

Rent GPUs for AI: How to rent GPU power in 2026
AI and machine learning projects demand substantial computing power, but buying enterprise GPUs can cost tens of thousands upfront.
That's where GPU rental comes in.
You get instant access to high-performance GPUs, like on-demand NVIDIA GPUs for AI training, without the massive investment.
If you're training language models or running computer vision algorithms, renting GPU servers for AI lets you focus on building rather than buying hardware.
This guide shows you how to rent high-performance cloud GPUs with Northflank and get your first AI workload running in under 5 minutes.
Renting GPUs for AI workloads provides instant access to high-performance computing without the need for massive upfront costs.
You can rent GPU servers for AI projects starting at under $2/hour, with options ranging from NVIDIA A100s to powerful B200s.
The process is straightforward:
- Select your GPU model
- Configure your AI workloads and machine learning environment
- Deploy in under 5 minutes.
With platforms like Northflank, you can spin GPU workloads in under 5 minutes and get built-in usage metering, automatic scaling, and pay-per-second billing.
Need help with GPU capacity planning? If you have specific availability requirements or need assistance choosing the right GPU types for your workload, request GPU capacity here.
This approach lets you focus on developing your models rather than managing infrastructure, making it ideal for both startups testing proof-of-concepts and enterprises running production AI systems.
Buying GPU hardware upfront creates expensive challenges for your AI projects.
For instance, a single NVIDIA H100 costs over $25,000, and that's before you factor in servers, cooling, power, and maintenance.
So, for many projects, especially if you're just starting out, this represents huge financial risk.
GPU rental solves these problems by giving you on-demand access to the latest hardware without ownership burdens. You can scale your compute resources up or down based on what your project needs, experiment with different GPU models for specific tasks, and avoid depreciation costs as hardware advances quickly.
This flexibility becomes especially valuable when your AI workloads have variable requirements. Training might need massive parallel processing for days, while inference requires lighter, consistent resources.
Cloud GPU rental platforms also handle all the infrastructure complexity for you. So you no longer have to worry about driver installations, CUDA compatibility, cooling systems, or hardware failures. You can focus entirely on building your machine learning models and applications.
Now that you understand why GPU rental works for your projects, let's look at the specific advantages you'll get from GPU rental platforms.
-
Pay-per-use billing:
Means you only pay for the compute time you use, often down to the second. This granular billing can save you significant money compared to maintaining an always-on infrastructure that sits idle.
-
Instant scalability:
Becomes your competitive advantage. If you need to run multiple experiments simultaneously, you can spin up dozens of instances instantly. And if you’re working on a time-sensitive project, you can have access to the latest GPU models, which ensures you're never bottlenecked by outdated hardware.
-
Global deployment options:
Let you choose regions based on where your data lives or cost optimization needs. Your AI workloads can run closer to your users for better performance.
-
Easy integration:
Simplifies your development workflow. Platforms offer APIs and CLI tools for programmatic access, integration with CI/CD pipelines, and automated deployment processes. This means your GPU rentals fit smoothly into your existing development and production workflows.
-
Built-in monitoring and analytics:
Help you optimize both costs and performance. You can track GPU utilization, memory usage, and compute efficiency to ensure you're getting maximum value from your rental investment.
These benefits make GPU rental platforms valuable for startups testing proof-of-concepts, researchers running experiments, individual developers building AI projects, and enterprises running production AI systems.
Before we start the tutorial, here's what happens technically when you rent GPU power.
When you rent GPU power, you're accessing dedicated or shared GPU resources in cloud data centers.
The platform provisions virtual machines with direct GPU access, handles driver installation and compatibility, and provides network connectivity to your workloads.
You select your desired GPU model (like NVIDIA H100 or A100), specify your software environment through container images, and configure resource allocation.
Then, the platform schedules your workload on available hardware and provides monitoring tools to track usage and performance.
Billing typically starts when your workload begins running and stops when you terminate the instance.
