

ChatGPT usage limits explained: free vs plus vs enterprise
Claude Code can get expensive at scale. The alternative is self-hosting open-source models on Northflank. You can get started here, by deploying models like Qwen3 and DeepSeek.
ChatGPT's usage limits restrict access when you need it most, with a limit of 10 messages every 5 hours on the free plan. After reaching this limit, chats will automatically use the mini version of the model until your limit resets. Even enterprise customers face "fair use" policies that can unpredictably throttle usage.
The core problem isn't cost - it's control. You don't own your AI performance; you rent it, and it gets rationed.
Self-hosting open-source models with Northflank gets rid of these limits entirely. You can deploy ChatGPT-quality models like DeepSeek v3 or GPT-OSS 120B with no usage caps, complete data privacy, and costs up to 3.5x cheaper than ChatGPT's API pricing.
I know how annoying it gets when you reach your ChatGPT limit right when you need it most.
If you're using the free plan, you might find yourself cut off mid-conversation. Plus subscribers often wonder why they can no longer generate more images or access GPT-5. These usage restrictions can disrupt your workflow when you least expect it.
That's why platforms like Northflank exist - to help you deploy AI models without the unpredictable limits and restrictions that come with third-party APIs.
Let's look at what you get with each ChatGPT plan:
ChatGPT Free Plan:
- 10 messages every 5 hours using GPT-5
- Automatic downgrade to GPT-4o mini after limit
- 2-3 images per day with DALL-E
ChatGPT Plus ($20/month):
- 160 messages every 3 hours with GPT-5 (temporary increase)
- 50 images every 3 hours with DALL-E
- Priority access and faster speeds
ChatGPT Business ($25-30/user/month):
- Virtually unlimited GPT-5 messages (subject to fair use)
- Team workspace and analytics
- Custom GPT creation
ChatGPT Pro ($200/month):
- Unlimited access to all models including GPT-5 Pro
- No usage caps on advanced features
- Priority processing and fastest speeds
The Pro plan is significantly different from Business - it's designed for individual power users willing to pay $200/month for unlimited access, while Business is for teams at a much lower per-user cost.
ChatGPT usage limits exist for several reasons that keep the platform stable.
 ChatGPT usage limit error message - source
ChatGPT usage limit error message - source
The main reason is server resource management. AI models like GPT-4 require massive computational power to function.
Let's say 100 power users each sent 1,000 requests per hour during peak times. This would generate 100,000 simultaneous requests, which could overload OpenAI's infrastructure and make the service unavailable for millions of regular users.
There's also fair access distribution. These limits ensure that ChatGPT remains accessible to millions of users worldwide, rather than allowing unlimited usage that would drive up costs for everyone.
Cost control plays a huge role as well.
Running large language models is incredibly expensive. Each GPT-4 response costs OpenAI significantly more than a GPT-3.5 response, which is why the more advanced models have stricter limits.
Finally, there's abuse prevention.
Without proper limits, the platform would be vulnerable to automated scraping, spam attacks, and other malicious activities that could destabilize the service for legitimate users.
The free plan gives you up to 10 messages every 5 hours using GPT-5. After reaching this limit, chats will automatically use the mini version of the model until your limit resets.
 User on Reddit sharing their experience hitting the free tier's message limit
User on Reddit sharing their experience hitting the free tier's message limit
You also get:
- Access to GPT-5 (OpenAI's current flagship model)
- 2-3 images per day with DALL-E
- File uploads with restrictions
- Web browsing capabilities
- No access to advanced voice mode or custom GPTs
The main difference from previous years is that free users now access OpenAI's most advanced model rather than being limited to older versions, though with strict usage limits.
