

LLM deployment pipeline: Complete overview and requirements
LLM deployment is the process of taking your trained language model and making it available as a production service that can handle live user requests. It involves five main areas: containerizing your model for portability, allocating the right GPU resources, creating API endpoints for access, setting up autoscaling to handle traffic spikes, and securing your deployment environment.
While you can build this infrastructure yourself using tools like Docker and Kubernetes, platforms like Northflank handle the complexity for you, letting you go from model to production API in minutes rather than weeks of infrastructure work.
This article provides a comprehensive overview of what LLM deployment involves - from containerization and GPU allocation to API endpoints and security. If you're looking for step-by-step implementation instructions, check out our complete guide to LLM deployment instead.
LLM (Large Language Model) deployment is you deciding to take a trained language model and convert it into a production-ready service (which means a service that can handle live business traffic) that can handle your user requests reliably, securely, and at scale.
So, it's like the bridge between having a working AI model (that contains your trained weights and logic) and deploying it in your business applications like customer support chatbots, content generation tools, or document analysis systems.
One simpler way to understand it is this:
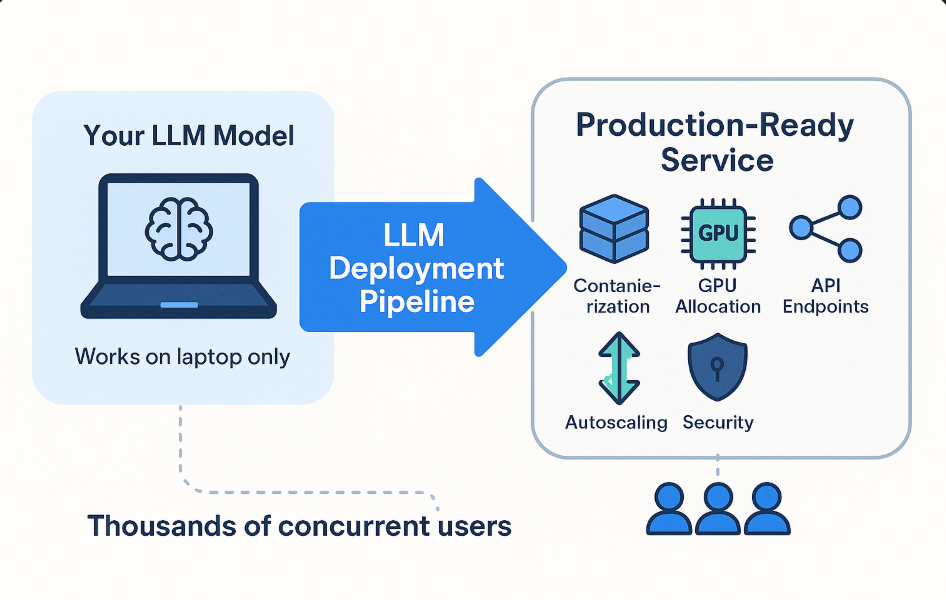
Let's say you've built a chatbot called "SupportBot" for customer service in your organization that works perfectly on your laptop, and the development team can interact with it.
LLM deployment encompasses everything you need to do to make that chatbot available to thousands of users simultaneously through your website or app.
And when I say "everything", I mean five main technical areas that work together:
- Containerization: packaging your model to make it portable
- GPU allocation: setting up servers with the right hardware to provide computing power
- API Creation: creating endpoints for your applications to communicate with the model
- Autoscaling: implementing scaling to handle traffic increases
- Security: protecting your deployment from threats
We’ll go into each of these areas later in this article.
Now that you understand what LLM deployment involves, you might ask:
”Does my organization really need to go through all this complexity?”
The short answer is: if you want to stay competitive, yes.
And recent stats have shown that more than 80% of enterprises will have used generative AI APIs or deployed generative AI-enabled applications by 2026, while worldwide spending on generative AI is forecast to reach $644 billion in 2025, marking a 76.4% jump from 2024, according to Gartner.
This shows that your competitors aren't only experimenting anymore, they're shipping AI features that are changing how they serve customers and operate their businesses.
Now, this is where most organizations hit a major roadblock*:* the prototype-to-production gap.
You’ve likely experienced this yourself. Your team builds an amazing LLM-powered feature that works beautifully in development. Everyone’s excited. Then someone asks:
“When can we launch this to our customers?”
And suddenly, you realize you’re facing a completely different set of challenges.