How to rent GPU power for AI: Step-by-step tutorial to spin up a GPU workload on Northflank (under 5 minutes)
Understanding the benefits is one thing, but seeing how simple the process itself can be is another. Let me walk you through deploying your first AI workload on Northflank.
The platform handles all the complexity of GPU provisioning, networking, and resource management behind the scenes. This means you can go from account creation to running GPU workloads in under 5 minutes.
Here's how you can get your AI workload running on Northflank's GPU infrastructure. The process is designed to be intuitive, even if you're new to cloud deployments.
Visit Northflank.com and click "Get started" to sign up for your account. The signup process takes just a few minutes and supports GitHub, GitLab, or email authentication.
 Create your Northflank account
Create your Northflank account
Once you're logged in, click the "Create new" button (+ icon) in the top right of your dashboard. Select "Project" from the dropdown.
 Create new project on Northflank
Create new project on Northflank
Projects serve as workspaces that group together related services, making it easier to manage multiple AI workloads and their associated resources.
You'll need to fill out a few details:
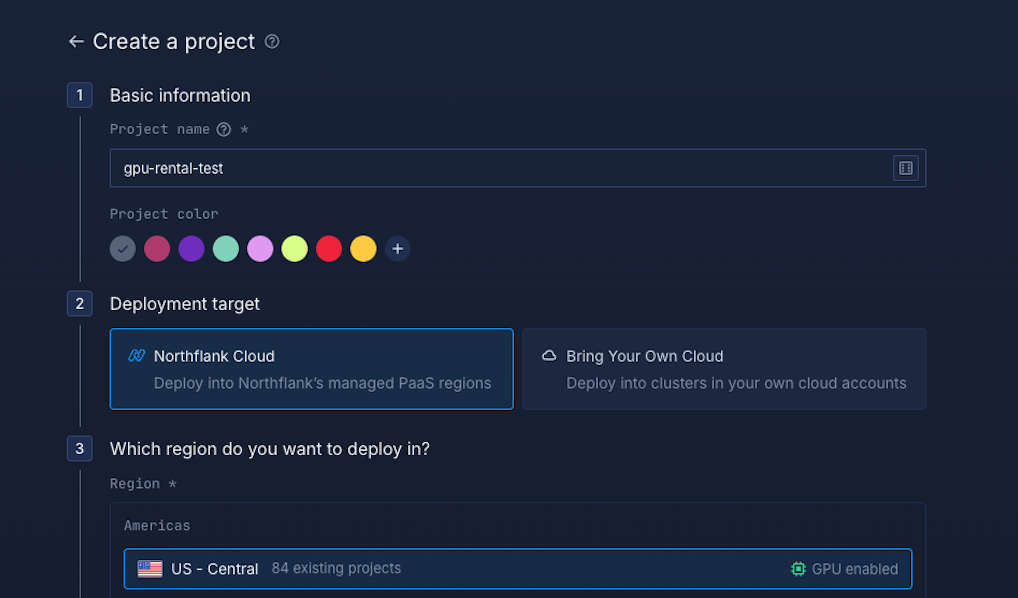
- Enter a project name (e.g., "gpu-rental-test") and choose a color for easy identification
- Select "Northflank Cloud" as your deployment target - this gives you access to Northflank's managed infrastructure with optimized GPU configurations.
- Optional (If you want to use your own cloud provider, select the “Bring Your Own Cloud” option (See more here - Deploy workloads on your own infrastructure - AWS, GCP, Azure, on-premises, or bare-metal))
- Choose a GPU-enabled region from the list (regions with GPU access are clearly marked with green "GPU enabled" indicators)
- Click "Create project" to proceed
On your project dashboard, you'll see several resource options. Click "Add new service" to deploy your GPU workload.
 Adding a new service
Adding a new service
Services in Northflank handle the deployment and management of your containerized applications.
