

What is GPU-as-a-Service (GPUaaS)? Use cases and leading providers
Summary: GPU-as-a-Service lets you access powerful graphics processing units through the cloud without buying expensive hardware. Platforms like Northflank go beyond basic GPU rental by including CI/CD pipelines, monitoring, and deployment tools in one integrated solution.
Need GPUaaS capacity for your team? If you're evaluating GPUaaS for production workloads and have specific capacity requirements, request GPU capacity here.
The rise of AI and machine learning has created a massive demand for GPU compute power.
Every day, organizations are demanding flexible access to high-performance graphics processing units without the capital investment and operational complexity of managing physical hardware.
We'll cover:
- What is GPU-as-a-Service, and how does it work
- What are the benefits of GPU-as-a-service
- Why you'd choose GPU-as-a-service over buying your own hardware
- How platforms like Northflank provide more than basic compute
- How to select the right GPU-as-a-service provider for your needs
- Use cases and applications of GPUaaS
- What makes some platforms better than others
GPU-as-a-Service (GPUaaS) is a cloud computing model that allows you to deploy GPU resources in the cloud rather than purchasing and maintaining your own hardware.
The concept is straightforward:
Rather than spending $40,000+ on a high-end GPU like the NVIDIA H100, you access the same computational power through remote servers. You pay only for what you use, whether that's hours, days, or months.
There are several reasons why GPUs are vital for your projects. Let’s look at some of them:
- Parallel processing power: GPUs have thousands of small cores that work simultaneously
- AI optimization: Perfect for training machine learning models and running inference
- Speed: Tasks that take hours on CPUs can be completed in minutes on GPUs
- Performance: Handle massive datasets and complex computations with ease
This approach resembles renting a high-performance vehicle rather than purchasing one: you access the performance when needed without the massive upfront cost or ongoing maintenance responsibilities.
What is the difference from traditional cloud computing? These platforms are specifically designed for AI workloads, with pre-configured environments and tools that enable immediate productivity.
Understanding what GPUaaS is leads naturally to finding out why it has become the preferred solution for AI projects.
If you used to worry about $10,000-$100,000+ hardware purchases, you don't have to anymore. With GPUaaS, you only pay for the compute time you actively use.
You also avoid all the hidden costs that come with owning hardware, like electricity bills, cooling systems, repairs, and upgrades.
