

Best GPU for machine learning
If you have trained a transformer, fine-tuned a vision model, or deployed a recommendation system, you know different workloads push GPUs in very different ways. Some need massive high-bandwidth memory to load, while others only need something efficient enough to serve predictions without slowing down.
That is why it pays to match the GPU to the task. The new H200 and B200 are pushing the limits for large-scale AI, with huge memory and bandwidth for massive models. The H100 and A100 remain strong options for demanding training, while cards like the T4 or L4 are built for high-throughput inference. Choosing the right one can save you days of compute time and a significant amount of budget.
With Northflank, you can access the latest GPUs, from the Blackwell B200 to cost-efficient inference cards, and run your entire workflow from training to deployment in one platform.
In this guide, we will break down the best GPUs for machine learning by use case and how to use them without buying the hardware yourself.
If you are short on time, here is the complete list of the best GPUs for machine learning by use case. Some are built for massive scale, others for efficiency or affordability, and a few are redefining what is possible for AI workloads.
Need specific GPU availability? If you're looking for particular GPU types that aren't currently available or need custom capacity planning, request GPU capacity here.
| Use Case | Best GPU | Why |
|---|---|---|
| Cutting edge large scale training | NVIDIA B200 (Blackwell) | 192 GB HBM3e, up to 8 TB/s bandwidth, 3× training and 15× inference speed over H100-class GPUs |
| High performance training and inference | NVIDIA H200 | 141 GB HBM3e, 4.8 TB/s bandwidth, 2× inference throughput for large language models |
| Proven large scale training | NVIDIA H100 / A100 | Exceptional throughput and memory for enterprise workloads |
| Budget deep learning | NVIDIA RTX 4090 | Strong single-GPU performance at lower cost |
| Production inference | NVIDIA T4 / L4 | Low power, optimized for high throughput requests |
| Fine tuning and prototyping | NVIDIA A40 / A10G | Balanced memory and compute for iterative development |
| Multi modal workloads | NVIDIA H100 SXM | High bandwidth and capacity for complex data types |
If you need these GPUs without buying the hardware, Northflank gives you access to 18+ types including B200, H200, H100, A100 and T4 at competitive rates. Unlike most platforms it is full stack with infrastructure, deployments and observability in one place. Start deploying your GPU workloads here.
Selecting the right GPU begins with identifying the key performance metrics that influence machine learning workloads.
- Compute performance: Measured in floating point operations per second (FLOPs), this indicates raw processing capability. GPUs with more Tensor cores and CUDA cores generally perform better for deep learning.
- Memory capacity and bandwidth: Large models and datasets require high VRAM capacity. Bandwidth determines how quickly data moves between memory and processing units, which directly affects training speed.
- Power efficiency: This matters for large-scale inference, where thousands of predictions per second need to be served with minimal energy costs.
- Framework compatibility: Ensure that your chosen GPU has optimized support for popular ML frameworks like PyTorch, TensorFlow, and JAX.
- Scalability: For very large models, multi-GPU setups or distributed training capabilities are essential.
- Cost efficiency: A powerful GPU is only valuable if its capabilities align with your workload. Using an H100 for small-scale inference is overkill, while using a T4 for large transformer training will slow you down significantly.
These considerations set the stage for evaluating the best GPU types by machine learning task.
Earlier, we discussed the key factors that influence GPU selection. In this section, we explore the main machine learning workflows, including large-scale training, inference, fine-tuning, and multi-modal or high-memory tasks, and the GPUs that work best for each.
Training large models demands exceptional throughput, memory, and bandwidth. The NVIDIA B200 is built for next-gen AI training and inference, while the H200 significantly boosts large language model throughput over the H100. The H100 remains a strong choice for large-scale training, and the A100 continues to be widely used thanks to its proven performance and multiple memory options. For smaller teams or researchers, the RTX 4090 delivers excellent single-GPU performance at a much lower cost.
When models move into production, efficiency and cost become the priority. The NVIDIA T4 is a proven choice for high-throughput inference while keeping power consumption low. The L4 is its newer generation counterpart, offering improved performance per watt and better scaling for modern architectures. For teams that need a balance between inference performance and light training capability, the A10G offers a practical middle ground.
Fine-tuning pre-trained models for domain-specific applications often requires large amounts of VRAM, but not always the extreme compute power of the B200, H200, or H100. The A40 is a strong candidate here with ample memory and good throughput for iterative work. The RTX 6000 Ada is another versatile option for developers who need strong single-GPU performance without investing in full-scale data center hardware.