Now you'll set up how your AI model will run:
- Select "Deployment (Deploy a Docker image)" since we'll be using a pre-built container image optimized for AI workloads
- Enter service name: "qwen4c" (or any name you prefer)
- Choose "External image" as your deployment source
- Enter the image path:
vllm/vllm-openai:latest(this is a popular image for running large language model inference, this example is for GPU inference specifically)
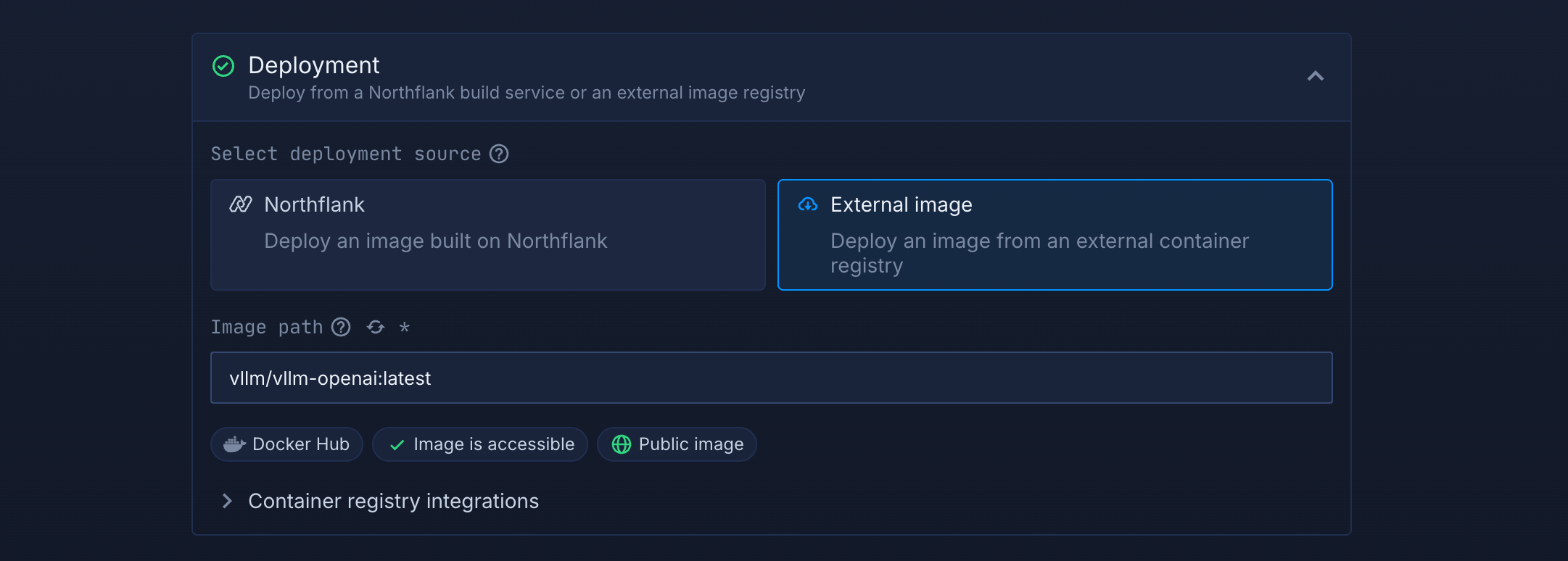 External image deployment configuration
External image deployment configuration
This is where you choose your computing power:
- In the Resources section, click the "GPU" tab
- You'll see a list of available GPU models with their specifications and hourly pricing