This converts your capital expenses into predictable operational expenses, making budgeting much simpler.
You can add more GPUs during intensive training phases, then scale down for inference workloads.
Choose from different GPU types based on your specific needs, work from anywhere with an internet connection, and never worry about predicting future hardware requirements.
You can finally start your AI projects within minutes rather than waiting weeks for hardware procurement.
Pre-configured environments let you skip complex setup processes, and you always have access to the latest GPU technology without managing upgrades.
The result is that you gain enterprise-grade GPU performance without the operational complexity typically associated with it.
Most GPU providers offer raw compute power and leave you to handle everything else. Northflank takes a comprehensive approach.
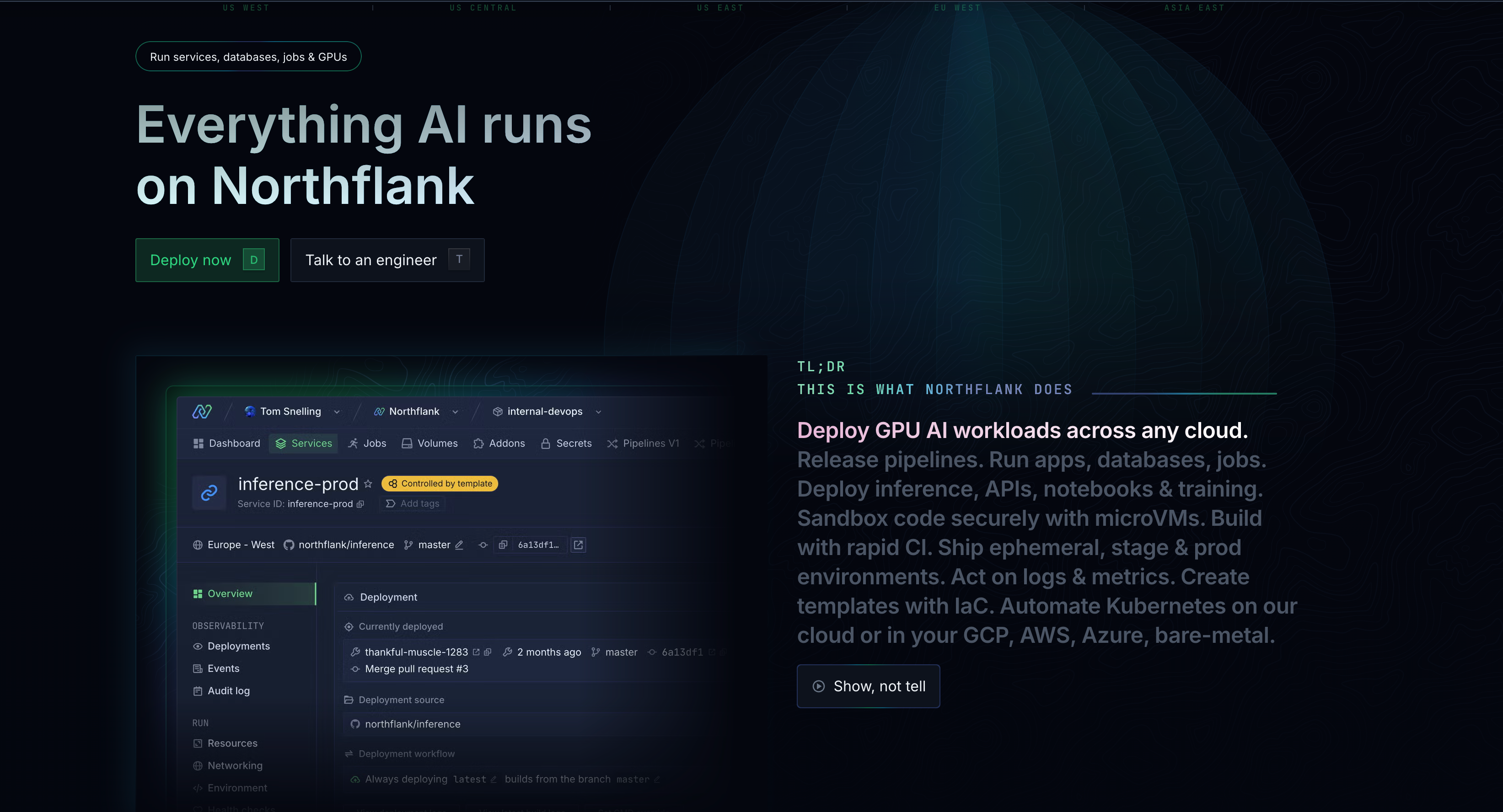
Let’s see how.
While other providers offer bare GPU instances, Northflank provides a complete platform that handles your entire AI development lifecycle. This includes:
-
Integrated CI/CD:
Automatically build, test, and deploy your models as you update code. See Continuous integration and delivery on Northflank.
-
Container orchestration:
Scale your applications automatically based on demand. See how Northflank handles container orchestration.
-
Real-time monitoring:
Track model performance, resource usage, and system health. See how Northflank provides observability tooling to monitor and ensure your applications and microservices are available.
-
Secrets management:
Securely handle API keys, database connections, and sensitive data. See the various ways Northflank handles security
-
Environment management:
Manage development, staging, and production environments. See how to set up a preview environment and this guide on ”Dev, QA, preview, test, staging, and production environments.”
Well, I know you’re already asking. So to give you a quick answer:
Rather than managing multiple tools and services, you work within one platform. Using Northflank’s approach provides you with:
- Faster deployment times (minutes rather than hours)
- Reduced operational complexity
- Better security through integrated access controls
- Lower total cost of ownership
Then there’s the framework and template support:
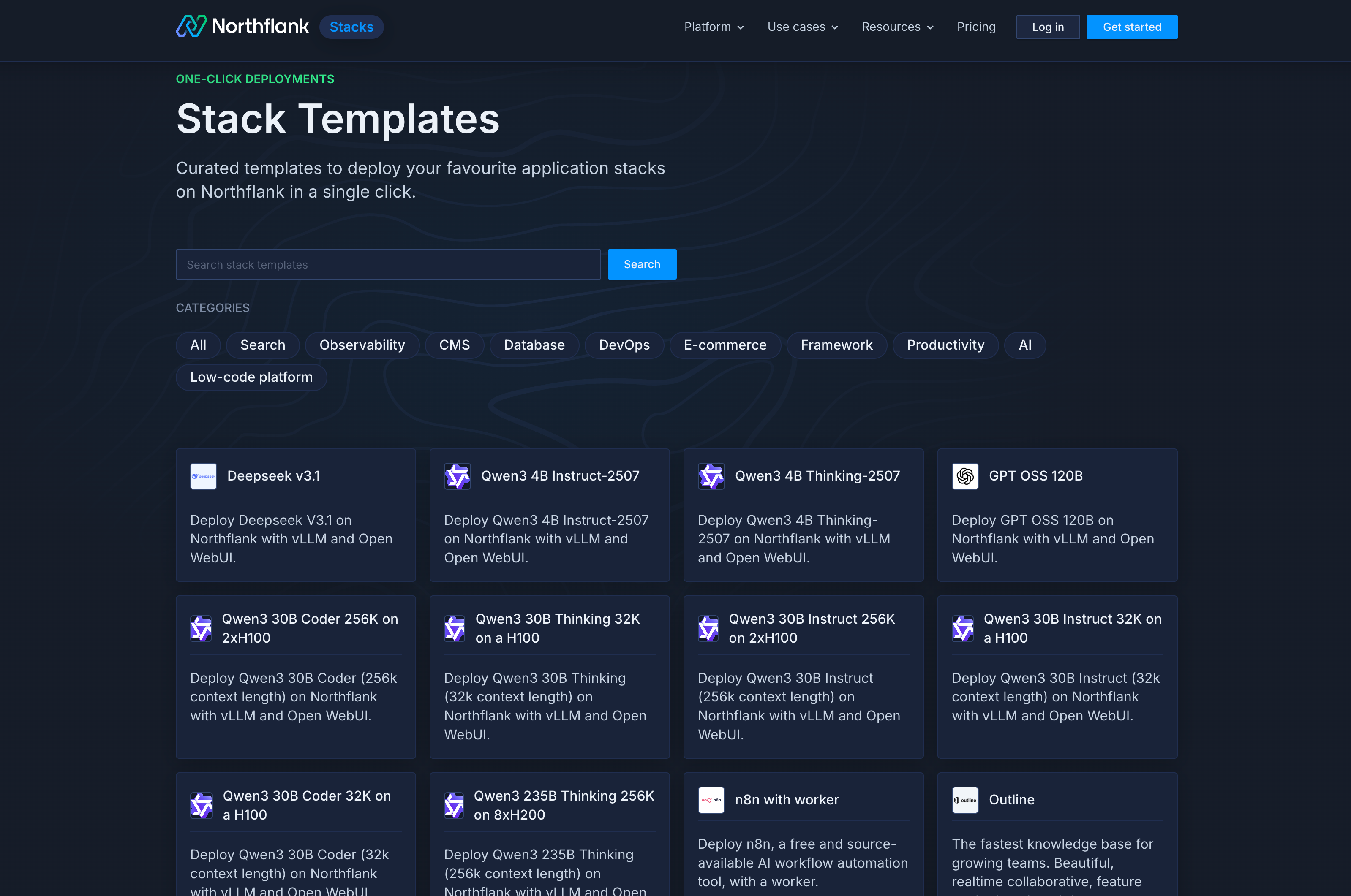
- One-click AI stacks: Pre-built templates for LLM deployment like Deepseek v3.1, Qwen3 models, and vLLM OpenAI at northflank.com/stacks
- Step-by-step guides: Including AI observability with Langfuse and AI workflow automation with n8n at northflank.com/guides
- Jupyter Notebook templates: Ready-to-deploy on AWS, GCP, and Azure