Your Plus subscription at $20/month gives you much higher allowances, but they're still capped. Let's see what the community has documented:
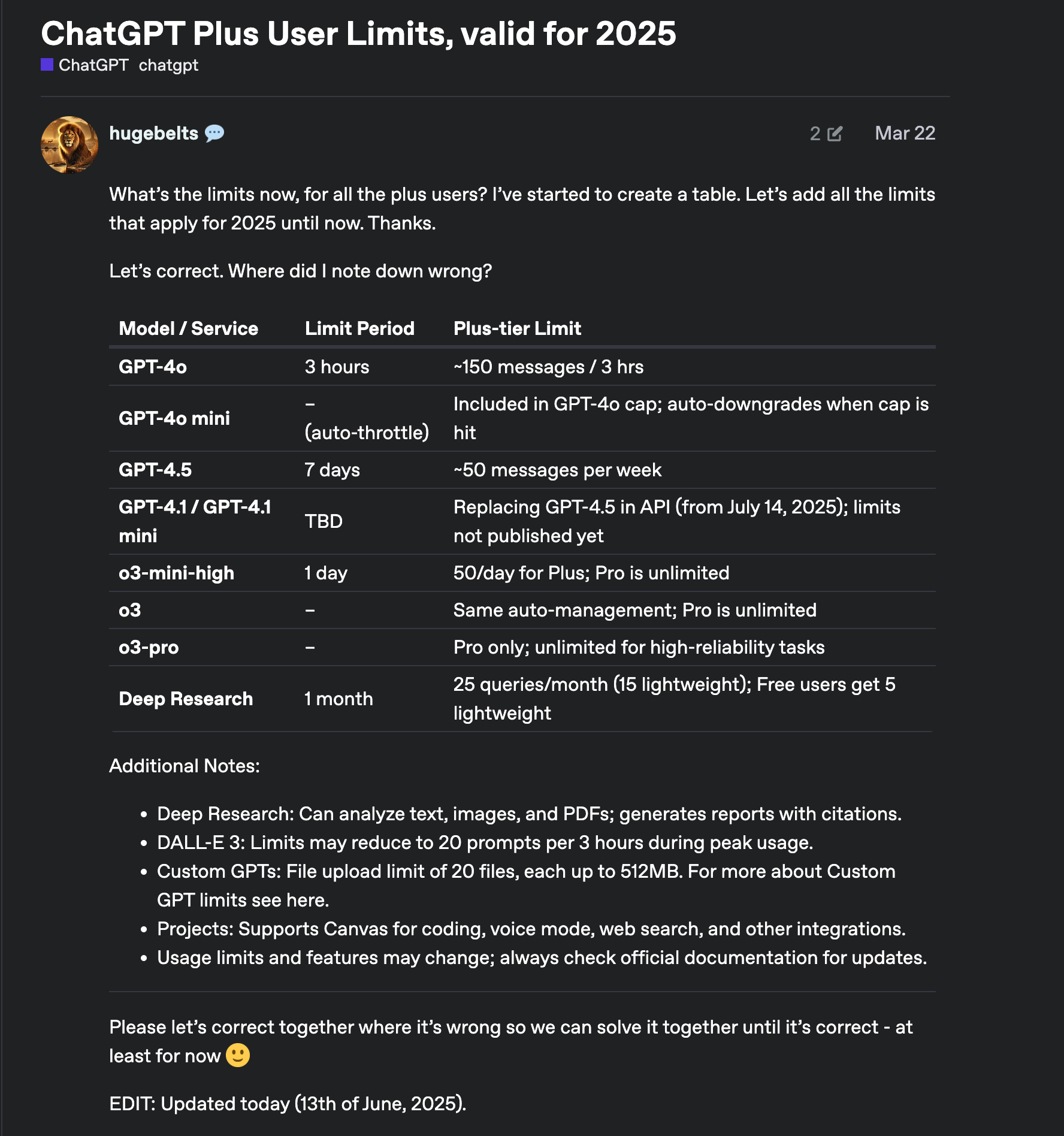 A community-maintained table from OpenAI's Developer Community forum showing ChatGPT Plus usage limits.
A community-maintained table from OpenAI's Developer Community forum showing ChatGPT Plus usage limits.