This is due to the fact that LLM deployment has specific requirements that most other applications don’t have. Requirements such as:
- Specialized hardware that costs hundreds of dollars per hour
- The ability to handle unpredictable traffic spikes without breaking your budget
- Processing sensitive data securely while maintaining sub-second response times
- Zero tolerance for downtime because your customers notice immediately
This explains the challenge organizations face. The gap between “it works” and “it works reliably for thousands of users” is massive.
Now, finally, we can go into more detail about those five technical areas we mentioned earlier.
Remember, these components could represent weeks or months of specialized work, which is why many organizations opt for a platform that handles this complexity.
Each of these areas has its own unique challenges, and getting any one of them wrong can derail your entire deployment.
More importantly, they all need to work together seamlessly for your LLM to perform reliably in production.
The first step in any LLM deployment is packaging your model so it can run consistently across different environments. This might sound straightforward if you’re familiar with containerizing regular applications, but LLMs bring their own set of complications.
Docker containerization solves dependency conflicts, ensures consistent deployments, and simplifies scaling across different environments. However, LLM applications face unique deployment challenges that standard containerization approaches don’t address.
Your containerization strategy needs to handle massive model files (often 10GB+), GPU driver compatibility, and memory optimization that most applications never deal with. Modern teams pin base images, CUDA versions, model weights, and use security scanning tools like Trivy to surface vulnerabilities during CI (Continuous Integration).
The security considerations alone are complex - you’re dealing with valuable intellectual property (your trained model) that needs protection, plus ensuring your container doesn’t introduce vulnerabilities when accessing GPU resources.
Our platform handles containerization automatically when you deploy models like DeepSeek R1 with vLLM, taking care of GPU optimization and dependency management without requiring specialized Docker expertise.
This is where costs can spiral quickly if you don’t plan carefully. The challenge is understanding how your model size, expected traffic, and performance requirements translate into hardware needs.
Memory requirements are particularly critical, as they determine whether you can run your model on a single GPU or need to distribute it across multiple units.
Different GPU generations offer vastly different capabilities in terms of memory capacity and processing power. The memory requirements alone can determine whether you need a single high-end GPU or multiple lower-tier ones, significantly impacting both performance and costs.
Multi-GPU strategies add another layer of complexity for very large models. This isn’t only about buying more hardware; it’s about orchestrating distributed computing resources that can communicate efficiently and handle failures gracefully.
The cost implications are significant. While exact pricing varies by provider and usage patterns, GPU-intensive workloads can easily cost hundreds or thousands of dollars per hour at scale.
Understanding your performance requirements upfront, rather than discovering them in production, is important for budget planning.
Our platform handles GPU provisioning automatically, so you don’t need to become an expert in hardware specifications. You can select from available GPU types through our interface, and the platform manages the underlying infrastructure.
With our BYOC (Bring Your Own Cloud) feature, which allows you to deploy into your own cloud provider account, you maintain control over costs and can choose GPU instances that fit your budget while we handle the orchestration complexity.
See our guide on self-hosting vLLM in your own cloud account and deploying GPUs in your own cloud for a complete walkthrough.
Your model needs to be accessible to your applications, which means creating robust API endpoints that can handle real-world traffic patterns. Rather than building these endpoints from scratch, most teams use specialized frameworks. vLLM serves models with OpenAI-compatible API endpoints, allowing seamless integration with existing OpenAI tooling.
The “OpenAI-compatible” part is important because it means your applications can switch between different LLM providers without code changes. But building these endpoints involves more than only exposing your model - you need request queuing, batch processing, and load balancing strategies that work with LLM-specific traffic patterns.
This is where LLM APIs differ significantly from traditional web APIs. LLMs use continuous batching to maximize concurrent requests and keep queues low when batch space is available. This is different from traditional API load balancing because LLM requests have variable processing times and memory requirements.
Our platform automatically handles API endpoint creation and load balancing, plus you can deploy models like DeepSeek R1 with vLLM to get production-ready endpoints without building custom infrastructure.
Traditional autoscaling based on CPU or memory metrics fails spectacularly with LLMs. Key metrics for LLM autoscaling include queue size (number of requests awaiting processing) and batch size (requests undergoing inference).
The challenge is that LLMs have unpredictable resource usage patterns. A simple question might process in milliseconds, while a complex request could take minutes. Platforms with fast autoscaling and scaling to zero can reduce costs significantly during low activity periods.
Cold starts are particularly problematic - spinning up a new LLM instance can take several minutes while the model loads into GPU memory. This means you need sophisticated prediction algorithms to scale up before you actually need the capacity.
