

What is machine learning infrastructure?
Quick summary:
Machine learning infrastructure encompasses the entire technology stack and resources you need to develop, train, deploy, and manage ML models in production.
It includes compute resources (CPUs, GPUs), storage systems, orchestration platforms, CI/CD pipelines, monitoring tools, and APIs for model serving.
Modern ML infrastructure platforms like Northflank provide end-to-end solutions with GPU orchestration, automated job scheduling, scalable storage, and integrated CI/CD workflows to simplify and optimize your entire ML lifecycle from experimentation to production deployment.
Machine learning infrastructure has become the backbone of successful AI initiatives.
When you build a production ML system, you'll find that only about 10% of your code is the machine learning model itself.
The other 90% is infrastructure code that handles data processing, deployment, monitoring, and serving your models to users.
This means your modern ML infrastructure must handle everything from data ingestion and feature engineering to model serving and performance monitoring.
As organizations increasingly rely on AI for competitive advantage, understanding and implementing reliable ML infrastructure has become important for your engineering team when working with machine learning at scale.
In this guide, we'll cover:
- Best practices for managing your ML infrastructure
- GPU orchestration capabilities for your AI workloads
- Setting up CI/CD pipelines for your machine learning models
- How to choose the most scalable ML infrastructure vendor
- The core architectural layers of ML infrastructure systems
- How cloud infrastructure can speed up your development workflow
- What infrastructure components you need for your ML projects
Your ML infrastructure requirements span across eight core components that work together to support your entire machine learning lifecycle.
Each component serves a specific purpose while integrating naturally with others to create a comprehensive ML platform for your team.
Let's break down what you need:
Computing resources form the foundation of your ML infrastructure.
When you're training modern deep learning models, you'll need significant computational power, particularly GPU resources for neural network training and inference.
Platforms like Northflank provide you with on-demand access to NVIDIA H100 and B200 GPUs across multiple cloud providers.
So, this enables your team to scale compute resources based on workload demands without managing underlying hardware complexity.
Data management and storage systems handle the massive datasets you'll need for ML model training.
This includes data lakes for your raw storage, databases for structured data, and feature stores for processed features.
Your data management requires both high-performance storage for training workloads and cost-effective storage for long-term data retention.
Orchestration and scheduling tools coordinate your complex ML workflows, from data preprocessing to model training and deployment.
Modern platforms provide you with Kubernetes-based orchestration that can automatically schedule jobs, manage resource allocation, and handle failures with ease.
Northflank's job scheduling capabilities allow your team to run batch training jobs, hyperparameter tuning experiments, and inference pipelines with automated resource management.
Model development environments provide your data scientists with the tools needed for experimentation and model building.
This includes Jupyter notebooks, development frameworks like TensorFlow and PyTorch, and experiment tracking systems.
Cloud-based development environments enable collaborative work while giving you access to powerful compute resources.
This is where platforms like Northflank come in.
Rather than assembling these components from different vendors, Northflank provides you with a unified platform that handles compute orchestration, job scheduling, storage management, and development environments through a single interface.
Now that you understand the core infrastructure components you need, let's look at how cloud infrastructure can support your ML development process. See some of the key benefits you'll get:
- Elastic scaling: provision resources based on your current needs
- Multi-cloud flexibility: prevent vendor lock-in across providers
- Managed services: reduce operational complexity
Cloud infrastructure improves your ML development by providing scalable, on-demand resources that reduce the complexity of managing physical hardware.
Think about traditional on-premises setups for a moment.
They require significant upfront investment in GPUs, storage systems, and networking equipment, along with ongoing maintenance and upgrade costs. Cloud-based ML infrastructure provides you with a better approach with these three core advantages.
 Cloud ML infrastructure workflow: from development to production
Cloud ML infrastructure workflow: from development to production
This is where Northflank's multi-cloud approach becomes valuable for your team. The platform supports deployment across AWS, GCP, Azure, Civo and Oracle Cloud, allowing you to leverage the best GPU offerings from each provider.
So, rather than dedicating your engineering resources to Kubernetes cluster management and security patching, you can focus on your model development and business logic.
Northflank provides you with a managed Kubernetes experience that includes built-in CI/CD, monitoring, and security features, so you get all the infrastructure benefits without the operational complexity.
See how Weights uses Northflank to scale to millions of users without a DevOps team
Now that you understand how cloud infrastructure supports your development, let's go into the architectural layers that make up a complete ML system.
