
What is a sandbox?
Everyone talks about it, nobody really knows how to do it, everyone thinks everyone else is doing it, so everyone claims they are too.
I'm talking about sandboxes!
- Sandboxes are a feature of our product. By default, everything is sandboxed on Northflank.
- We have been sandboxing workloads since we went into production, because part of our product is a PaaS, which means we run untrusted code at scale by default.
- For our sandboxing, we use Kata Containers with Cloud Hypervisor, plus Firecracker and gVisor where a workload calls for it.
This is my attempt to separate the marketing from the underlying isolation technology and explain what makes something a "sandbox" and the different dimensions you need to look at when categorizing them (things like deployment targets, for instance).
None of what follows is particularly novel or controversial. Anyone who has spent time working with workload isolation will likely find most of this extremely basic. Yet, somehow I still see very "all-or-nothing" absolute takes on what a sandbox is, whether an extra 40 ms matters, or how much isolation is necessary.
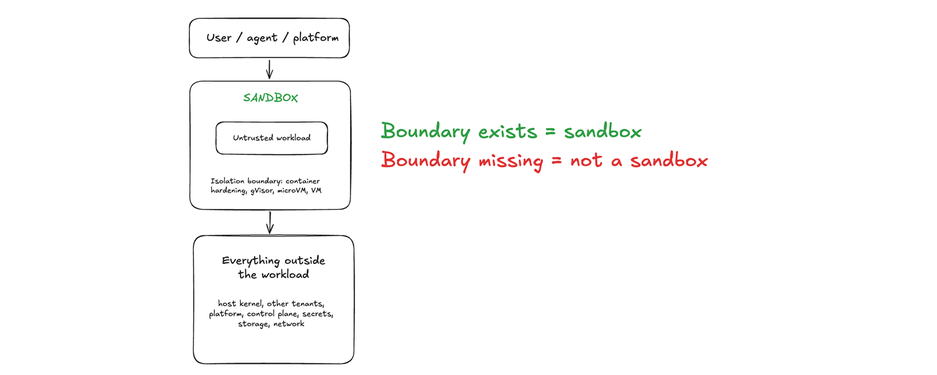
A sandbox is a workload with some form of isolation technology applied to it, so that the untrusted code inside can't compromise anything outside it. Something bad happens in the workload, it stays in the workload.
The framing you'll see everywhere right now, "a computer for your AI agent" is useful, but way too narrow. It's more of a use case than a definition.
If an isolation boundary exists, it's a sandbox. The debate should come down to the strength of that boundary, not whether the sandbox qualifies as one.
AI is not the first time untrusted code has existed. It made the problem much more acute and at much larger scale, which is why sandbox companies are having their coming of age.
I understand why the market chose the word "sandbox." It is familiar, easy to visualize, and works well enough as shorthand.
But it is a highly imprecise term.
Historically, a "sandbox" was a toy: a place to experiment, a dev scratchpad, something temporary. It does not sound like the isolation layer you would rely on to run untrusted code in production.
Before the term "sandbox" became widely used in the AI space, we and many customers referred to this capability as a secure runtime.
That term is closer to what the underlying system does. It runs code with an isolation boundary around it, so the workload can execute without being able to compromise the host, other tenants, or the platform around it.
The market may have settled on "sandbox," but what matters underneath is still the runtime: how code is executed, how it is isolated, and what happens when that code does something unexpected.
By default, you cannot trust the code you're running. The moment a platform runs more than one customer's workloads on shared infrastructure, every workload is untrusted. The customer might be hostile or their code might be fine but their dependency tree compromised. The platform can't know any of this in advance, so it has to assume the worst about all of it.
That's exactly what multi-tenancy is: many tenants, shared hardware, and a security model that's only as good as the boundary between them. Isolation is what lets a platform put thousands of strangers' workloads on the same machines and have a kernel exploit in one of them stay in one of them.
This is also why every PaaS has been in the untrusted code business since the day it onboarded its second customer, AI or no AI.
Sandboxes come in different shapes and forms, but the baseline question is: does the workload have an isolation boundary around it?
That boundary can be stronger or weaker depending on the technology underneath. A hardened container, a gVisor-backed runtime, a Firecracker microVM, and a full VM can all qualify as sandboxes. They do not provide the same level of isolation, but they are all attempts to contain untrusted code.
The debate should be about the strength of the boundary, what it protects, what it exposes, and what tradeoffs it introduces.
