

Best cloud services for renting high-performance GPUs on-demand
If you have tried to rent a high-end GPU in the past year, you know it is not as simple as clicking launch instance. The surge in large language models, generative AI, and high-resolution rendering has pushed global GPU capacity to its limits.
Even well-funded teams face queues, shuffle between providers, or pay premium rates to secure capacity. For workloads from large inference batches to custom model training, the GPU you get and how quickly you get it can decide whether you meet a deadline or miss it. Buying hardware ties up capital and often leaves equipment idle when demand falls.
On-demand GPU rentals change that. They let you access top-tier hardware only when you need it and shut it down when you do not. The challenge is that on-demand means different things depending on the provider. Some focus on instant access while others, like Northflank, offer flexible capacity with managed orchestration so you spend more time on workloads and less on infrastructure.
If you're short on time, here’s the complete list of the best on-demand GPU cloud services for AI and ML teams. Some are built for scale. Others excel at speed, simplicity, or affordability. A few are rethinking the GPU experience from the ground up.
| Platform | GPU Types Available | Key Strengths | Best For |
|---|---|---|---|
| Northflank | A100, H100, H200, B200, L40S, B200, MI300X, Gaudi and many more. | Full-stack GPU hosting with CI/CD, secure runtimes, app orchestration, GitOps, BYOC | Production AI apps, inference APIs, model training, fast iteration |
| NVIDIA DGX Cloud | H100, A100 | High-performance NVIDIA stack, enterprise tools | Foundation model training, research labs |
| AWS | H100, A100, L40S, T4 | Broad GPU catalog, deep customization | Enterprise ML pipelines, infra-heavy workloads |
| GCP | A100, H100, TPU v4/v5e | Tight AI ecosystem integration (Vertex AI, GKE) | TensorFlow-heavy workloads, GenAI with TPUs |
| Azure | MI300X, H100, A100, L40S | Enterprise-ready, Copilot ecosystem, hybrid cloud | Secure enterprise AI, compliance workloads |
| RunPod | A100, H100, 3090 | Secure containers, API-first, encrypted volumes | Privacy-sensitive jobs, fast inference |
| Vast AI | A100, 4090, 3090 (varied) | Peer-to-peer, low-cost compute | Budget training, short-term experiments |
While most hyperscalers like GCP and AWS offer strong infrastructure, their pricing is often geared toward enterprises with high minimum spend commitments. For smaller teams or startups, platforms like Northflank offer much more competitive, usage-based pricing without long-term contracts, while still providing access to top-tier GPUs and enterprise-grade features.
An on-demand GPU is a cloud-hosted graphics processing unit that you can provision for as long as you need and release when you are done. The term “on demand” implies that you are not locked into long-term contracts or upfront capital costs. You can start a GPU instance in minutes, run your workload, and then stop paying the moment you shut it down.
The model has a strong appeal for teams working in AI, rendering, or simulation because workloads in these domains can be unpredictable. One week, you may need multiple high-end GPUs for training experiments; the next week, you may not need any at all. On-demand access allows you to scale your compute resources to match your actual demand.
Most GPU cloud services operate on one or more of these provisioning models:
- True on-demand provisioning
The provider maintains a pool of GPUs that can be allocated instantly when requested. You pay by the hour or minute, and when you release the resource, billing stops. This is the most flexible approach, but availability can vary depending on demand.
- Spot or preemptible instances
These are unused GPUs offered at a lower price. The trade-off is that the provider can reclaim them at short notice if another customer needs the capacity. They are ideal for batch jobs, experiments, or workloads that can handle interruptions.
- Reserved or committed instances
You pay for a fixed GPU allocation over a defined period, whether you use it or not. In exchange, you get guaranteed capacity and sometimes a discounted rate. This works well for continuous production workloads.
Some providers combine these models, offering hybrid access to balance reliability and cost. The choice often comes down to workload criticality and tolerance for variability.
Earlier, we discussed what on-demand GPUs are and how they work. Now, let's examine what makes a good cloud provider. The best GPU cloud providers aren't just hardware vendors; they're infrastructure layers that enable you to build, test, and deploy AI products with the same clarity and speed as modern web services. Here's what truly matters:
-
Access to modern GPUs
H100s and MI300X are now the standard for large-scale training. L4 and L40S offer strong price-to-performance for inference. Availability still makes or breaks a platform.
-
Fast provisioning and autoscaling
You shouldn’t wait to run jobs. Production-ready platforms like Northflank offer second-level startup, autoscaling, and GPU scheduling built into the workflow.
-
Environment separation
Support for dedicated dev, staging, and production environments is critical. You should be able to promote models safely, test pipelines in isolation, and debug without affecting live systems.
-
CI/CD and Git-based workflows
Deployments should integrate with Git and not require manual scripts. Reproducible builds, container support, and job-based execution are essential for real iteration speed.
-
Native ML tooling
Support for Jupyter, PyTorch, Hugging Face, Triton, and containerized runtimes should be first-class, not something you configure manually.