 The 4 core layers of modern ML infrastructure
The 4 core layers of modern ML infrastructure
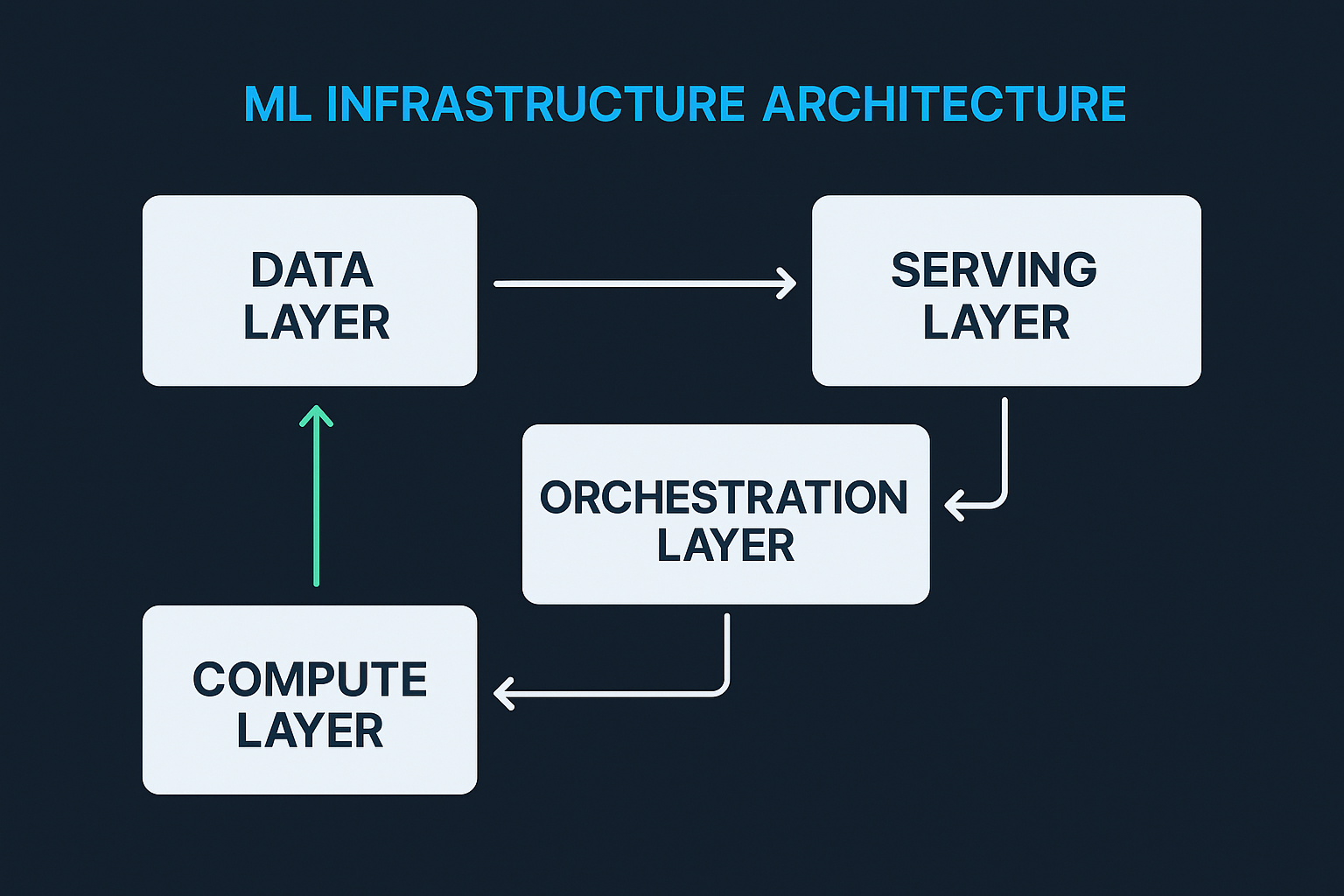
Your ML infrastructure architecture consists of four interconnected layers that work together to take your models from development to production.
These are the core layers you need:
- Data layer: Manages storage, processing, and access for your datasets, feature stores, and experiment metadata.
- Compute layer: Provides CPU and GPU resources with auto-scaling capabilities for training and inference workloads
- Orchestration layer: Coordinates CI/CD pipelines, job scheduling, ML testing and evaluation pipelines, and workflow management across your ML lifecycle
- Serving layer: Handles model deployment, API endpoints, and inference systems for real-time and batch predictions
Each layer serves a specific purpose while integrating with the others to create a comprehensive platform that can scale from your research prototypes to production applications serving millions of users.