What qualifies as a sandbox (not an exhaustive list):
- A workload with an isolation boundary around it
- An environment where untrusted code can run without being able to compromise the host, other workloads, other tenants, or the platform control plane
- A microVM-backed workload, where the code runs inside its own guest kernel with a hardware-enforced virtualization boundary.
- A full VM, where the workload gets a dedicated virtualized machine boundary.
What does not qualify as a sandbox (not an exhaustive list):
- A process running directly on the host with no meaningful isolation.
- A development environment with no isolation boundary around the code being executed.
IMHO, the definition of a sandbox is fairly stable or at least, it should be.
The capabilities people expect from a sandbox vary a lot.
AI has expanded the range of workloads people want to run inside isolated environments. You have things like: short-running code execution, long-running agents, RL environments, vibe coding, notebooks, app previews, inference, and fine-tuning and they all have different requirements.
If a sandbox lives for two seconds, startup time matters a lot. If a sandbox lives for ten hours, a few hundred milliseconds of startup time barely matters.
The questions I believe to be important when looking at sandboxes:
- What isolation technology does it use?
- What can the workload access? (resources on the network, secrets, storage)
- What happens if the workload is compromised?
- How fast does it start?
- How long can the workload run for? (1 minute, 1 hour, 1 month, 7 months, etc)
- Where does the base image come from? (CI/CD, external image registry)
- Can it attach storage, databases, secrets, and GPUs?
- Can it scale without falling over? (Horizontal / vertical scaling)
- How do you interact with it? (SSH, public and private ports, web sockets, TCP/UDP)
And it's always a mix of many.
Lots of people are over-indexing on startup time. Startup time matters, especially for short-lived code execution. But it is only one part of the runtime profile.
A sandbox can boot quickly and still be the wrong choice if every network request is slower, every filesystem operation is expensive, or every unit of work takes longer because of the isolation layer.
The tradeoff is closer to a triangle: performance, cost, and capacity. You want fast startup, but not if it comes with poor runtime performance, weak density, or economics that don't work at scale.
Not all sandboxes are created equal.
While everything on this list qualifies as a sandbox, there are different levels of isolation you get with each one.
Plain containers. A container is a Linux process wrapped in namespaces (its own view of processes, mounts, and the network) and cgroups (limits on CPU and memory). Useful boundaries, but not a wall. Every container on a host shares the host's kernel, and every syscall goes straight to it. One reachable kernel bug and the boundary is gone for everything on that machine. Container escapes through runtime bugs have happened repeatedly and will happen again.
Syscall filtering. seccomp gives a container an allowlist of syscalls and kills it if it tries anything else. Combined with dropping capabilities and running rootless. This reduces the kernel attack surface. Many container-based sandbox offerings stop at this level of hardening.
gVisor. gVisor intercepts syscalls from the workload and handles them in a user-space component (written in Go) instead of passing them directly to the host kernel. This reduces the host kernel attack surface, though it only implements a subset of the Linux syscall interface. The cost is performance on syscall-heavy work and compatibility, since gVisor doesn't implement every Linux interface. Google built it for exactly this multi-tenant problem, and several sandbox providers run on it today.
MicroVMs. Firecracker and Kata Containers give each workload its own guest kernel inside a stripped-down virtual machine, with the boundary enforced by the CPU's virtualization extensions through KVM. A kernel exploit inside the guest generally compromises the guest kernel only. Escaping further requires exploiting the virtualization layer as well. Escaping means breaking the virtual machine monitor itself, which in Firecracker's case is a deliberately tiny piece of software. Kata takes a standard container and transparently runs it inside a lightweight VM, using Firecracker, Cloud Hypervisor, or QEMU underneath, so you keep the container workflow and gain the hardware boundary.
Many AI sandbox providers have converged on microVM-based isolation.
You could go further and give every workload a full VM. The isolation is excellent but the operational overhead is high: slow to provision, heavy, and terrible density.
One of the core AI use case is code execution. An agent writes code and runs it to check whether it works. That code is untrusted by definition because models are not deterministic, inputs can be adversarial, and the code may pull in anything from the internet.
Every agent that executes untrusted code needs an isolation boundary. That demand produced requirements previous isolation setups didn't need to meet, but the requirements depend entirely on what you're running.
One-shot code execution. An agent runs a snippet, reads the output, and the environment dies. Cold start is everything, because the sandbox lives for seconds and startup is most of its lifetime. You also want hard disposability, nothing survives the run, and locked-down egress, because the code might do anything and nobody's watching.