- AI development tools: Templates for Chroma vector database, Mojo Playground, and more
- Custom environment support
The result is that you can finally focus on building your AI applications rather than managing infrastructure complexity.
Understanding the competitive market helps you make informed decisions about which provider suits your needs.
| Provider | Strengths | Best For |
|---|---|---|
| Northflank | GPU + full deployment platform, integrated CI/CD | Teams wanting complete simple development workflow |
| AWS | Largest infrastructure, extensive integrations | Enterprise applications, existing AWS users |
| Microsoft Azure | Robust enterprise focus, Office 365 integration | Corporate environments, hybrid cloud |
| Google Cloud | Advanced AI/ML services, competitive pricing | Data analytics, research projects |
| NVIDIA DGX Cloud | Latest hardware, optimized performance | High-performance AI training |
While most hyperscalers like GCP and AWS offer reliable infrastructure, their pricing is often geared toward enterprises with high minimum spend commitments.
For smaller teams or startups, platforms like Northflank offer much more competitive, usage-based pricing without long-term contracts, while still providing access to top-tier GPUs and enterprise-grade features. And it is still very reliable.
The GPUaaS market continues to develop at a pace. While hyperscale providers (AWS, Azure, Google) dominate in overall size, specialized providers often offer:
- Better pricing for GPU-intensive workloads
- More flexible terms and configurations
- Faster access to new GPU architectures
- Specialized support for AI workflows
For most AI development teams, Northflank provides the optimal balance of GPU performance and development efficiency.
Plus, if you prefer specific cloud infrastructure, you can deploy Northflank on your preferred provider: AWS, Azure, or GCP, while accessing NVIDIA GPUs and other premium GPU options across all platforms.
This gives you the best of both worlds: your preferred cloud infrastructure with Northflank's integrated development platform.
Also, keep these factors in mind when choosing:
- Development workflow integration: Northflank's built-in CI/CD and monitoring vs. managing separate tools
- Time-to-deployment: Minutes with Northflank's templates vs. hours with manual setup
- Total cost of ownership: Integrated platform costs vs. multiple service subscriptions
- Team productivity: Focus on AI development vs. infrastructure management
- Cloud flexibility: Use your existing cloud relationships while gaining platform benefits
The "largest" doesn't always mean the "best fit" - for AI development teams prioritizing speed and simplicity, Northflank's comprehensive platform often delivers better value than raw compute alone.