Workloads that combine multiple data types, such as text, images, and video, require both large memory capacity and high bandwidth. The B200 and H200 stand out here due to their massive memory and speed, enabling smooth training and inference for complex models. The H100 SXM variant also excels in this space, offering extreme bandwidth for demanding applications. The A100 80 GB remains a reliable choice for handling large datasets and model checkpoints, especially in distributed environments.
Once you know the GPU types that fit different machine learning tasks, the fastest way to decide is to compare them side by side. This table highlights the most relevant specs for common AI workflows, including training, inference, fine-tuning, and multimodal processing.
| GPU model | Best for | Memory (GB) | Memory bandwidth | FP16/TF32 performance | Key advantages |
|---|---|---|---|---|---|
| B200 | Extreme-scale training and multi modal workloads | 192 | ~8 TB/s | Very high | Next-gen Blackwell architecture, massive memory and throughput |
| H200 | Large-scale training with very high memory needs | 141 | ~4.8 TB/s | Very high | Improved memory bandwidth over H100, better for very large models |
| H100 | Training LLMs and high-end multi modal | 80 | ~3.35 TB/s | Very high | Strong training performance, excellent scaling |
| A100 | Large batch training, distributed workloads | 40 / 80 | ~1.6 TB/s | High | Proven data center standard, still widely used |
| RTX 4090 | Small-scale training, experimentation | 24 | ~1 TB/s | High | Affordable for local dev, strong single GPU performance |
| A40 | Fine tuning, domain-specific model training | 48 | ~696 GB/s | Medium | High VRAM for fine tuning and mid-scale tasks |
| RTX 6000 Ada | Fine tuning, dev environments | 48 | ~960 GB/s | High | Workstation-class, strong dev flexibility |
| T4 | Cost-effective inference | 16 | ~320 GB/s | Low | Very efficient, low power cost |
| L4 | Modern inference with better performance per watt | 24 | ~300 GB/s | Low | Energy-efficient upgrade over T4 |
| A10G | Mixed inference and light training | 24 | ~600 GB/s | Medium | Flexible choice for hybrid workloads |
Machine learning workloads rarely stay the same. A team might start with large-scale training on an H100 or H200, then shift to cost-efficient inference on an L4 or T4, and later run fine-tuning on an A40.
In many cloud setups, switching between these GPUs means rebuilding infrastructure or migrating workloads. Having the flexibility to change GPU types as your project evolves is the easiest way to keep performance high while controlling costs.
The challenge is that most clouds make switching GPUs slow or complex. This is where Northflank stands out. It’s built to adapt to changing workloads without infrastructure headaches.
Many platforms give you access to high-end GPUs, but the challenge is finding one where you can run an H100 SXM, H200, or B200 in a way that is simple, cost-effective, and scalable. Northflank has become a reliable choice for that problem.
Northflank abstracts the complexity of running GPU workloads by giving teams a full-stack platform; GPUs, secure runtime, deployments, built-in CI/CD, and observability all in one. You don’t have to manage infra, build orchestration logic, or combine third-party tools.
Everything from model training to inference APIs can be deployed through a Git-based or templated workflow. It supports bring-your-own-cloud (AWS, Azure, GCP, and more), but it works fully managed out of the box.