Your current Plus limits include:
- GPT-5: Up to 160 messages every 3 hours (temporary increase)
- DALL-E 3: 50 images every 3 hours (rolling window)
- Legacy models: Separate limits for GPT-4o (~150 messages/3hrs) and others
The limits use rolling windows rather than daily resets. When you reach your GPT-5 limit, chats will switch to the mini version until the limit resets.
To check your usage:
- Look for usage indicators near model selection
- Check notifications about remaining messages
- Monitor countdown timers for limit resets
Enterprise plans offer the highest usage allowances, but still aren't unlimited. Business plans ($25-30/user/month) provide virtually unlimited GPT-5 messages subject to fair use policies.
Enterprise customers get comprehensive analytics to monitor team usage:
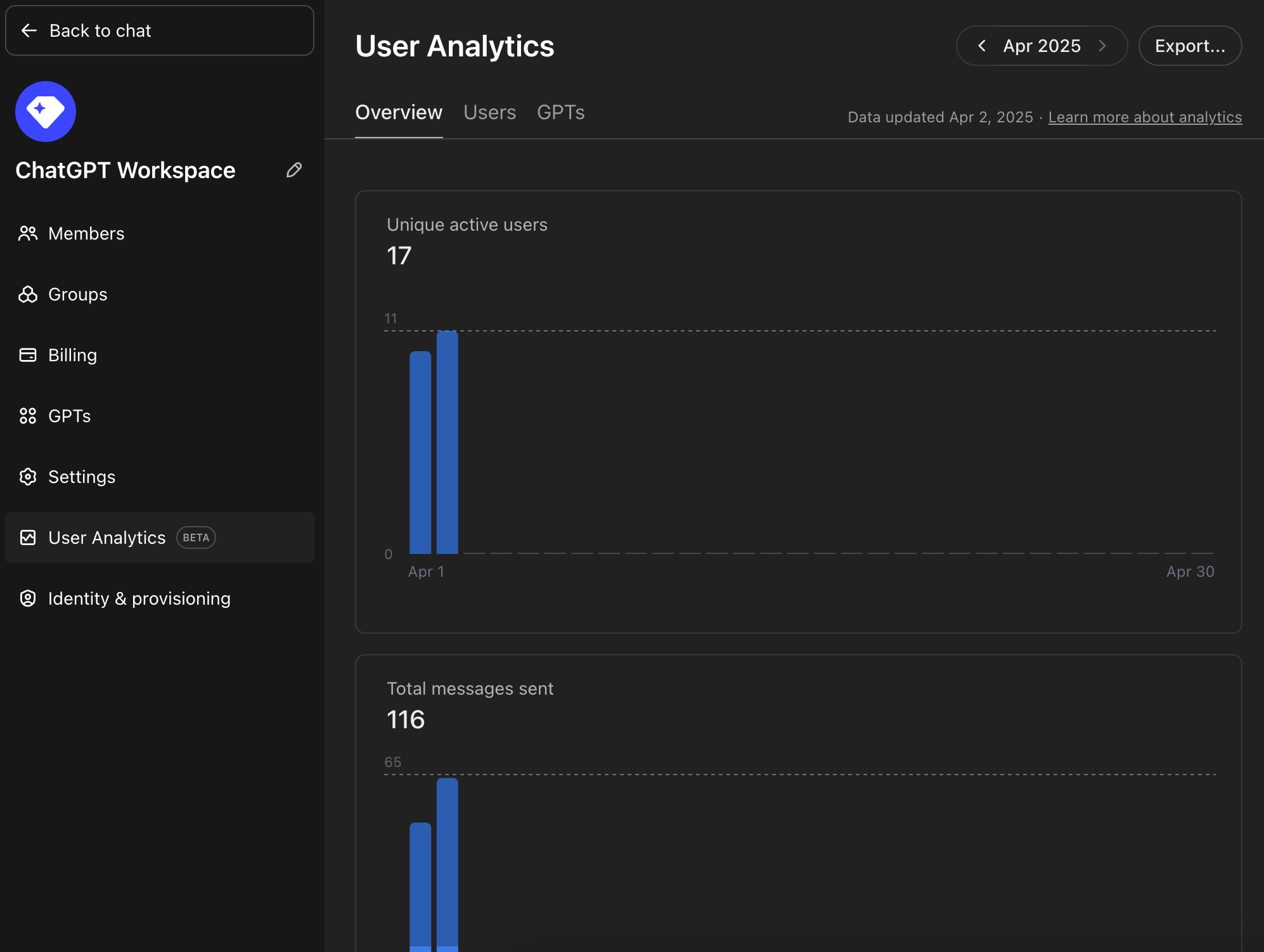 ChatGPT Workspace User Analytics dashboard
ChatGPT Workspace User Analytics dashboard
Your analytics dashboard shows:
- User activity tracking: Monitor adoption, engagement, and usage trends across your workspace
- Usage patterns: Track team adoption and power users
- Export capabilities: Download weekly or monthly reports
Team/Enterprise plans are still subject to usage policies for policy enforcement, though limits are much more generous than individual plans.

