

AWS SageMaker alternatives: Top 6 platforms for MLOps in 2026
AWS SageMaker is a comprehensive machine learning platform that simplifies building, training, and deploying ML models.
However, many teams seek alternatives due to vendor lock-in concerns, complex pricing, limited customization, and multi-cloud requirements.
Northflank stands out as the top choice for production-ready AI/ML workloads, offering container-native deployment, multi-cloud support including BYOC (Bring Your Own Cloud), transparent pricing, and full CI/CD capabilities that traditional ML platforms lack.
AWS SageMaker is Amazon's fully managed machine learning service that provides data scientists and developers with the ability to build, train, and deploy machine learning models quickly. Launched in 2017, SageMaker aims to remove the complexity of machine learning infrastructure management by offering a complete platform for the entire ML lifecycle.
SageMaker has multiple components, including Studio notebooks for development, automated machine learning (AutoML) capabilities, model training infrastructure, and deployment endpoints. The platform integrates deeply with other AWS services and supports popular ML frameworks like TensorFlow, PyTorch, and Scikit-learn.
AWS SageMaker serves multiple machine learning use cases across industries.
- Model training represents one of SageMaker's core strengths. Teams can train models on everything from small datasets using basic instances to large-scale distributed training on powerful GPU clusters.
- Model deployment and inference is another primary use case. SageMaker enables both real-time and batch prediction endpoints, with features like auto-scaling, A/B testing, and multi-model endpoints.
- Automated machine learning through SageMaker Autopilot allows business analysts and citizen data scientists to build models without extensive ML expertise.
Despite its capabilities, several factors drive teams to seek SageMaker alternatives.
1️⃣ Vendor lock-in represents a primary concern, as organizations want multi-cloud flexibility and negotiating power with different providers.
2️⃣ Complex pricing structures create budget unpredictability. SageMaker's billing involves multiple components - compute, storage, data processing, and service-specific charges - making cost forecasting difficult and leading to budget overruns.
3️⃣ Limited customization frustrates engineering teams who need more control over infrastructure, networking, and deployment configurations than SageMaker's managed approach provides. The platform's extensive feature set also brings unnecessary complexity for teams with straightforward use cases.
