

Top 9 AI hosting platforms for your stack in 2026
AI hosting has shifted from simple cloud infrastructure to sophisticated platforms that handle the complete AI development lifecycle.
If you're fine-tuning LLMs, deploying production inference APIs, or building full-stack AI applications, the right hosting platform can determine your project's success.
I'll break down the top nine (9) AI hosting platforms in 2026, comparing them based on performance, developer experience, pricing transparency, and production readiness.
1. Northflank - If you're building production AI applications, this complete platform gives you GPU orchestration, Git-based CI/CD, and BYOC support. Best overall choice when you need actual AI products, not demos.
Why I recommend Northflank: While other platforms only give you GPU access or model hosting, you get a complete development environment. You'll have production-grade infrastructure, transparent pricing, and the ability to deploy in your own cloud without the complexity of traditional providers or limitations of AI-only platforms.
2. AWS SageMaker - Perfect if you're already on AWS and need comprehensive MLOps. Amazon's platform provides end-to-end machine learning workflows and enterprise-grade features.
3. Google Cloud Vertex AI - Ideal if you're using TensorFlow or need TPU access. Google's unified ML platform excels with AutoML capabilities and tight ecosystem integration.
4. Hugging Face Inference Endpoints - Perfect if you're deploying open-source transformer models. Specialized platform that gets you from model to API fastest.
5. RunPod - Ideal if you're on a tight budget or experimenting. GPU cloud focused on simplicity and quick deployments for demos and testing.
6. Modal - Great if you're a Python developer who wants serverless AI. Platform handles scaling automatically with minimal configuration needed.
7. Replicate - Perfect if you're building generative AI demos or want to monetize models. Optimized for public model APIs and quick sharing.
8. Anyscale - Ideal if you're already using Ray or need distributed computing. Built for large-scale Python applications and complex workloads.
9. Baseten - Great if you prefer visual interfaces over code. UI-driven deployment with built-in monitoring for data science teams.
AI hosting refers to cloud infrastructure specifically designed to support your artificial intelligence and machine learning workloads.
While web hosting focuses on websites, AI hosting platforms give you specialized hardware (GPUs, TPUs), optimized software stacks, and tools tailored for training, fine-tuning, and deploying your AI models.
AI hosting goes beyond providing compute resources. When you're building AI applications, you need:
- GPU and TPU orchestration - for parallel processing and model training
- Model deployment pipelines - for serving your inference APIs at scale
- MLOps tools - for versioning, monitoring, and managing your model lifecycles
- Auto-scaling infrastructure - that adjusts resources based on your demand
- Integration with AI frameworks - like PyTorch, TensorFlow, and Hugging Face that you're already using
- Data management - for handling your large datasets and model weights
The main difference from web hosting is the focus on high-performance computing, specialized hardware access, and workflows designed around your unique AI development requirements, from experimentation to production deployment.
Now that you understand what AI hosting involves, here's what separates exceptional AI hosting platforms from the rest:
1. Latest GPU access: Support for NVIDIA H100, A100, L40S, and newer accelerators like AMD MI300X with fast provisioning and availability.
2. Production-ready workflows: Git-based deployments, preview environments, automated scaling, and proper CI/CD integration beyond raw compute.
3. Full-stack support: The ability to run databases, APIs, frontends, and background jobs alongside your AI workloads without platform switching.
4. Transparent pricing: Usage-based billing with no hidden fees, egress charges, or unexpected costs that can derail your project budgets.
5. Enterprise features: BYOC (Bring your own cloud) support, compliance certifications, audit trails, and security controls that meet your real-world requirements.
6. Developer experience: Intuitive interfaces, comprehensive documentation, and workflows that don't require a PhD in DevOps.
With these criteria in mind, let's compare how the top platforms measure up for your specific needs and use cases.
Why it's my top pick: Northflank goes beyond being another GPU provider. It's a complete platform designed for teams building production-ready AI applications. While competitors force you to choose between simplicity and control, Northflank delivers both.