With open-source models like DeepSeek v3, Qwen3, and GPT-OSS you can avoid usage restrictions entirely.
You choose:
- The exact model configuration and parameters
- The hardware it runs on
- Usage patterns (unlimited messages, custom batching)
- Complete data privacy (everything stays on your infrastructure)
- Performance optimization (latency, throughput, cost per token)
Let's compare self-hosting DeepSeek v3 on Northflank with ChatGPT's pricing.
- A100 (80GB): $1.76/hour
- H100 (80GB): $2.74/hour
- H200 (141GB): $3.14/hour
- B200 (180GB): $5.87/hour
Let's walk through DeepSeek v3 as an example:
Step 1: Calculate hourly GPU cost
- Requires: 8 × H200 GPUs
- Cost: 8 × $3.14 = $25.12/hour
Step 2: Convert to cost per second
- $25.12 ÷ 3,600 seconds = $0.006978/second
Step 3: Measure processing speeds
- Input tokens: 7,934 tokens/second
- Output tokens: 993 tokens/second
Step 4: Calculate per-token costs
- Input: $0.006978 ÷ 7,934 = $0.0000008795 per token
- Output: $0.006978 ÷ 993 = $0.0000070265 per token
Step 5: Scale to millions
- Input: $0.88 per million tokens
- Output: $7.03 per million tokens
Compared to ChatGPT GPT-4o ($2.50 input, $10.00 output):
- DeepSeek v3 is 2.8x cheaper for input
- DeepSeek v3 is 1.4x cheaper for output
- Plus: No usage limits and complete data control
Step 1: Choose your model
- For ChatGPT replacement: DeepSeek v3 or GPT-OSS 120B
- For reasoning: DeepSeek R1 or Qwen3 Thinking
- For coding: Qwen3 Coder
- For speed: Qwen3 30B variants
Step 2: Pick your deployment method
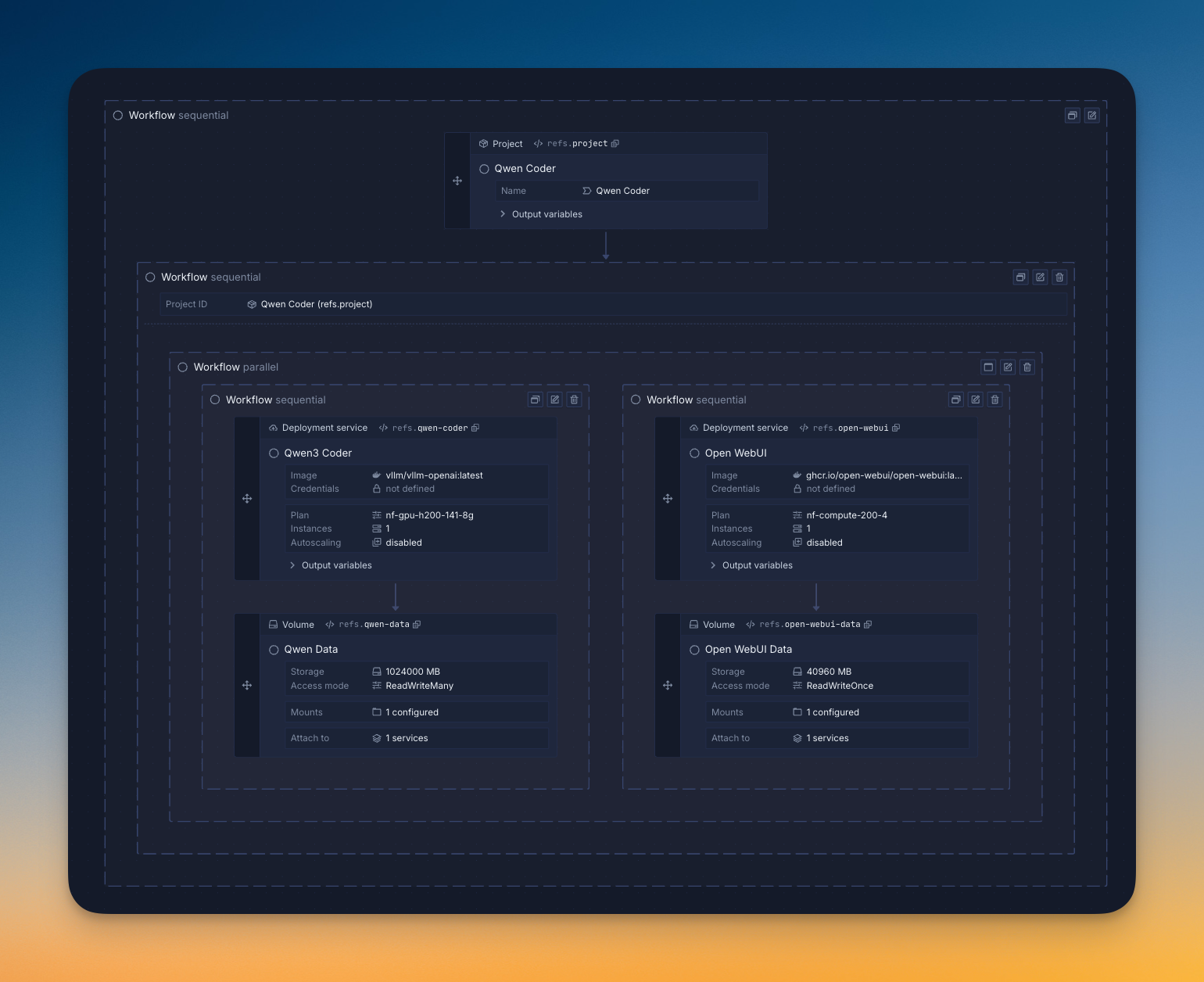
- One-click templates: Deploy popular models with pre-configured settings in minutes
- Manual setup: Full control over model parameters and GPU selection
- Bring Your Own Cloud: Use your existing AWS/GCP/Azure account for maximum control
Step 3: Select your GPU
- Small models (< 50GB): 1-2 GPUs
- Medium models (50-100GB): 2-4 GPUs
- Large models (100GB+): 8+ GPUs
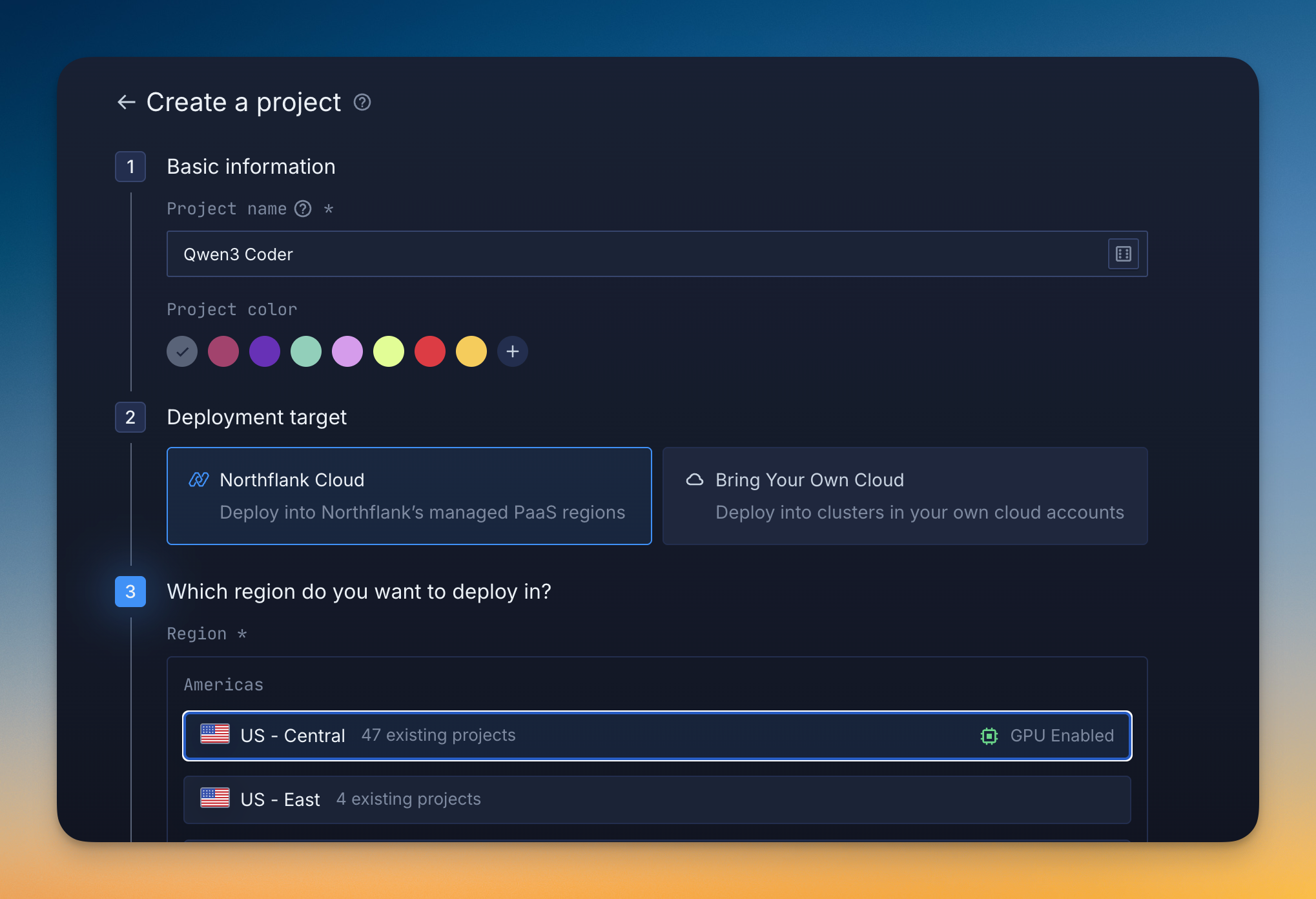
- Sign up for a Northflank account
- Create a GPU-enabled project in your preferred region
- Deploy from a template or create a custom vLLM service
- Access via API using OpenAI-compatible endpoints
Most models are serving requests within 30 minutes of starting deployment.
- A Northflank account (free to create)
- Basic understanding of APIs (for integration)
- Your use case requirements (tokens/month, latency needs)
It’s time to get rid of ChatGPT usage limits and take control of your AI infrastructure.
Deploy your first model on Northflank and experience unlimited AI access with complete privacy and control.
Our templates make deployment as simple as clicking "launch" with no GPU expertise required. You get:
- No usage limits: Process unlimited requests
- Complete data privacy: Everything stays on your infrastructure
- Predictable costs: Pay only for compute, not per-token
- Full control: Customize models for your specific needs
Learn more:
For detailed setup guides and model recommendations, reach out to the Northflank team.