With your architecture layers defined, the next question is choosing the right vendor for your scalable ML infrastructure.
The scalability of ML infrastructure depends on four key factors: compute flexibility, storage performance, orchestration capabilities, and operational simplicity.
You have two main vendor categories to consider:
- Traditional cloud providers (AWS, GCP, Azure): They provide comprehensive ML services, but require significant expertise to configure and manage effectively.
- Specialized ML platforms: They focus specifically on machine learning workflows with opinionated solutions that reduce complexity while maintaining flexibility.
The most scalable solutions provide automatic resource management, cost optimization through spot instances, and automated scaling from development to production environments.
Northflank's approach centers on Kubernetes orchestration combined with multi-cloud flexibility.
You can deploy workloads across multiple cloud providers (AWS, Azure, GCP, Civo, Oracle), access different GPU types based on your workload requirements, and scale resources automatically based on demand.
Once you've chosen your infrastructure vendor, you'll need to set up CI/CD pipelines for your ML models.
Setting up effective CI/CD for ML models requires adapting traditional software deployment practices to handle the unique requirements of machine learning workflows.
Your ML CI/CD pipeline needs four key components:
- Model versioning and artifact management: Track model artifacts, training data versions, configuration parameters, and prompt versions (for LLM applications) automatically.
- Automated testing: Include model performance validation, data quality checks, and accuracy regression tests beyond traditional unit tests.
- Deployment automation: Handle containerization, serving infrastructure configuration, and gradual rollout strategies like canary deployments
- Environment management: Ensure consistency across development, staging, and production environments
Compared to traditional software, your ML models depend on both code and data. So, they require specialized versioning systems that maintain lineage between model versions and their training data.
Modern platforms like Northflank provide integrated CI/CD capabilities that automatically build, test, and deploy your models based on Git commits or training completion events.
This handles the complexity of ML-specific deployment requirements.
With your CI/CD pipeline in place, you'll need reliable GPU orchestration to handle your AI workloads.
GPU orchestration for AI workloads requires sophisticated resource management capabilities that go beyond traditional CPU-based scheduling.
Your GPU orchestration system needs these core capabilities:
- Resource allocation and scheduling: Handle long-running training jobs, burst inference demands, and GPU sharing for smaller models
- Multi-GPU and distributed training support: Scale model training across multiple GPUs and nodes with complex communication patterns.
- Cost optimization through spot instances: Automatically migrate workloads when spot instances are reclaimed while maintaining training state
Modern AI applications demand high-performance GPU utilization, support for different GPU types, and automatic workload placement across multiple cloud providers.
Northflank's GPU orchestration includes automatic scheduling across NVIDIA H100 and B200 instances, support for GPU sharing across workloads, and optimized placement across multiple cloud providers.
The platform handles spot instance management automatically, providing cost optimization without requiring manual intervention from your development team.
With your GPU orchestration configured, let's cover some best practices for managing your ML infrastructure.
Successful ML infrastructure management requires balancing performance, cost, and operational complexity while maintaining the flexibility to adapt to changing requirements.
These are the four key areas to focus on:
- Resource optimization: Match workload characteristics to appropriate infrastructure and implement automated scaling policies to prevent over-provisioning
- Security and compliance: Implement proper access controls, encrypt data in transit and at rest, and maintain audit trails for regulatory compliance
- Monitoring and observability: Track both infrastructure metrics and ML-specific performance indicators like model performance and data quality
- Cost management: Use spot instances for fault-tolerant workloads and regularly review resource allocation patterns to identify optimization opportunities
Organizations that implement these best practices can scale their ML operations while controlling costs and maintaining system reliability.
Understanding the unique cost characteristics of ML workloads helps you implement appropriate optimization strategies across your entire infrastructure stack.
With these best practices in mind, selecting the right ML infrastructure platform requires careful consideration of your technical requirements and long-term scalability needs.
The ideal platform should provide comprehensive capabilities while remaining simple enough for your development team to adopt quickly.
Modern ML infrastructure platforms like Northflank provide end-to-end solutions that handle compute orchestration, storage management, CI/CD automation, and GPU scheduling through a single integrated platform.
This reduces operational complexity while providing the flexibility and performance needed for your demanding ML workloads.
Take the next step with Northflank. Get started today or book a demo to see how our platform can simplify and optimize your AI development workflow.