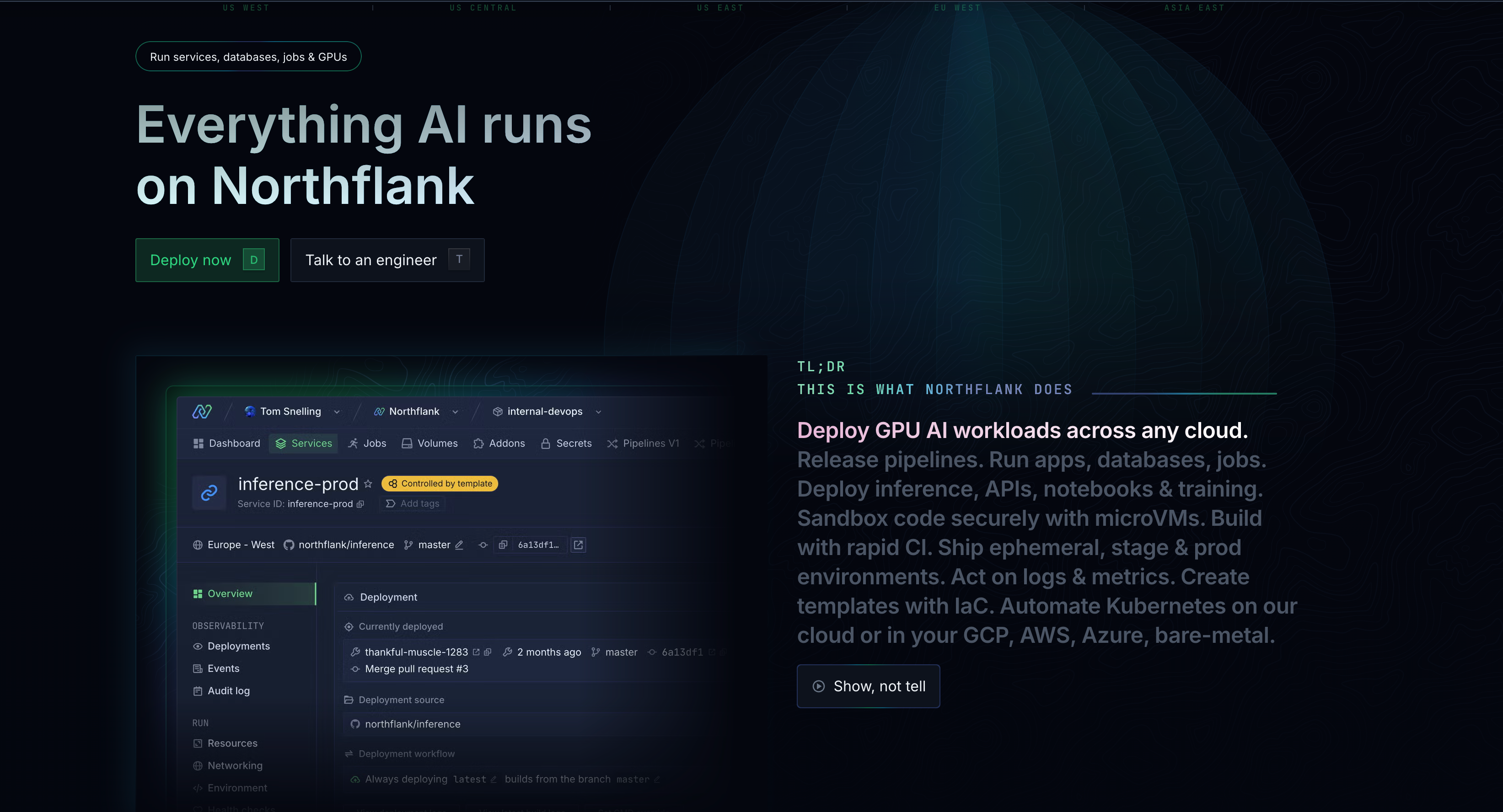
Some of the features of Northflank
- 18+ GPU types including NVIDIA H100, A100, B200, L40S, L4, AMD MI300X, and Habana Gaudi
- Bring Your Own Cloud (BYOC) support for AWS, GCP, Azure, Oracle Cloud, and bare metal
- Git-based CI/CD with automatic deployments and preview environments
- Full-stack orchestration - you can run databases, APIs, frontends, and AI workloads in one platform
- Transparent pricing starting at $1.42/hr for A100 40GB, $2.74/hr for H100
- Spot GPU optimization with automatic failover for up to 90% cost savings
- Enterprise security with isolated environments, secrets management, secure runtime, and compliance support
What you can build
- Fine-tuned LLM APIs with custom weights and optimized inference
- Full-stack AI applications with integrated databases and frontends
- Jupyter notebooks for research and experimentation
- Multi-model AI pipelines with orchestrated workflows
- Production ML services with proper monitoring and scaling
Some pricing info
🤑 Northflank pricing
- Free tier: Generous limits for testing and small projects
- CPU instances: Starting at $2.70/month ($0.0038/hr) for small workloads, scaling to production-grade dedicated instances
- GPU support: NVIDIA A100 40GB at $1.42/hr, A100 80GB at $1.76/hr, H100 at $2.74/hr, up to B200 at $5.87/hr
- Enterprise BYOC: Flat fees for clusters, vCPU, and memory on your infrastructure, no markup on your cloud costs
- Pricing calculator available to estimate costs before you start
- Fully self-serve platform, get started immediately without sales calls
- No hidden fees, egress charges, or surprise billing complexity
Why choose Northflank
- For startups: You get enterprise features without enterprise pricing. Scale from prototype to production without platform migration.
- For enterprises: Deploy in your own cloud infrastructure while maintaining centralized control and governance.
- For developers: Git-based workflows, preview environments, and zero DevOps overhead. Focus on building, not managing infrastructure.
Northflank solved the fundamental problem with AI hosting: you shouldn't need different platforms for AI workloads and everything else. With built-in CI/CD, GPU orchestration, and full-stack support, it's the only platform designed for teams building complete AI products.