-
Bring your own cloud
Some teams need to run workloads in their own VPCs or across hybrid setups. Good platforms support this without losing managed features.
-
Observability and metrics
GPU utilization, memory tracking, job logs, and runtime visibility should be built in. If you can't see it, you can't trust it in production.
-
Transparent pricing
Spot pricing and regional complexity often hide real costs. Pricing should be usage-based, predictable, and clear from day one.
The good news is that platforms like Northflank provide all these mentioned above in one single platform. Try it out to see how it works
In this section, we will examine each cloud service in detail. You'll discover the specific on-demand GPUs they offer, their optimization focus, and their actual performance across various workloads. Some services are better suited for research environments, while others are designed specifically for production deployments.
Northflank abstracts the complexity of running GPU workloads by giving teams a full-stack platform; GPUs, secure runtime, deployments, built-in CI/CD, and observability all in one. You don’t have to manage infra, build orchestration logic, or combine third-party tools.
Everything from model training to inference APIs can be deployed through a Git-based or templated workflow. It supports bring-your-own-cloud (AWS, Azure, GCP, and more), but it works fully managed out of the box.
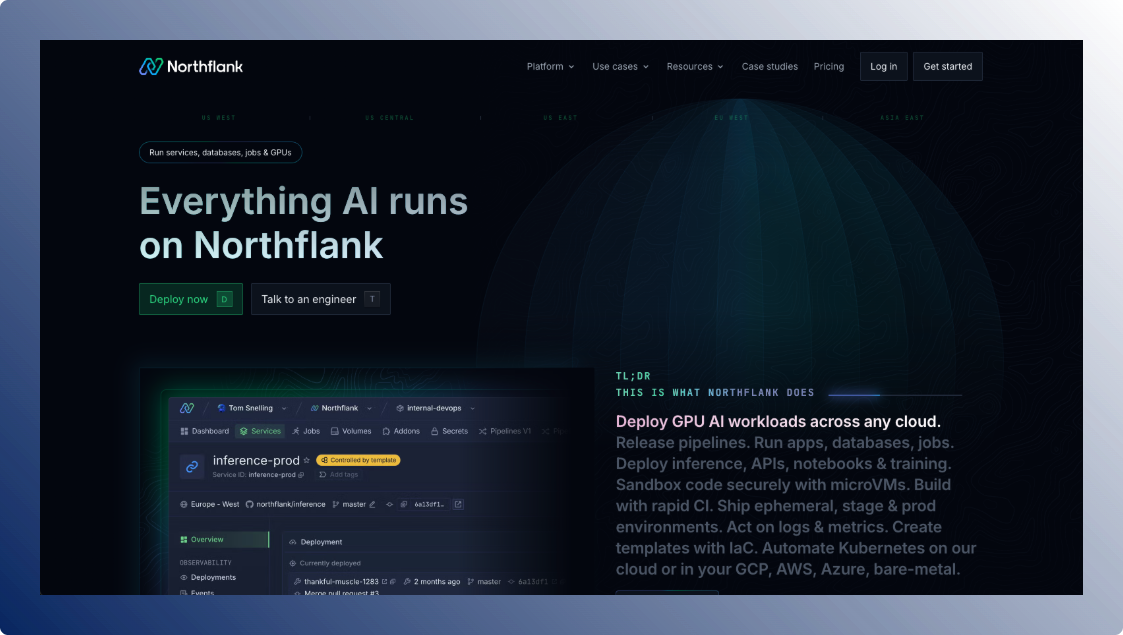
What you can run on Northflank:
- Inference APIs with autoscaling and low-latency startup
- Training or fine-tuning jobs (batch, scheduled, or triggered by CI)
- Multi-service AI apps (LLM + frontend + backend + database)
- Hybrid cloud workloads with GPU access in your own VPC
What GPUs does Northflank support?
Northflank offers access to 18+ GPU types, including NVIDIA A100, H100, B200, L40S, L4, AMD MI300X, and Habana Gaudi.
Where it fits best:
If you're building production-grade AI products or internal AI services, Northflank handles both the GPU execution and the surrounding app logic. Especially strong fit for teams who want Git-based workflows, fast iteration, and zero DevOps overhead.
See how Cedana uses Northflank to deploy GPU-heavy workloads with secure microVMs and Kubernetes
DGX Cloud is NVIDIA’s managed stack, giving you direct access to H100/A100-powered infrastructure, optimized libraries, and full enterprise tooling. It’s ideal for labs and teams training large foundation models.

What you can run on DGX Cloud:
- Foundation model training with optimized H100 clusters
- Multimodal workflows using NVIDIA AI Enterprise software
- GPU-based research environments with full-stack support
What GPUs does NVIDIA DGX Cloud support?
DGX Cloud provides access to NVIDIA H100 and A100 GPUs, delivered in clustered configurations optimized for large-scale training and NVIDIA’s AI software stack.
