You can run GPU workloads in your own cloud account using Northflank.
To get started you'll need a cloud account integrated with your team, on a provider that supports the GPUs you want to use. You can check the GPUs available on Northflank here .
Deploy a cluster and a GPU node pool
To run GPU workloads you must have GPU-enabled node-types available. You can deploy GPU node pools on an existing cluster, or create a new one. The GPU nodes you want to use must be available in the region that your cluster is deployed in.
You should create one node pool of non-GPU nodes with at least 4 vCPU and 8GB memory to provision Northflank system components.
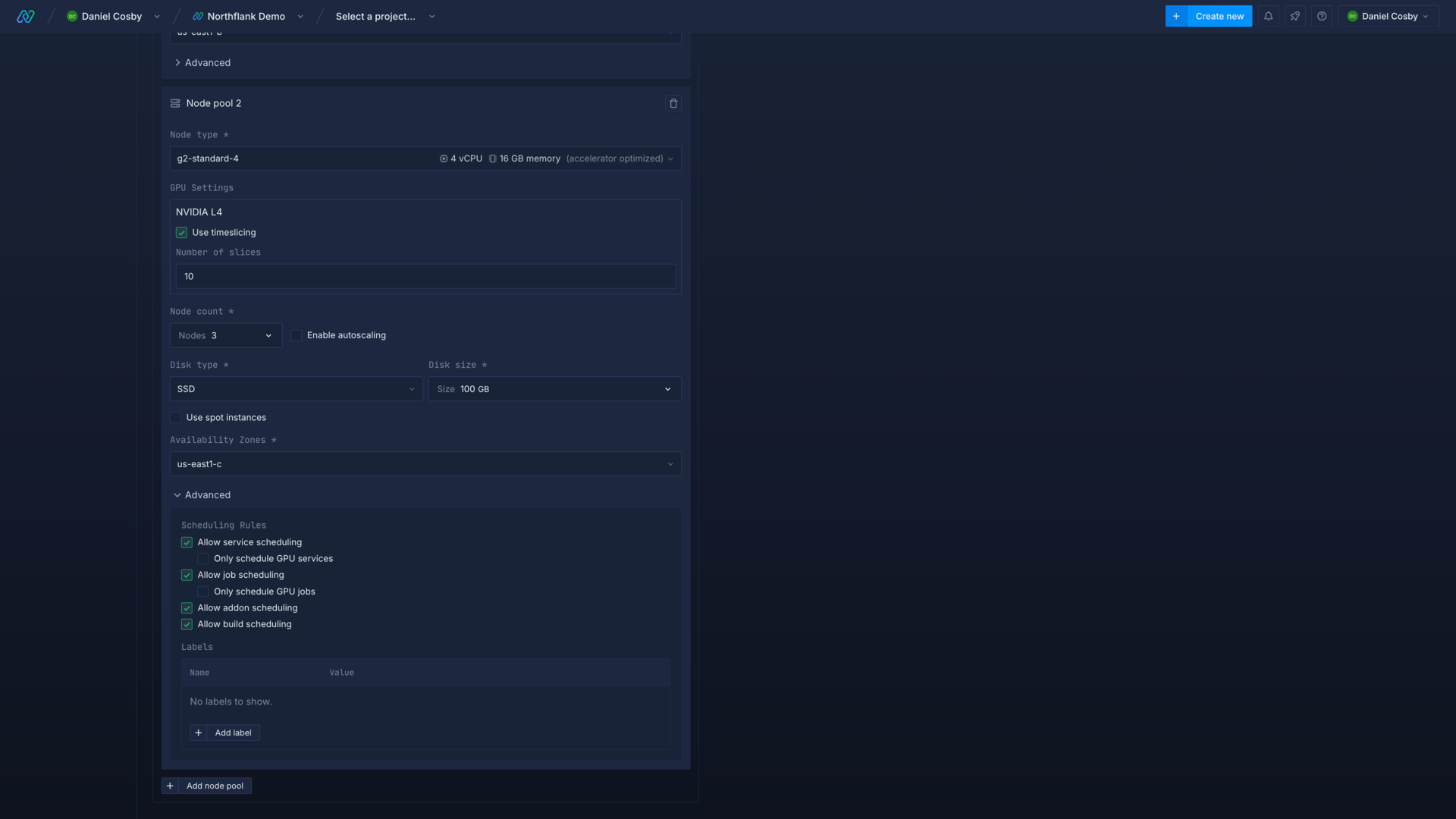
Next, create a node pool and select the type of GPU node you want to deploy. Most GPU node types are listed as accelerator optimised and you can type this category into the node type dropdown to filter nodes, or search by node type name.