See how Weights uses Northflank to build a GPU-optimized AI platform for millions of users in our detailed case study: Weights uses Northflank to scale to millions of users without a DevOps team.
Best for: Large organizations already invested in the AWS ecosystem who need comprehensive MLOps capabilities and enterprise-grade features.

Key features
- Comprehensive MLOps suite with SageMaker Studio, Pipelines, and Model Registry
- Managed Jupyter environments with pre-configured deep learning frameworks
- Multi-model endpoints for cost-efficient inference serving
- Built-in AutoML capabilities through SageMaker Autopilot
- Enterprise security with VPC support, encryption, and IAM integration
- Extensive GPU options including P4d instances with A100 GPUs
Strengths
- Mature platform with extensive documentation and community
- Deep AWS ecosystem integration (S3, Lambda, API Gateway)
- Strong enterprise features and compliance certifications
- Flexible pricing options including on-demand and reserved instances
Limitations
- Steep learning curve with complex pricing structure
- Vendor lock-in to AWS ecosystem
- Can be overkill for smaller teams or simple use cases
- Higher costs compared to specialized AI platforms
Best fit: Enterprise teams with existing AWS infrastructure who need comprehensive MLOps workflows and have dedicated ML engineering resources.
If you're evaluating AWS alternatives for AI workloads, see our guide on 7 best DigitalOcean GPU & Paperspace alternatives for AI workloads in 2026.
Best for: Teams working with TensorFlow, requiring TPU access, or building on Google's AI ecosystem.

Key features
- Native TPU support for efficient large-scale training
- AutoML capabilities for automated model development
- Vertex AI Workbench for collaborative notebook environments
- Model Garden with pre-trained models and solutions
- MLOps automation with Vertex AI Pipelines
- Tight Google integration with BigQuery, Dataflow, and other GCP services
Strengths
- Leading-edge AI research and tools
- High TPU performance for specific workloads
- AutoML and no-code solutions
- Competitive pricing for TPU workloads
Limitations
- Less mature than AWS for general enterprise needs
- Limited GPU variety compared to other platforms
- Smaller ecosystem of third-party integrations
- Can be complex for teams not familiar with Google Cloud
Best fit: Research teams, organizations using TensorFlow extensively, or projects that can benefit from TPU-optimized workloads.