Where it fits best:
For teams building new model architectures or training at scale with NVIDIA’s native tools, DGX Cloud offers raw performance with tuned software.
AWS offers one of the broadest GPU lineups (H100, A100, L40S, T4) and mature infrastructure for managing ML workloads across global regions. It's highly configurable, but usually demands hands-on DevOps.

What you can run on AWS:
- Training pipelines via SageMaker or custom EC2 clusters
- Inference endpoints using ECS, Lambda, or Bedrock
- Multi-GPU workflows with autoscaling and orchestration logic
What GPUs does AWS support?
AWS supports a wide range of GPUs, including NVIDIA H100, A100, L40S, and T4. These are available through services like EC2, SageMaker, and Bedrock, with support for multi-GPU setups.
Where it fits best:
If your infra already runs on AWS or you need fine-grained control over scaling and networking, it remains a powerful, albeit heavy, choice.
GCP supports H100s and TPUs (v4, v5e) and excels when used with the Google ML ecosystem. Vertex AI, BigQuery ML, and Colab make it easier to prototype and deploy in one flow.
What you can run on GCP:
- LLM training on H100 or TPU v5e
- MLOps pipelines via Vertex AI
- TensorFlow-optimized workloads and model serving
What GPUs does GCP support?
GCP offers NVIDIA A100 and H100, along with Google’s custom TPU v4 and v5e accelerators. These are integrated with Vertex AI and GKE for optimized ML workflows.
Where it fits best:
If you're building with Google-native tools or need TPUs, GCP offers a streamlined ML experience with tight AI integrations.
Azure supports AMD MI300X, H100s, and L40S, and is tightly integrated with Microsoft’s productivity suite. It's great for enterprises deploying AI across regulated or hybrid environments.

What you can run on Azure:
- AI copilots embedded in enterprise tools
- MI300X-based training jobs
- Secure, compliant AI workloads in hybrid setups
What GPUs does Azure support?
Azure supports NVIDIA A100, L40S, and AMD MI300X, with enterprise-grade access across multiple regions. These GPUs are tightly integrated with Microsoft’s AI Copilot ecosystem.
Where it fits best:
If you're already deep in Microsoft’s ecosystem or need compliance and data residency support, Azure is a strong enterprise option.
RunPod gives you isolated GPU environments with job scheduling, encrypted volumes, and custom inference APIs. It’s particularly strong for privacy-sensitive workloads.
What you can run on RunPod:
- Inference jobs with custom runtime isolation
- AI deployments with secure storage
- GPU tasks needing fast startup and clean teardown
What GPUs does RunPod support?
RunPod offers NVIDIA H100, A100, and 3090 GPUs, with an emphasis on secure, containerized environments and job scheduling.
Where it fits best:
If you're running edge deployments or data-sensitive workloads that need more control, RunPod is a lightweight and secure option.
Vast AI aggregates underused GPUs into a peer-to-peer marketplace. Pricing is unmatched, but expect less control over performance and reliability.
What you can run on Vast AI:
- Cost-sensitive training or fine-tuning
- Short-term experiments or benchmarking
- Hobby projects with minimal infra requirements
What GPUs does Vast AI support?
Vast AI aggregates NVIDIA A100, 4090, 3090, and a mix of consumer and datacenter GPUs from providers in its peer-to-peer marketplace. Availability and performance may vary by host.
Where it fits best:
If you’re experimenting or need compute on a shoestring, Vast AI provides ultra-low-cost access to a wide variety of GPUs.
If you've reviewed the list and identified the key features that matter to you, this section will help you make your decision. Different workloads require different strengths, though some platforms consistently offer more comprehensive solutions than others.
| If you need… | Best options from this list | Why |
|---|---|---|
| Instant access for urgent jobs | Northflank, AWS | Large on-demand pools, fast startup, global regions |
| Lowest cost for flexible workloads | Northflank, Vast AI, spot pools | Low hourly rates, flexible provisioning, pay only when running |
| Guaranteed capacity for long training | Northflank managed pools, AWS reserved, GCP scheduled GPUs | Predictable performance and locked-in capacity |
| Tight integration with AI tooling | GCP (Vertex AI), Azure ML | Prebuilt pipelines, built-in ML frameworks |
| Data residency or regional coverage | Northflank, AWS, Azure | Broadest global infrastructure for compliance and latency |
| Minimal DevOps overhead | Northflank, RunPod | Managed orchestration, Git-based deployments, secure containers |
On-demand GPU hosting is now a cornerstone of modern AI infrastructure. The best platform for you depends on how quickly you need capacity, the level of control you want, and how much of the surrounding stack is already handled.
We’ve covered what on-demand really means, how providers differ, and which features matter most. If you want GPUs that are ready the moment you need them, scale without friction, and integrate into your workflows, Northflank is worth a look. It’s built for developers, handles orchestration end-to-end, and lets you move from prototype to production without the usual ops overhead.
Try Northflank or book a demo to see how it fits your ML stack.