4️⃣ Multi-cloud requirements are increasingly common for risk mitigation, regulatory compliance, and cost optimization across different workloads. Performance limitations and cold start issues further affect workloads requiring real-time inference with strict latency requirements.
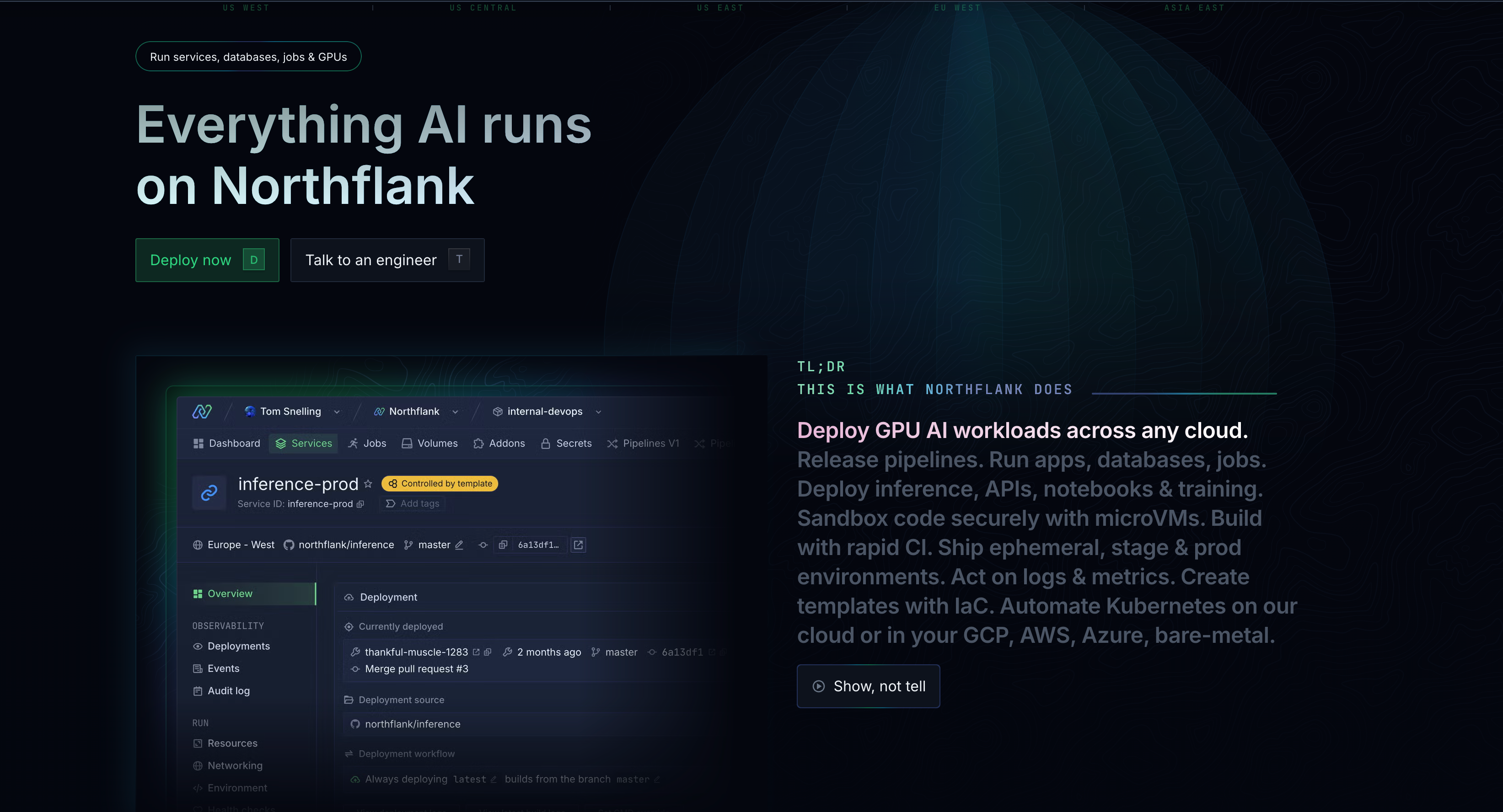
Northflank represents the next generation of cloud platforms designed specifically for teams building production-ready applications, including AI/ML workloads. Unlike traditional ML platforms that focus solely on model training and serving, Northflank provides a complete application deployment platform with first-class support for both AI and non-AI workloads (services, jobs, queues).
Why it stands out
Container-native architecture means any ML framework or custom application runs seamlessly. Run PyTorch, TensorFlow, Hugging Face models, or any custom ML stack without platform restrictions. The platform excels at full-stack AI applications requiring databases, APIs, frontends, and background jobs all working together. Built-in CI/CD pipelines connect directly to Git repositories, enabling true MLOps workflows without additional tooling.
- Multi-cloud and BYOC capabilities set Northflank apart from traditional ML platforms. Deploy workloads to AWS, GCP, Azure, or your own infrastructure while maintaining a consistent developer experience. This approach provides cost control, compliance flexibility, and eliminates vendor lock-in concerns that plague SageMaker users.
- Free tier: Generous limits for testing and small projects
- CPU instances: Starting at $2.70/month ($0.0038/hr) for small workloads, scaling to production-grade dedicated instances
- GPU support: NVIDIA A100 40GB at $1.42/hr, A100 80GB at $1.76/hr, H100 at $2.74/hr, up to B200 at $5.87/hr
- Enterprise BYOC: Flat fees for clusters, vCPU, and memory on your infrastructure, no markup on your cloud costs
- Pricing calculator available to estimate costs before you start
- Fully self-serve platform, get started immediately without sales calls
- No hidden fees, egress charges, or surprise billing complexity like SageMaker
- Enterprise-grade features include secure runtime isolation, RBAC, encrypted secrets management, and comprehensive audit logging. The platform handles auto-scaling, load balancing, and observability out of the box.
Best for: Production AI/ML applications, teams requiring multi-cloud deployment, organizations needing container-native flexibility, and companies wanting to avoid vendor lock-in while maintaining enterprise-grade security and compliance. Startups and enterprises.
Limitation: As a comprehensive platform, Northflank has a steeper learning curve than vertical products like RunPod. However, the excellent developer experience and time savings from integrated CI/CD, multi-service support, and enterprise features quickly offset the initial investment in learning the platform.