Timeslicing
The number of GPUs available to each node varies by node type. Without timeslicing, one GPU process can use a single GPU at a time.
You can enable timeslicing to allow multiple workloads to schedule on an available GPU on a node, which has benefits and drawbacks detailed below. You can specify the number of slices to allow per GPU.
Scheduling rules
In addition to standard scheduling rules you can choose whether to allow non-GPU workloads to provision to GPU node pools. By default, GPU node pools are restricted to GPU workloads; you can make use of any available capacity on nodes by disabling this restriction in advanced settings. However, if your GPU nodes are filled to capacity with non-GPU workloads, GPU workloads will be unable to schedule.
Configure workloads to deploy on GPU nodes
Create a project on your cluster
GPU deployment options will only appear in a service or job if the project you create it in uses a cluster with GPU nodes.
You can create a new project, select bring your own cloud, and then choose your cluster with GPU node pools.
Deploy a service or job with GPU access
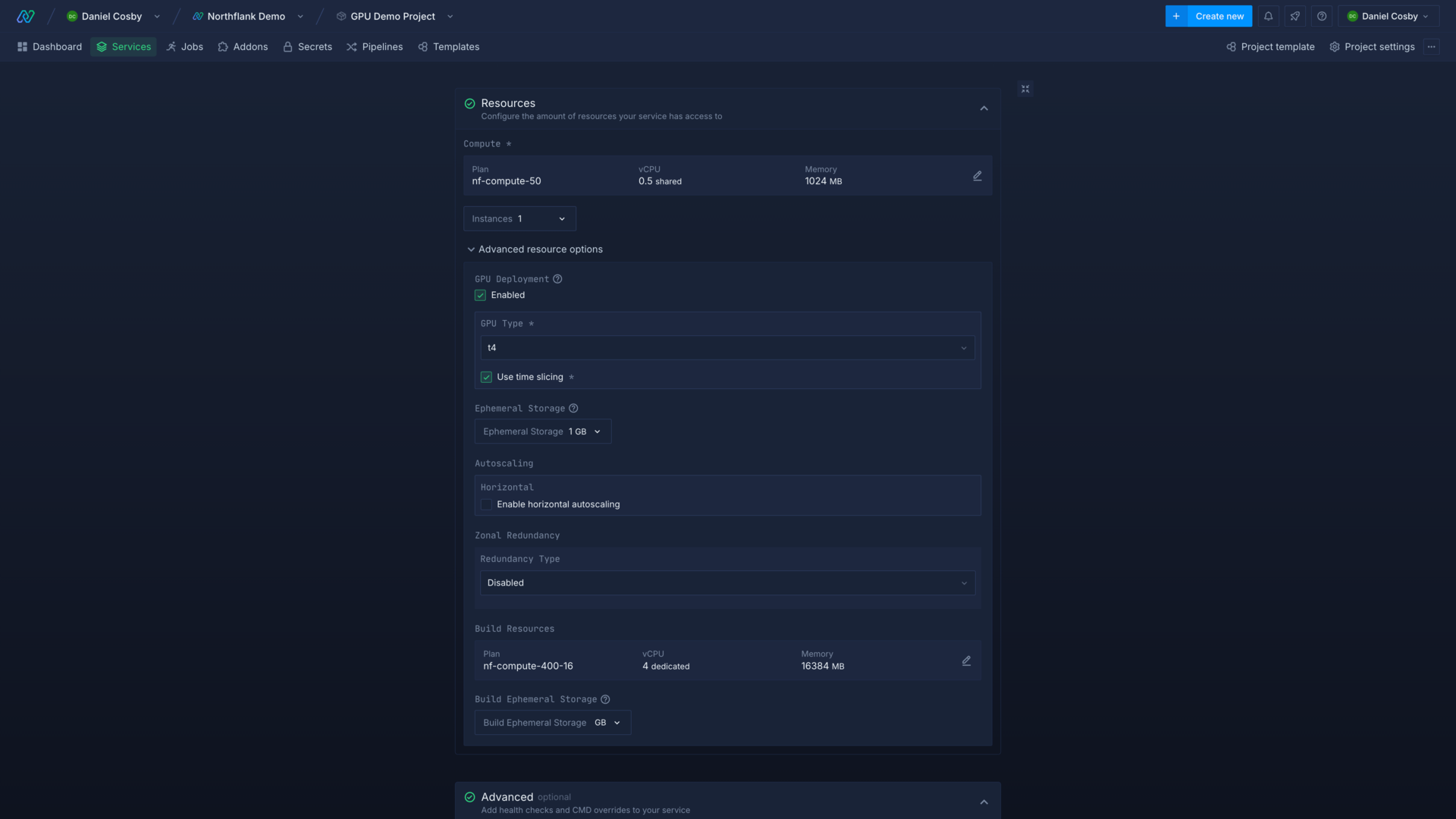
You can enable GPU deployment in advanced resource options in the resources section when you create a new service or job, or update an existing one.
Select the type of GPU to deploy the workload to, and the number of GPUs to use. The options available depend on the node types in your cluster.
You can also choose whether to allow the workload to use a node pool with timeslicing enabled.
If no nodes of the chosen type are available, or no nodes that match the workload's timeslicing preference, your workload will not schedule until capacity becomes available on a matching node. You can gain more capacity either by scaling up existing node pools, creating new ones, or scaling down other workloads using the relevant node type.
Allow multiple workloads to use a GPU with timeslicing
Without timeslicing each GPU workload will be allocated to one GPU, and the node will only be able to schedule as many workloads as there are GPUs on the node.