Choosing the wrong provider can waste months of work and thousands of dollars. The good thing now is that you can avoid common pitfalls by focusing on what majorly impacts your projects.
Most teams make the mistake of comparing only hourly GPU rates.
However, the main cost also includes data transfer fees, storage charges, and the time your team spends troubleshooting complex setups.
A "cheap" provider that takes weeks to configure often costs more than a premium platform you can deploy in minutes.
Start with these questions: Do you need B200 for training large models, or will A100s handle your inference workloads? Can the platform integrate with your existing development tools? Will your team be able to use it productively?
You can also use this quick evaluation checklist:
- Performance match: GPU types and memory for your specific models
- True total cost: All fees included, not just headline rates
- Integration ease: Works with your current tools and workflows
- Team productivity: Documentation and support quality
- Reliability: Uptime guarantees and technical support response
Test with a small project first. The provider that gets you productive fastest usually delivers the best long-term value.
Getting your first GPU instance running is easy. Using it cost-effectively while maintaining productivity? That requires some strategy.
The biggest mistake new users make is treating GPUaaS like their local development machine. They spin up expensive H100 instances for debugging code, leave them running overnight, or transfer massive datasets repeatedly because they didn't plan their workflow.
Smart teams start differently. They begin with pre-configured environments and familiar tools like Jupyter notebooks, test with small datasets first, and keep their data close to compute resources to avoid transfer fees.
Monitor GPU utilization closely; if you're not reaching 80%+ during training, you're likely overpaying.
It’s like renting a sports car - you don't leave the engine running while parked, and you don't use it for grocery shopping.
Use spot instances for training jobs that can handle interruptions, scale down during development phases, and schedule heavy workloads during off-peak hours when rates are lower.
The most successful teams treat GPUaaS as part of a larger workflow.
They version control everything, use containers for consistent deployments, and implement monitoring to catch stuck training jobs early.
So, start small, measure your actual usage patterns, and optimize based on real data rather than assumptions.
Now that you know how to use GPUaaS successfully, let's look at where it makes the biggest impact. GPUaaS works best when you need substantial computational power but can't justify buying expensive hardware.
1. AI model training: This is the obvious winner. A startup can access $100,000 worth of GPU hardware for a few thousand dollars during their 2-week training cycle. From building computer vision systems to training language models or developing recommendation engines, GPUaaS lets you experiment without massive upfront costs.
2. Production deployment: Your trained models can auto-scale during traffic spikes, serve users globally with low latency, and you only pay for actual inference requests. No need to provision for peak loads year-round.
3. Data processing and research: Financial firms use GPUs for risk modeling, scientists run weather simulations, and academic teams access hardware that would otherwise be impossible to afford.
4. Creative applications: 3D rendering, video processing, and AI-generated content also benefit from on-demand GPU access.
The pattern is clear: GPUaaS works best for workloads that are computationally intensive but intermittent. If you need GPUs 24/7 for months, buying might make sense. For everything else, the flexibility and cost savings of GPUaaS usually win.
You've seen how GPUaaS works, compared the providers, and learned the best practices. Now it's time to make your choice.
The decision comes down to this:
Do you want just GPU compute, or do you want a complete development platform? Most teams quickly realize that managing separate tools for deployment, monitoring, and scaling costs more time and money than an integrated solution.
Your next steps:
Start with a small test project to validate performance and costs. Define your budget and technical requirements. Then choose a platform that can grow with your team.
Why teams choose Northflank:
Unlike basic GPU providers, Northflank gives you everything in one platform: GPU compute, CI/CD pipelines, monitoring, and deployment tools. This means faster development cycles, lower operational overhead, and more time building your AI applications.
Get started today. Start your free trial or book a demo to see how Northflank can automate and simplify your AI development in a single platform and save costs.
These guides provide deeper technical details and specific GPU comparisons to help you make the best choice for your AI projects:
- Best GPU for machine learning - Detailed guide to choosing the right GPU for different AI workloads
- 12 best GPUs for AI and machine learning in 2026 - Compare H100, H200, A100, B200, and other top GPUs
- B100 vs H100: Best GPU for LLMs and training - In-depth comparison of NVIDIA's latest GPUs
- 12 Best GPU cloud providers for AI/ML in 2026 - Comprehensive comparison of GPU cloud platforms
- What is a cloud GPU? A guide for AI companies - Complete introduction to cloud GPU concepts
- Top GPU hosting platforms for AI - Platform comparison for inference, training, and scaling
- How to run AI workloads on cloud GPUs (without buying hardware) - Match specific models like Qwen and DeepSeek to the right hardware