Google's unified machine learning platform combines AutoML and AI Platform into a single service. Vertex AI provides strong integration with Google Cloud services and supports both no-code and custom ML workflows.
What it does best: Seamless integration with Google Cloud ecosystem, particularly BigQuery for data analytics. Strong AutoML capabilities make it accessible to non-experts. Vertex AI Pipelines provide good MLOps functionality.
Best for: Teams already using Google Cloud, organizations needing strong data analytics integration, and projects benefiting from Google's pre-trained models.
Limitations: Vendor lock-in to Google Cloud, complex pricing that can become expensive at scale, and limited multi-cloud options.
Pricing: Pay-as-you-go with complex token-based pricing for generative AI features. Training costs range from $0.094/hour for basic configurations up to $11+/hour for high-performance setups. GPU pricing includes Tesla T4 at $0.40/hour, A100 at $2.93/hour. $300 in free credits for new users valid for 90 days.

Paperspace (now part of DigitalOcean) focuses on providing accessible cloud GPUs for ML workloads through both persistent virtual machines and serverless deployment options via their Gradient platform.
What it does best: Simple GPU access for researchers and developers, good integration with Jupyter notebooks, and reasonable pricing for GPU instances. The platform makes it easy to get started with ML development.
Best for: Individual researchers, small teams needing straightforward GPU access, and educational use cases.
Limitations: Limited enterprise features, fewer advanced MLOps capabilities, and less suitable for complex production deployments.
Pricing: On-demand A100 pricing at $3.09/hour, with promotional rates as low as $1.15/hour requiring 36-month commitments. H100 instances starting at $2.24/hour with commitments or $5.95/hour on-demand. Growth subscription plans start at $39/month to access higher-end GPUs. Per-second billing available.

RunPod specializes in serverless GPU computing, offering both secure cloud and community cloud options. The platform focuses on making GPU access simple and cost-effective for AI developers.
What it does best: Fast deployment of GPU-backed containers, competitive pricing especially on community cloud, and good cold-start performance for serverless workloads.
Best for: GPU-intensive inference workloads, cost-conscious teams, and developers needing quick access to various GPU types.
Limitations: Limited to containerized workloads, fewer enterprise features, and restricted to RunPod's infrastructure without BYOC options.
Pricing: H100 80GB from $1.99/hour, A100 configurations from $0.35/hour. Serverless options with per-second billing. Network storage at $0.05-0.07/GB/month.

Built around the open-source Ray framework, Anyscale focuses on distributed computing for AI and ML workloads. The platform excels at scaling Python applications and provides managed Ray clusters.
What it does best: Excellent for distributed ML workloads, strong support for hyperparameter tuning and distributed training, and good integration with popular ML frameworks.
Best for: Teams working with large-scale distributed ML, organizations already using Ray, and complex training workloads requiring distributed computing.
Limitations: Primarily focused on Ray ecosystem, steeper learning curve for teams not familiar with Ray, and less suitable for simple deployment scenarios.
Pricing: Enterprise pricing available on request, typically based on compute usage and cluster management fees. Offers spot instance support and elastic training for cost optimization. Claims up to 50% cost savings through optimized resource management and RayTurbo performance enhancements.

Modal provides serverless compute specifically designed for AI workloads, with a focus on developer experience and fast cold starts. The platform automatically handles scaling and containerization.
What it does best: Extremely fast cold starts (often under 1 second), excellent Python SDK, and seamless auto-scaling capabilities. Strong developer experience with infrastructure-as-code approach.
Best for: Serverless AI workloads, teams prioritizing developer experience, and applications with variable or bursty compute needs.
Limitations: Higher per-hour costs compared to some alternatives, primarily focused on serverless deployments, and limited options for persistent infrastructure.
Pricing: Starter plans include $30/month in free credits. Usage-based serverless pricing with pay-per-second billing. Higher per-hour rates than some competitors but competitive for serverless workloads. B200 GPUs at $6.25/hour, though often noted as one of the more expensive options per-hour for sustained workloads.
Northflank distinguishes itself as the premier SageMaker alternative for several compelling reasons that address the core limitations teams face with traditional ML platforms.
- True multi-cloud flexibility eliminates vendor lock-in concerns that plague SageMaker users. Deploy the same applications across AWS, GCP, Azure, or your own infrastructure using Northflank's BYOC capabilities. This flexibility provides cost optimization opportunities and regulatory compliance options that single-cloud platforms cannot match.
