS, GCP, Azure, OCI and many more) |
| Full-stack support | Inference only | Model hosting only | Yes (APIs, databases, jobs, frontends) |
| CI/CD | External tools required | External tools required | Built-in Git-based CI/CD |
| Pricing model | Per-token / per-GPU-second | Per-token / per-minute | Per-second usage-based |
| Best for | Optimized inference APIs | Open-source model experimentation | Full-stack production AI applications |
Before going into how Northflank differs, let's examine what Fireworks AI and Together AI offer and where their strengths and limitations become apparent in production environments.
Fireworks AI specializes in serving open-source LLMs with industry-leading performance. The platform's custom FireAttention CUDA kernels deliver inference speeds faster than standard implementations like vLLM, which matters for latency-sensitive applications.
Key strengths:
- Fast inference with optimized serving stack
- Multi-LoRA serving supports deploying multiple fine-tuned model variants without separate hosting fees
- Serverless deployment with per-token pricing
- Model optimization for high-throughput production workloads
Where it falls short:
- No infrastructure control (deploying in your own cloud requires enterprise contracts)
- Limited to inference and fine-tuning (no APIs, databases, or job orchestration)
- No native CI/CD integration
- Thin observability and debugging capabilities
Fireworks focuses on serving models fast. But once your product needs background processing, database-backed workflows, or multi-service architecture, you'll need supplementary tools.
Together AI provides comprehensive access to 200+ open-source models with a focus on flexibility and model selection. The platform supports everything from LLaMA and Mistral to multimodal models and embeddings.
Key strengths:
- Extensive model catalog with instant access
- Both LoRA and full fine-tuning support
- GPU clusters (H100, H200, GB200) for training workloads
- OpenAI-compatible APIs for easy migration
Where it falls short:
- BYOC (Bring Your Own Cloud) and hybrid deployments locked behind enterprise plans
- No support for deploying non-AI services (frontends, APIs, databases)
- Basic observability and monitoring
- No built-in CI/CD or environment management
Together AI works well for teams focused on model experimentation and serving. But if you're building a product that includes AI features rather than being solely an AI API, the platform's scope becomes restrictive.
When comparing Fireworks AI vs Together AI directly, the fundamental difference is optimization focus.
Choose Fireworks AI if:
- Inference latency is your primary concern
- You need to serve multiple fine-tuned variants efficiently
- You want the absolute fastest serving stack available
- Your use case centers on optimized API endpoints
Choose Together AI if:
- You need access to a broad model catalog for experimentation
- You want flexibility in fine-tuning approaches (full training vs LoRA)
- You're migrating from OpenAI and need compatible APIs
- You value model selection over raw inference speed
Both platforms handle GPU access well and provide quality inference services. However, neither supports deploying complete applications. Both lack native CI/CD integration. And both require enterprise contracts for infrastructure control through BYOC.
When teams outgrow inference-only platforms, they typically need capabilities that go beyond model serving.
They need to deploy frontends, manage databases, orchestrate background jobs, and implement proper CI/CD workflows, all while maintaining their AI workloads.
Northflank provides a unified platform for these requirements.