Our platform provides built-in autoscaling capabilities for your LLM workloads. Our GPU orchestration handles the complexity of spinning up new instances, and the platform automatically manages spot and on-demand GPU instances to optimize costs while maintaining performance.
LLM security goes far beyond traditional application security. The Open Web Application Security Project (OWASP) - a nonprofit foundation that provides security guidance for applications - has created a specific framework called "OWASP Top 10 for LLMs" that outlines today's most pressing risks when building, deploying, or interacting with large language models, including prompt injection, data leakage, supply chain vulnerabilities, and training data poisoning.
Organizations need to isolate LLM environments using containerization or sandboxing and conduct regular penetration testing. However, LLM-specific threats like prompt injection attacks require specialized monitoring and filtering that traditional security tools don't provide.
Runtime protection solutions monitor adversarial threats, including prompt injection, model jailbreaks, and sensitive data leakage in real time. This isn't optional - a single successful attack can expose your training data, steal your model, or manipulate outputs to harm your business.
Our platform provides secure container environments with built-in network isolation, encrypted communications, and compliance-ready infrastructure. With our BYOC (Bring Your Own Cloud) option, you maintain complete control over data residency and security policies while still getting managed deployment benefits.
This addresses the infrastructure security layer, though you'll still need to implement application-level protections like input validation and output filtering for LLM-specific threats.
After walking through those five technical areas, you're most likely thinking: "This sounds like a full-time job for my entire engineering team." You're not wrong.
That's one of the reasons why platforms like Northflank exist - to handle this complexity so you can focus on what differentiates your business.
Let's revisit each area and see how Northflank transforms weeks of specialized work into a few clicks:
Rather than stressing over Docker configurations, GPU drivers, and security scanning, you simply connect your code repository to Northflank. Our platform automatically handles containerization with GPU optimization built in. You don't have to become a Docker expert or worry about CUDA compatibility issues.
When you deploy models like DeepSeek R1 with vLLM, the entire containerization process happens behind the scenes. Your model gets packaged with the right dependencies, security patches, and performance optimizations without any manual configuration.
Remember those GPU allocation challenges we discussed? Northflank provides on-demand GPU infrastructure with streamlined deployment processes, allowing you to have your model up and running in minutes rather than spending hours on configuration and setup.
You don't need to become an expert in GPU sizing, multi-node configurations, or cost optimization. Our platform handles resource allocation automatically, scaling GPU resources based on your actual usage patterns rather than forcing you to over-provision expensive hardware.
Northflank simplifies API endpoint creation by supporting popular LLM serving frameworks. For example, when you deploy using vLLM (as shown in our DeepSeek R1 deployment guide), you get OpenAI-compatible API endpoints automatically.
What this means for you: your applications can switch between different LLM providers without code changes, and you get enterprise-grade load balancing, request queuing, and error handling without building custom infrastructure.
While other teams struggle with LLM-specific scaling challenges, Northflank's platform automatically handles the complexity. Our autoscaling responds to the unique traffic patterns of LLM workloads, managing cold starts and optimizing for both performance and cost.
You get the benefits of advanced scaling algorithms without needing to understand queue metrics, batch optimization, or GPU memory management.
Our platform provides secure container environments with built-in network isolation and encrypted communications. For organizations with strict compliance requirements, our BYOC (Bring Your Own Cloud) option lets you maintain complete control over data residency and security policies.
BYOC allows you to maintain control over your data residency, networking, security, and cloud expenses while deploying the same Northflank workloads across any cloud provider without changing a single configuration detail.
Here's what this means in practical terms: rather than spending 2-3 months building deployment infrastructure before you can even test your LLM with live users, you can have a production-ready deployment running in under an hour.
Your team stays focused on improving your AI features, building better user experiences, and solving business problems. You're not becoming a DevOps team for LLM infrastructure - you're staying an AI-focused product team.
Northflank's platform adapts to your growth, handling everything from automatic GPU provisioning to load balancing and monitoring.
From startups testing their first LLM feature to enterprises deploying multiple models across different regions, the platform scales with your requirements.
And because we handle the infrastructure complexity, you can experiment faster, iterate more quickly, and get to market while your competitors are still figuring out Kubernetes configurations.
Next steps: Get started with Northflank or book a demo with an Engineer.
You can also check out our complete developer's guide to LLM deployment or review self-hosting options with BYOC for maximum control and compliance.


