

6 best TensorDock alternatives for GPU cloud compute and AI/ML deployment
TensorDock provides competitive GPU marketplace pricing and global availability, but as your AI projects scale from prototypes to production, you might need CI/CD integration, observability tools, full-stack deployment capabilities, or production-grade infrastructure that platforms like Northflank deliver alongside GPU orchestration.
This article compares the top TensorDock alternatives to help you identify the right platform for your specific needs, from cost optimization to production deployment and specialized AI workflows.
If you're short on time, see a detailed look at the top TensorDock alternatives. Each platform has its strengths, but they solve different problems, and some are better suited for production deployment than others.
| Platform | Best for | Key features | Pricing model | Production focus |
|---|---|---|---|---|
| Northflank | Production AI apps with full-stack needs | Bring Your Own Cloud, Git CI/CD, autoscaling, secure runtime, multi-service orchestration | Usage-based, transparent | Full production platform |
| RunPod | Cost-effective GPU containers | Serverless GPUs, marketplace pricing, container control | Pay-per-use, competitive rates | Container-focused |
| Vast.ai | Budget-friendly distributed GPU | Community marketplace, bidding system, spot pricing | Auction/spot pricing | Experimental workloads |
| Modal | Python-native serverless | Zero-ops deployment, automatic scaling, Python-first | Serverless, scale-to-zero | Python workflows only |
| Replicate | Public model serving & monetization | One-click APIs, model marketplace, revenue sharing | Usage-based, revenue split | Public demos and APIs |
| Lambda Labs | Hosted Jupyter + training | Pre-configured environments, academic focus, managed notebooks | Fixed instance pricing | Research and training |
When choosing alternatives to TensorDock, the features you prioritize depend on if you're building prototypes or production systems. What to look for:
-
Production deployment capabilities:
Look for platforms that support CI/CD integration with GitHub or GitLab, automated deployments, and proper rollback mechanisms. If you're moving beyond manual container pushes, you need infrastructure that connects to your development workflow.
-
Observability and monitoring:
Built-in logging, metrics, and request tracing become critical once you're serving production traffic. Can you answer questions like "How many requests failed?" or "What's my GPU utilization?" without SSH-ing into containers?
-
Scaling and orchestration:
Static containers work for experiments, but production workloads need autoscaling based on demand, job queues for background processing, and orchestration for complex workflows. Determine if you need these capabilities now or will soon.
-
Multi-service support:
Modern AI applications involve more than GPU containers; they need frontends, APIs, databases, and caches working together. Determine if you can deploy complete application stacks or if you'll need to manage services across multiple platforms.
-
Infrastructure control and compliance:
If you have existing cloud investments, compliance requirements, or need VPC integration, look for platforms offering Bring Your Own Cloud capabilities rather than vendor-locked infrastructure.
-
Security requirements:
Consider your data sensitivity and multi-tenancy needs. Basic container isolation might suffice for research, but production systems often require advanced sandboxing, runtime security, and enterprise-grade access controls.
-
Cost structure and transparency:
Marketplace pricing offers savings, but production systems need predictable costs. Look for transparent usage-based pricing that scales with your business rather than surprise fees or complex billing models.
The important factor is matching platform capabilities to your specific needs, including current requirements and where your project is heading.
Once you understand these limitations, it becomes clear that different teams need different solutions. Here are the six best alternatives to TensorDock, each solving specific problems that teams encounter as they scale.
Northflank goes beyond GPU rental to provide a complete platform designed for deploying and scaling production-ready AI applications. It combines the flexibility of containerized infrastructure with GPU orchestration, Git-based CI/CD, and full-stack application support.
From serving a fine-tuned LLM to hosting a Jupyter notebook or deploying a complete product with frontend, backend, and database components, Northflank provides the infrastructure foundation without the platform lock-in that limits other solutions.
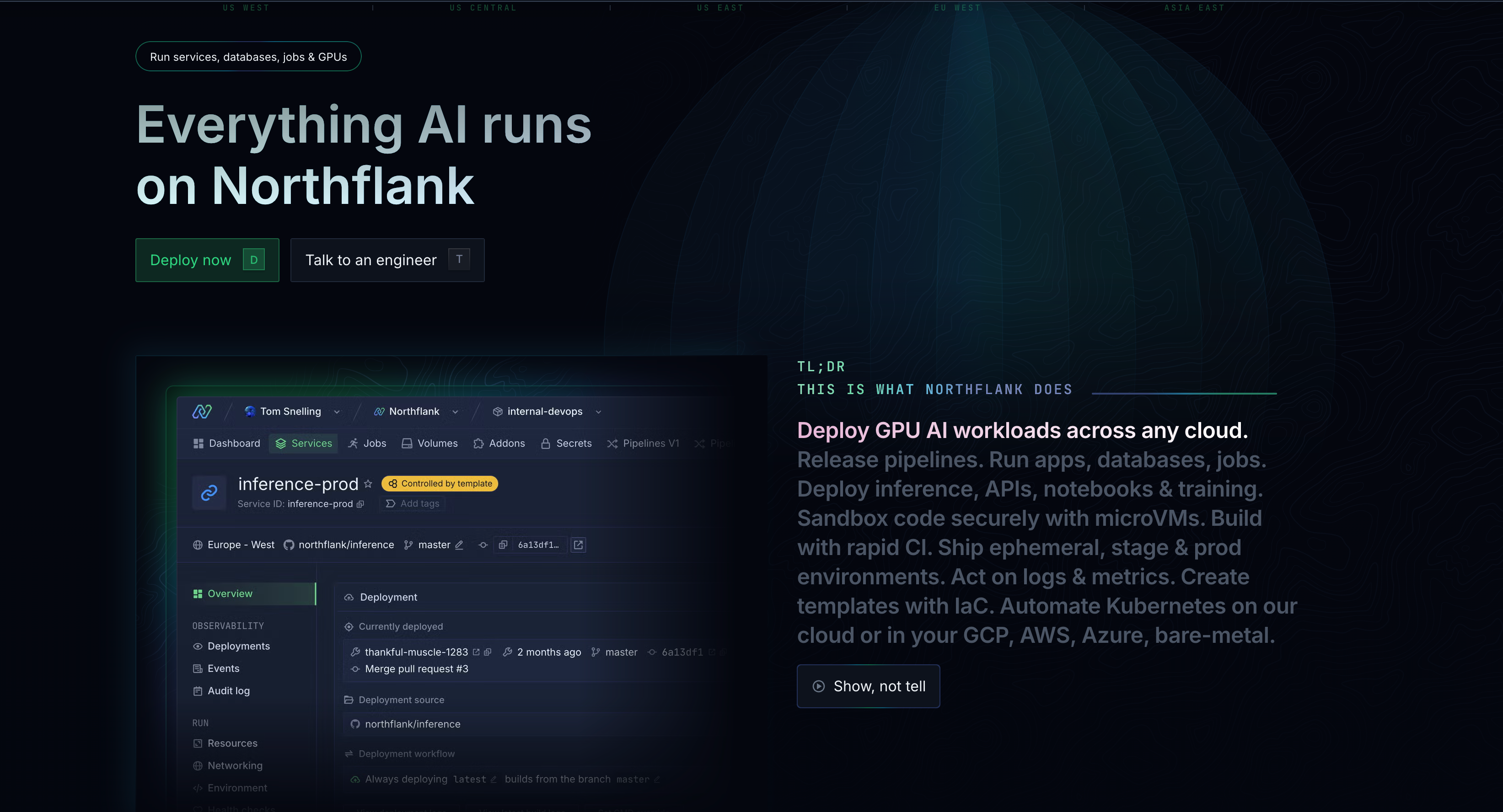
Key features:
- Bring your own Docker image with full runtime control and customization
- GPU-enabled services with autoscaling and lifecycle management for cost optimization
- Multi-cloud and Bring Your Own Cloud (BYOC) support for compliance and integration requirements
- Git-based CI/CD with preview environments for safe iteration
- Secure runtime for untrusted AI workloads with configurable isolation
- SOC 2 readiness and enterprise security features (RBAC, SAML, audit logs)
- Free tier: Generous limits for testing and small projects
- CPU instances: Starting at $2.70/month ($0.0038/hr) for small workloads, scaling to production-grade dedicated instances
- GPU support: NVIDIA A100 40GB at $1.42/hr, A100 80GB at $1.76/hr, H100 at $2.74/hr, up to B200 at $5.87/hr
- Enterprise BYOC: Flat fees for clusters, vCPU, and memory on your infrastructure, no markup on your cloud costs
- Pricing calculator available to estimate costs before you start
- Fully self-serve platform, get started immediately without sales calls
- No hidden fees, egress charges, or surprise billing complexity
Benefits:
- No platform lock-in – maintain full container control while choosing between BYOC or managed infrastructure
- Transparent, predictable usage-based pricing that's easy to forecast at scale
- Exceptional developer experience with Git-based deployments, automated CI/CD, and preview environments
- Optimized for latency-sensitive workloads with fast container startup, GPU autoscaling, and low-latency networking
- Full-stack application support, including frontends, backends, databases, and background jobs
- Built-in cost management with real-time usage tracking, budget caps, and optimization recommendations
Best for: Teams building production-ready AI products that need more than GPU access. Ideal for companies requiring CI/CD integration, multi-service orchestration, compliance controls, or the flexibility to deploy across their own cloud infrastructure.
Verdict: Northflank is the only platform that combines TensorDock's container flexibility with production-grade infrastructure. If you're moving beyond prototypes and need to deploy production AI applications with proper DevOps practices, observability, and scaling capabilities, Northflank provides the most comprehensive solution without vendor lock-in.
RunPod offers the closest experience to TensorDock's model while providing better developer tooling and serverless capabilities. It focuses on making GPU containers as simple and cost-effective as possible.