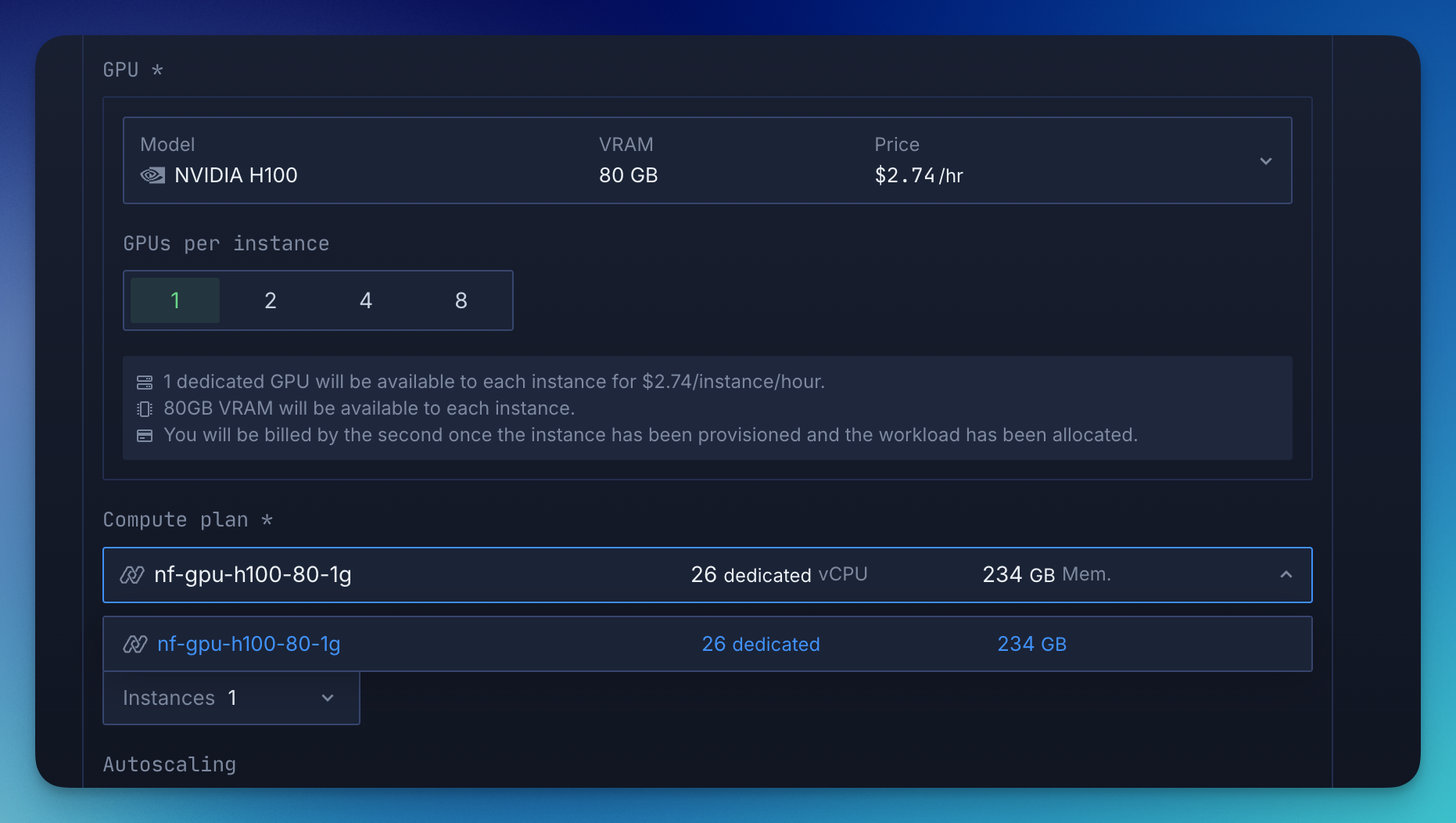
What you can run on Northflank:
- Inference APIs with autoscaling and low-latency startup
- Training or fine-tuning jobs (batch, scheduled, or triggered by CI)
- Multi-service AI apps (LLM + frontend + backend + database)
- Hybrid cloud workloads with GPU access in your own VPC
What GPUs does Northflank support?
Northflank offers access to 18+ GPU types, including NVIDIA A100, B200, L40S, L4, AMD MI300X, and Habana Gaudi.
See how Cedana uses Northflank to deploy GPU-heavy workloads with secure microVMs and Kubernetes.
The best GPU for machine learning depends on the workload. Large-scale training benefits from high-bandwidth cards like the B200, H200, or H100, while inference can run efficiently on options like the T4 or L4. Fine-tuning and multimodal work often call for GPUs with higher memory, such as the A100 80GB or RTX 6000 Ada. Matching your GPU to the task ensures better performance and cost efficiency.
Northflank makes this easier by giving teams access to 18+ GPU types with secure runtimes, deployments, CI/CD, and autoscaling built in. Whether you are training a new model, running inference at scale, or building a full-stack AI application, you can launch and manage workloads without worrying about infrastructure complexity.
Sign up to deploy your first GPU today or book a short demo to see how Northflank fits into your workflow.
What is a GPU
A GPU, or Graphics Processing Unit, is a processor designed for highly parallel computation. This architecture makes it well-suited for the matrix operations and tensor calculations at the core of machine learning.
What is the best GPU for machine learning
There is no universal best. H100 and A100 GPUs excel at large-scale training, T4 and L4 are ideal for inference, and A40 or RTX 4090 are excellent for development and fine-tuning.
What is the best GPU cloud for machine learning
The best GPU cloud is one that offers a variety of GPU types with the ability to scale up or down as needed. Northflank provides access to all major NVIDIA GPUs along with integrated tools for building, training, and deploying ML models.