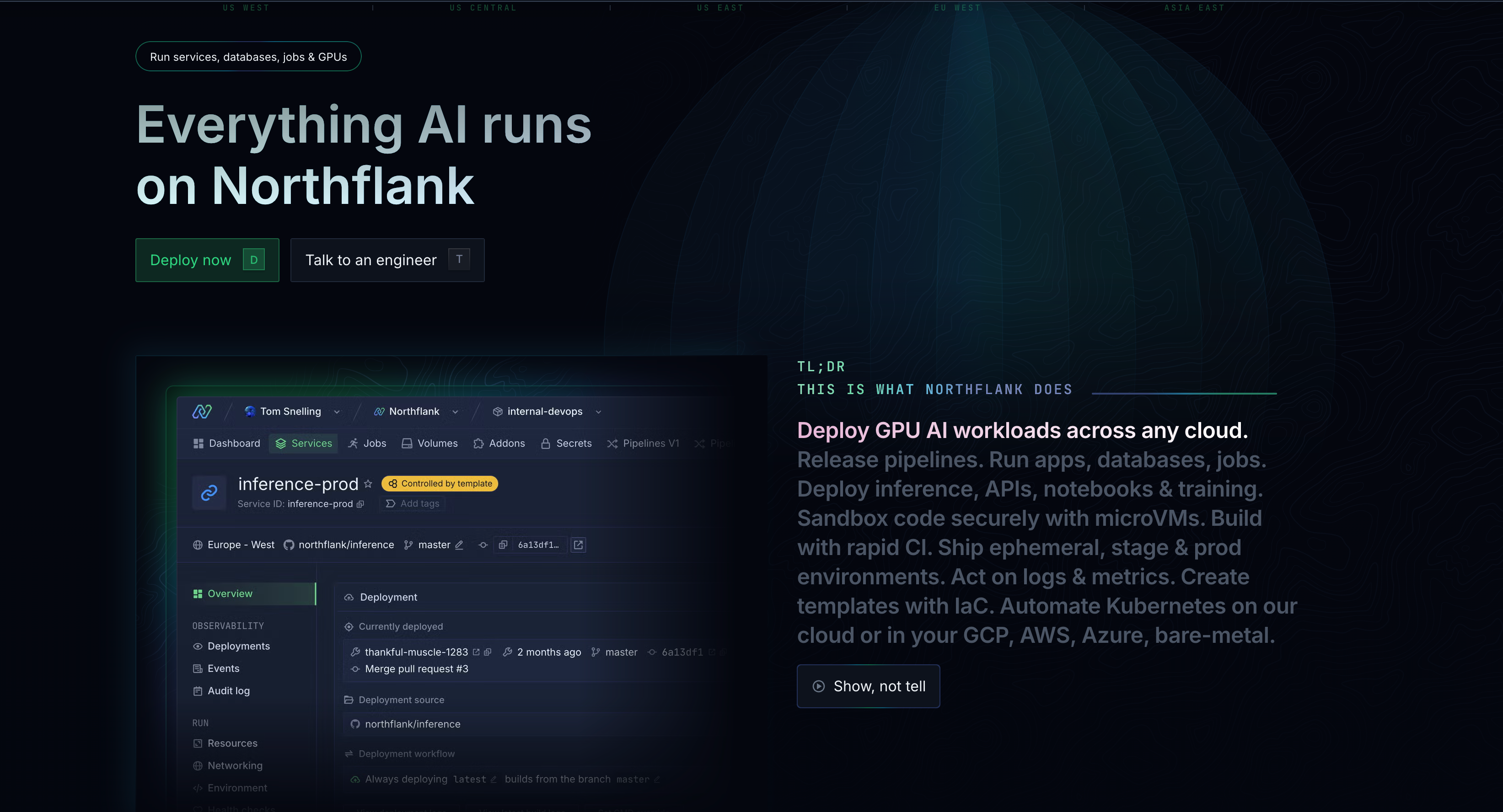
Let’s see some of the features Northflank offers:
Northflank runs on standard Docker containers, meaning you can deploy Python ML workloads, Node.js APIs, React frontends, PostgreSQL databases, and background workers from the same platform. If it runs in a container, it runs on Northflank. You're not constrained to framework-specific patterns or inference-only abstractions.
Real products consist of multiple components. Northflank supports deploying your inference API alongside authentication services, data processing pipelines, scheduled jobs, vector databases, and frontend applications. You don't need multiple platforms to ship a complete product.
While Fireworks and Together require external CI/CD tools, Northflank includes Git integration natively. Connect your GitHub, GitLab, or Bitbucket repository, and each commit triggers automated builds, tests, and deployments. Preview environments for pull requests let your team test changes before production.
Northflank supports Bring Your Own Cloud for AWS, GCP, Azure, Oracle Cloud, and Civo without requiring enterprise contracts or sales calls. Deploy workloads in your own infrastructure while keeping the managed platform experience. This provides cost transparency, data residency control, and integration with existing cloud relationships.
As of September, Northflank offers competitive GPU pricing with per-second billing:
- H100: $2.74/hour
- H200: $3.14/hour
- B200: $5.87/hour
- A100 (40GB/80GB): $1.42-1.76/hour
All pricing includes CPU, memory, and storage bundled together—no hidden fees or surprise costs.
Northflank includes private networking, VPC support, RBAC, audit logs, SAML SSO, and secure runtime isolation for AI-generated code. These enterprise features come standard, not locked behind premium tiers.
The decision between these platforms depends on your current needs and growth trajectory.
Fireworks AI works best for:
- Teams needing the fastest possible inference
- Use cases where you're serving many fine-tuned model variants
- Projects where the entire product is an inference API
Together AI works best for:
- Teams experimenting with multiple open-source models
- Projects requiring diverse model types (text, vision, audio, embeddings)
- Use cases where model selection flexibility matters most
Northflank works best for:
- Teams building complete AI products, not just inference APIs
- Projects requiring both AI and non-AI infrastructure
- Organizations needing infrastructure control through self-service BYOC
- Teams wanting to consolidate vendors and reduce operational complexity
- Use cases where AI is a component of a larger application stack
If you're serving isolated model endpoints and nothing else, Fireworks or Together handle that well. But if you're building a product that includes inference alongside databases, APIs, frontends, and scheduled jobs, forcing these components across multiple platforms creates unnecessary complexity.
Northflank doesn't force you to choose between deployment speed and infrastructure control. You get both, along with the production-ready features your team needs to scale confidently.
Ready to deploy your AI workload on a platform built for complete applications? Start with Northflank's free tier to experience full-stack flexibility with GPU orchestration, or book a demo with an engineer to see how Northflank supports your specific use case.
For teams comparing Fireworks AI vs Together AI and discovering they need more than inference-only platforms provide, Northflank offers the infrastructure to build, deploy, and scale AI products without platform constraints.