- Container-native architecture means unlimited flexibility in your ML stack. Run any framework, any version, any custom code. Unlike SageMaker's managed approach that can constrain your choices, Northflank's container support means you're never limited by platform decisions.
- Production-grade CI/CD comes built-in, not as an afterthought. Connect your Git repositories and get automated builds, testing, and deployments without cobbling together separate tools. This integrated approach eliminates the complexity teams face trying to create MLOps workflows with SageMaker and external CI/CD tools.
- Full-stack application support sets Northflank apart from ML-focused platforms. Deploy your model alongside databases, APIs, frontends, and background jobs. This comprehensive approach eliminates the architectural compromises teams make when ML platforms force them to use external services for non-ML components.
- Enterprise security without compromise includes secure runtime isolation, encrypted secrets management, comprehensive RBAC, and audit logging. These features come standard, not as expensive add-ons.
- Transparent, predictable pricing removes the budget anxiety associated with SageMaker's complex billing. Pay for resources you use, with clear pricing tiers and no hidden fees. BYOC options eliminate markup on your own infrastructure while providing managed platform benefits.
- Developer experience designed for modern teams combines powerful APIs, intuitive web interfaces, and comprehensive CLI tools. Teams spend time building applications, not fighting platform complexity.
| Platform | Multi-cloud | Container support | Built-in CI/CD | BYOC | Pricing model | Best for |
|---|---|---|---|---|---|---|
| Northflank | ✅ Full support | ✅ Native Docker/K8s runtimes | ✅ Integrated pipelines | ✅ Yes | Transparent usage-based | Production AI/ML applications |
| Google Vertex AI | ❌ Google only | ⚠️ Custom container support but limited orchestration | ⚠️ External via other GCP services | ❌ No | Complex token-based | Google Cloud ecosystem |
| Paperspace | ❌ Single cloud (DigitalOcean) | ✅ Docker with limitations | ❌ External tools needed | ❌ No | Hourly GPU rates | Individual developers |
| RunPod | ❌ Single cloud. Integrations with external storage ≠ multi-cloud compute. | ✅ Good | ❌ External tools needed | ❌ No | Competitive GPU rates | GPU-intensive tasks |
| Anyscale | ⚠️ Limited, mostly AWS, limited Azure | ⚠️ Ray workloads only | ⚠️ Via Ray | ❌ No | Custom enterprise | Distributed computing |
| Modal | ⚠️ Single cloud (AWS) | ✅ Automated | ❌ External tools needed | ❌ No | Serverless usage | Serverless AI workloads |
AWS SageMaker was one of the first managed machine learning platforms, but modern teams building production AI applications need more than just model training and serving. They need flexible, multi-cloud platforms that support their entire application stack without vendor lock-in.
Northflank is the clear winner for teams serious about production AI/ML deployments.
If you're building AI-powered products rather than just experimenting with models, Northflank gives you the production-grade platform capabilities that traditional ML services can't match.
Deploy complete applications with databases, APIs, and frontends alongside your ML models, all while keeping the flexibility to use any cloud provider or your own infrastructure.
You can start building on Northflank today through our self-serve platform, or chat with one of our engineers about your specific needs.
- What is AWS SageMaker and how does it work? AWS SageMaker is Amazon's fully managed machine learning service that provides tools for building, training, and deploying ML models in the cloud. It works by offering integrated components like Studio notebooks, AutoML capabilities, training infrastructure, and deployment endpoints.
- What is AWS SageMaker used for in production? AWS SageMaker is primarily used for model training on scalable GPU clusters, real-time and batch model inference through managed endpoints, automated machine learning for business users, and MLOps workflows.
- Is Northflank better than AWS SageMaker for production AI? For production AI applications requiring multi-cloud deployment, full-stack application support, and integrated CI/CD, Northflank offers significant advantages over SageMaker. Its container-native approach, BYOC capabilities, and transparent pricing make it ideal for teams building production-ready AI products rather than just training models.
- Can I migrate from AWS SageMaker to other platforms easily? Migration difficulty depends on how deeply integrated your SageMaker setup is with other AWS services. Container-native platforms like Northflank make migration easier since you can containerize your models and applications, maintaining the same code while gaining multi-cloud flexibility.