Key features:
- GPU marketplace with competitive pricing and diverse hardware options
- Serverless GPU functions that scale to zero when not in use
- REST APIs and persistent volumes for easier integration and data management
- Real-time and batch processing options for different workload patterns
Best for: Cost-sensitive teams that want raw GPU power with slightly better tooling than TensorDock, but don't need full production infrastructure capabilities.
Verdict: RunPod provides a TensorDock-like experience with improved developer tools and serverless options. Choose it when you need affordable GPU access with better APIs and flexibility, but can handle infrastructure management yourself.
Vast.ai takes the marketplace model even further than TensorDock, offering a completely decentralized approach where anyone can rent out their GPU hardware. This creates opportunities for even lower costs through bidding and spot pricing.

Key features:
- Decentralized marketplace with thousands of independent GPU providers
- Bidding system for interruptible instances at rock-bottom prices
- Custom container support with flexible deployment options
- Granular hardware filtering for specific GPU requirements
Best for: Budget-conscious researchers, students, and experimenters who prioritize cost over reliability and can handle occasional interruptions.
Verdict: Choose Vast.ai when absolute lowest cost is your primary concern and you can tolerate the reliability trade-offs that come with a fully decentralized marketplace.
Modal takes a completely different approach by making Python deployment as simple as writing a function. It's designed for teams that want to focus on code rather than infrastructure management.

Key features:
- Python-first infrastructure that feels native to ML workflows
- Serverless GPU and CPU runtimes with automatic scaling
- Scale-to-zero billing to minimize costs during idle periods
- Built-in task orchestration for complex workflows and pipelines
Best for: Python-focused teams building serverless workflows, batch processing jobs, or ML pipelines where simplicity and developer experience matter more than maximum flexibility.
Verdict: Modal offers the best Python-native experience for serverless GPU workloads. Choose it when your team works primarily in Python and values simplicity over maximum control.
Replicate is purpose-built for sharing and monetizing machine learning models through public APIs. It's ideal for developers who want to showcase their work or generate revenue from their models.

Key features:
- One-click model deployment to public APIs with automatic scaling
- Community marketplace for discovering and using models
- Built-in model versioning and management capabilities
- Monetization tools for earning revenue from model usage
Best for: Researchers, individual developers, and teams wanting to showcase models publicly, build a following in the ML community, or generate revenue from model APIs.
Verdict: Perfect for model sharing, demos, and monetization. Not suitable for teams building complete applications around their models.
Lambda Labs focuses on providing ready-to-use machine learning environments with pre-configured frameworks and tools. It's designed for researchers and teams who want to start training immediately without environment setup.

Key features:
- Hosted Jupyter notebooks with pre-installed ML frameworks
- Pre-configured environments for TensorFlow, PyTorch, and other popular tools
- Training-focused infrastructure optimized for ML experimentation
- Academic and research-friendly pricing and policies
Best for: ML researchers, students, and teams in early experimentation phases who value ready-to-use environments over maximum flexibility.
Verdict: Lambda Labs excels for learning and experimentation when GPUs are available, but frequent outages and limited production capabilities make it less suitable for ongoing projects.
The right TensorDock alternative depends heavily on your team's specific needs, technical requirements, and stage of development. Here's how to decide:
| If you're... | Choose | Why |
|---|---|---|
| Building production AI products with APIs, frontend, ML models | Northflank | Only platform supporting full-stack AI applications with CI/CD, BYOC, and production infrastructure |
| Need cheapest possible GPU access for training/experiments | Vast.ai or RunPod | Marketplace pricing with community reliability (Vast) or better tooling (RunPod) |
| Python team building serverless workflows | Modal | Native Python experience with automatic scaling and zero infrastructure management |
| Want to share or monetize models publicly | Replicate | One-click model APIs with built-in community and monetization features |
| ML student/researcher wanting ready environments | Lambda Labs | Pre-configured Jupyter environments optimized for learning (when available) |
| Want TensorDock experience with better tooling | RunPod | Similar marketplace model with improved APIs and serverless options |
Production AI products require more than affordable GPU containers; they need CI/CD integration, observability tools, multi-service orchestration, and infrastructure designed to support applications serving users.
The right choice depends on your specific requirements.
For full-stack AI applications, Northflank provides the most comprehensive alternative with production-grade infrastructure and Git-based deployments.
Sign up for Northflank or schedule a demo to see how production-focused infrastructure can accelerate your AI development.