You can enable timeslicing to enable multiple GPU workloads to schedule per GPU, and set the number of slices to allow on each GPU. The number of slices defines how many workloads can share GPU execution time per GPU on the node.
| GPUs per node | Node count | Timeslicing enabled (number of slices) | GPU workloads that can be scheduled |
|---|---|---|---|
| 1 | 1 | No (1) | 1 |
| 1 | 1 | Yes (10) | 10 |
| 4 | 3 | No (1) | 12 |
| 4 | 3 | Yes (10) | 120 |
Each workload is guaranteed the same amount of GPU execution time, but there is no guarantee on GPU memory allocation per workload. Each workload scheduled will try to use as much GPU resources as possible, which depends on the number of GPU workloads that are deployed to the node and the resources each workload requests. Workloads schedule processes on the GPU and each workload may schedule multiple processes on a GPU. This means the number of processes running on a GPU and the number of workloads scheduled per GPU are not a one-to-one ratio.

important
Timesliced workloads are not fault or memory isolated. For example, if one workload on a time-sliced GPU crashes due to a memory error, all workloads sharing the GPU will crash.
GPU workload scheduling
When you deploy a GPU workload, Northflank will attempt to schedule it to a node that matches the selected GPU. You must also have capacity available for the configured compute plan and ephemeral and persistent storage.
Workloads can only be deployed to a spot node if they have been assigned a spot tag.
You can use labels and tags to further refine which node pools your workloads can be deployed to.
Next steps
Schedule workloads to specific node pools
Deploy workloads to your cluster
Configure applications to use GPUs
You can directly deploy or build your applications with Docker images that are optimised for your desired GPU model and AI/ML libraries.
Build with GPU-optimised images
You can directly deploy or build your applications with Docker images that are optimised for your desired GPU model and AI/ML libraries.
Right-size resources for GPU workloads
Scale CPU, memory, and ephemeral storage to handle GPU workloads.
Persist models and data
You can directly deploy or build your applications with Docker images that are optimised for your desired GPU model and AI/ML libraries.