If you're looking for Google Cloud alternatives, see our comparison in 7 best AI cloud providers for full-stack AI/ML apps.
Best for: Teams focused on deploying pre-trained transformer models quickly without infrastructure management.
Key features
- Massive model library with 400,000+ pre-trained models
- One-click deployment for any model from the Hugging Face Hub
- Auto-scaling inference endpoints with usage-based pricing
- Custom model support for fine-tuned and private models
- Community ecosystem with extensive model documentation and examples
- Integration tools for popular ML frameworks and platforms
Strengths
- Fastest path from model to production API
- Good for transformer-based models
- Community and ecosystem
- Transparent, usage-based pricing
Limitations
- Limited to inference workloads (no training capabilities)
- Less suitable for full-stack applications
- Restricted to Hugging Face ecosystem
- No infrastructure customization options
Best fit: Teams deploying open-source transformer models who want to minimize infrastructure complexity and time-to-deployment.
If you're considering Hugging Face alternatives, see our comprehensive guide: 7 best Hugging Face alternatives in 2026: Model serving, fine-tuning & full-stack deployment.
Best for: Developers, researchers, and small teams who need affordable GPU access for experimentation and lightweight workloads.

Key features
- Low-cost GPU access with community and dedicated options
- Serverless and pod-based deployments for different use cases
- Pre-configured templates for popular AI frameworks
- Simple pricing model with per-minute billing
- Docker-based deployments for easy containerization
- Community marketplace for shared GPU resources
Strengths
- Very affordable pricing, especially for experimentation
- Simple setup and deployment process
- Good selection of pre-configured environments
- Active community and support
Limitations
- Limited production features (no CI/CD, monitoring, etc.)
- Variable performance on community instances
- No enterprise features or BYOC support
- Basic scaling and orchestration capabilities
Best fit: Individual developers, students, or small teams experimenting with AI models who prioritize cost over production features.
For more RunPod alternatives, see our detailed analysis: RunPod alternatives for AI/ML deployment beyond just a container.
Best for: Python developers who want to deploy AI workloads with minimal configuration and automatic scaling.

Key features
- Python-native deployment - just write Python code and deploy
- Automatic scaling from zero to thousands of containers
- GPU support with NVIDIA A100, H100, and other accelerators
- Serverless execution with pay-per-use billing
- Container orchestration with built-in dependency management
- Distributed computing support for large-scale workloads
Strengths
- Simple deployment process for Python workflows
- Great for batch jobs and async processing
- Cost-effective serverless pricing model
- Community and documentation
- Limited to Python-based workloads
- Less suitable for always-on services
- No full-stack application support
- Limited customization options
Best fit: Python developers building AI workflows, batch processing jobs, or serverless inference APIs who want minimal infrastructure management.
If you're evaluating Modal alternatives, check out: 6 best Modal alternatives for ML, LLMs, and AI app deployment.
Best for: Developers who want to quickly deploy and monetize generative AI models with minimal setup.

Key features
- One-click model deployment from GitHub repositories
- Model monetization with built-in billing and API management
- Public model gallery with thousands of pre-trained models
- Custom model support for fine-tuned and private models
- API-first design with simple REST endpoints
- Community ecosystem with model sharing and discovery
Strengths
- Fastest path from model to public API
- Built-in monetization features
- Excellent for generative AI demos
- Strong community of model creators
Limitations
- Focused primarily on demos and public APIs
- Limited enterprise features
- No full application deployment support
- Less suitable for private, production workloads
Best fit: Indie developers, researchers, or teams building generative AI demos who want to quickly share and monetize their models.