Long-running agents. The opposite profile. A session accumulates state across hours of tool calls: files, processes, half-finished builds. A 200ms cold start is irrelevant when the sandbox lives for ten hours. What matters is pausing it when the agent goes idle so you stop paying for it, resuming it in the exact same state, and storage that survives across sessions.
RL environments. Training agents means running rollouts, an agent acting in an environment over many steps, in enormous parallel batches. Each rollout has to be isolated and stateful, because the agent mutates the environment as it goes and none of it can leak between rollouts. Snapshot and fork is the key primitive: bring an environment to a known state, then launch thousands of copies from it. Density decides the economics, and the sandbox fleet has to scale separately from the GPUs doing the training.
Vibe coding. App builders generate a project, run it, and show the user a live preview. That needs networking (a URL someone can open), persistence between sessions (the user comes back tomorrow), and usually a real database next to the sandbox rather than a mock.
GPU workloads. Inference and fine-tuning belong in the same conversation, because customer models and customer training code are untrusted code too. Passing a GPU through a virtualization boundary is harder than passing through a CPU.
Cloud vs BYOC
Another thing to consider when looking at sandboxes is deployment targets. Decision tree is:
- Data residency
- Cost
- Capacity
Some workloads run in the provider's cloud, while others need to run inside the customer's own environment (BYOC). This could be on AWS, GCP, Azure, Oracle, neo-clouds like CoreWeave/Nebius, or on-prem.
The two models have different constraints around networking, compliance, integration, and operations, so the same sandbox solution may not work equally well in both.
A common claim in the space is that it is not possible to run proper sandboxes on Kubernetes.
It is entirely possible. We have several publicly traded companies, financial institutions, and government agencies with strict regulatory requirements already running sandboxed workloads this way, inside their own VPCs and on their own Kubernetes clusters. For their core production workloads and the new types of agentic workloads, preview environments, and coding harnesses.
Some sandbox providers build their own scheduler. That can work for a focused, vertical developer product, but it is much harder to take into an enterprise environment.
Building your own DIY scheduler is the easy option to get to market faster as a vertical product, but the moment you'll want/need to go horizontal or your enterprise customers will require you to deploy to a specific K8s cluster, things will get tough. Unless you manage to convince every enterprise in the world to move off of K8s!
The teams building this from scratch deserve credit. But there are already enough hard things to build around untrusted code. The scheduler should not become another proprietary platform the enterprise has to understand, approve, and operate.
If you turn up to a regulated enterprise with a bespoke scheduler for running arbitrary code, you are asking them to trust a new control plane, a new security model, a new operational surface area, and a new compliance boundary.
If the only value a provider offers is "we run the sandbox for you," the pricing tends to carry a large markup over the underlying compute.
As a customer, that may be acceptable for early experimentation, but I think it becomes harder to justify when sandbox execution becomes a high-volume production primitive.
Northflank is a deployment platform, a workload delivery platform.
Sandboxing is how we execute code securely for customers running agents, databases, jobs, inference, and training, whether that's in their cloud, ours, or their customers'. It was never the product, but it's how the product runs.
The product is the rest of the lifecycle: push a commit, build it, deploy it, give it a database and a domain, scale it, observe it, back it up, recover it. The whole SDLC from commit to disaster recovery. Through UI, CLI, API, and GitOps.
We're a horizontal developer platform. Every team that ships anything to production needs everything on that list, whether they buy it in one place or tape it together, DIY.
We do everything between a commit and a workload running in production, sandboxed by default.
A workload with an isolation boundary around it. Untrusted code runs inside, and if something goes wrong, it stays inside.
A workload running inside a stripped-down virtual machine with its own guest kernel. The boundary is enforced by the CPU's virtualization extensions through KVM. Firecracker and Kata Containers are the common ones.
A plain container shares the host kernel, so one kernel bug can take out everything on the machine. Harden it with seccomp, run it under gVisor, or wrap it in a microVM and the boundary gets stronger. They all count as sandboxes. The isolation is what differs.
Isolation boundaries for the untrusted code agents write and run. The requirements change with the workload. One-shot code execution needs fast cold start. Long-running agents need pause, resume, and storage that survives across sessions.
Yes. Publicly traded companies, financial institutions, and government agencies already run sandboxed workloads on their own Kubernetes clusters, inside their own VPCs, on Northflank.