For Replicate alternatives, see our guide: 6 best Replicate alternatives for ML, LLMs, and AI app deployment.
Best for: Teams building large-scale distributed AI workloads using the Ray ecosystem.

Key features
- Ray-native platform built for distributed Python applications
- Auto-scaling clusters with intelligent resource management
- Distributed training support for large models and datasets
- MLOps integration with experiment tracking and model management
- Multi-cloud support across AWS, GCP, and Azure
- Production serving with Ray Serve for model deployment
Strengths
- Great for distributed computing workloads
- Ray ecosystem integration
- Good support for large-scale training
- Flexible deployment options
Limitations
- Requires Ray framework knowledge
- Can be complex for simple use cases
- Less suitable for non-distributed workloads
- Limited full-stack application support
Best fit: ML engineers and data scientists building large-scale distributed AI systems who are already using or want to adopt the Ray ecosystem.
If you're looking for Anyscale alternatives, see: Top Anyscale alternatives for AI/ML model deployment.
Best for: Data science teams who want a visual interface for deploying and monitoring ML models without deep infrastructure knowledge.

Key features
- Visual deployment interface with drag-and-drop model management
- Built-in monitoring with performance metrics and alerting
- Auto-scaling inference with load balancing and traffic management
- Model versioning with A/B testing capabilities
- Integration support for popular ML frameworks and tools
- Team collaboration features with shared workspaces
Strengths
- User-friendly interface for non-DevOps teams
- Good monitoring and observability features
- Model management capabilities
- Reasonable pricing for small to medium workloads
Limitations
- Limited customization options
- Less suitable for complex deployment scenarios
- No full-stack application support
- Smaller ecosystem compared to major platforms
Best fit: Data science teams who want to focus on model development rather than infrastructure management and prefer visual interfaces over code-based deployments.
For Baseten alternatives, check out: Top Baseten alternatives for AI/ML model deployment.
Your choice of AI hosting platforms in 2026 is defined by those that treat AI workloads as part of your complete application stack, rather than isolated compute tasks. The winners provide:
- Unified workflows that handle both AI and non-AI services
- Transparent, predictable pricing without vendor lock-in
- Production-grade features built for real applications, not demos
- Developer-first experiences that reduce operational overhead
Northflank represents all of this - a platform built for the reality of how teams actively build and deploy AI applications. The platform delivers the complete package for teams serious about putting AI into production.
See how Northflank compares for your use case: Try it for free or book a demo to check out how the platform is built for the next generation of AI applications.
Based on common questions from teams evaluating AI hosting platforms, here are the key considerations:
Self-hosting AI makes sense for organizations with strict data privacy, regulatory compliance, or high-volume predictable workloads, but comes with challenges like high GPU costs ($10K-$40K+ per unit), infrastructure complexity, and operational overhead. Platforms like Northflank offer BYOC deployment as a middle ground, letting you run in your own cloud account while getting managed platform benefits.
The best AI platform depends on your use case: Northflank for production AI applications, AWS SageMaker for enterprise MLOps, Google Vertex AI for research, and Hugging Face for quick model deployment. For most teams building complete AI products, Northflank offers the best balance of features, pricing, and developer experience.
Yes, you can self-host AI using open-source frameworks like Kubeflow, MLflow, BentoML, and Ray for different aspects of ML workflows. Many teams prefer hybrid approaches where Northflank's BYOC option provides a managed platform experience while keeping workloads in your own cloud infrastructure.
You can check out these additional guides and comparisons for your specific AI hosting needs:
- How to deploy machine learning models: Step-by-step guide to ML model deployment in production
- What is AI infrastructure? Key components & how to build your stack
- RunPod alternatives for AI/ML deployment beyond just a container
- AWS SageMaker alternatives: Top 6 platforms for MLOps in 2026
- Self-host vLLM in your own cloud account with Northflank BYOC
- Deploy DeepSeek R1 with vLLM on Northflank
- Top AI PaaS platforms in 2026 for model deployment, fine-tuning & full-stack apps