- Select "NVIDIA H100" with 80GB VRAM ($2.74/hr) for this example - this provides excellent performance for most AI workloads
- Set "GPUs per instance" to "1" to start with a single GPU configuration
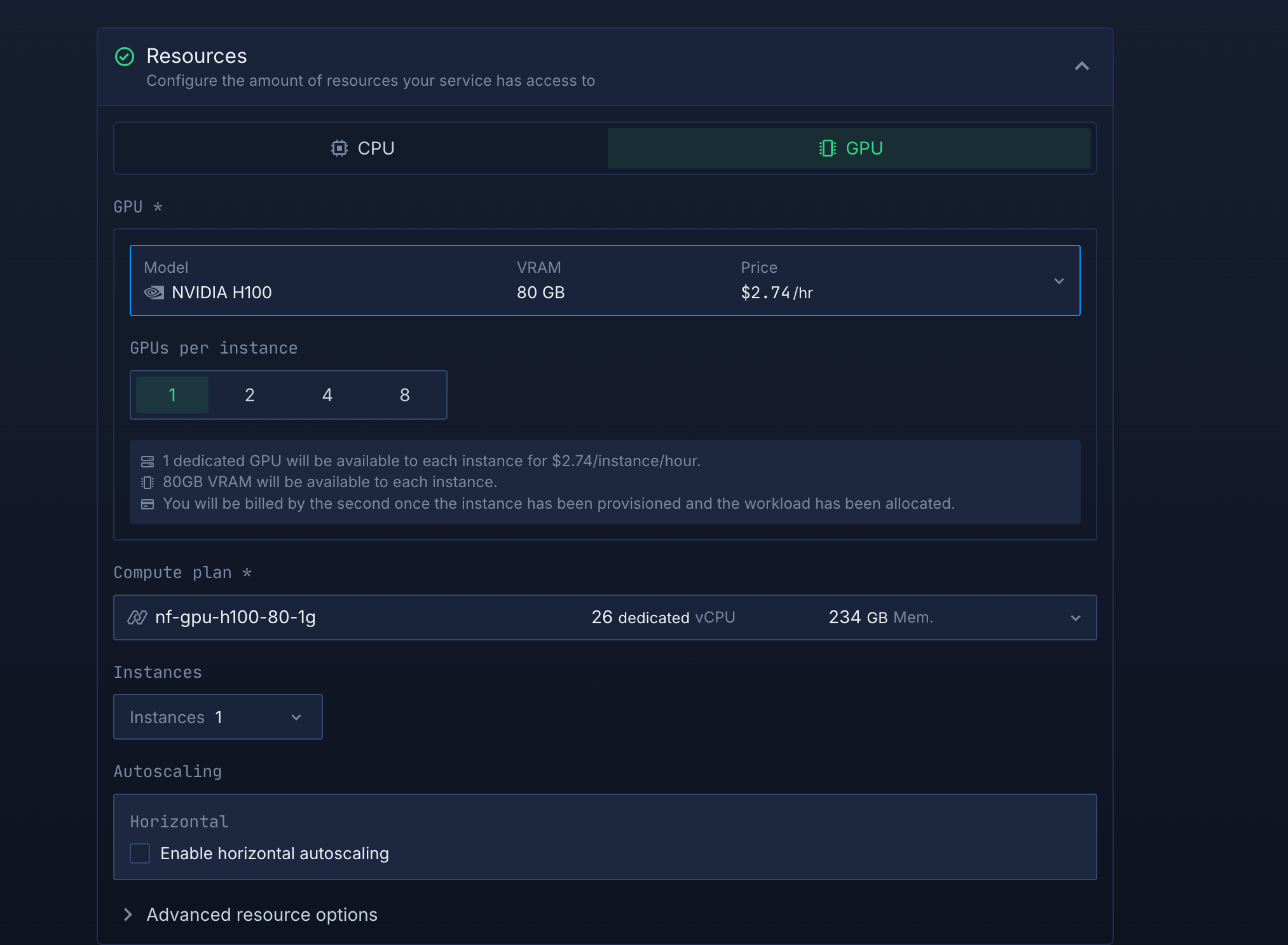 GPU configuration with H100 selected
GPU configuration with H100 selected
To make your AI model accessible:
- Scroll to the Networking section and click the "+" button to add a port
- Enter port 8000 and select HTTP as the protocol
- Check "Publicly expose this port to the internet" to make your service accessible
- Northflank will automatically generate a public endpoint URL that you can use to interact with your AI model
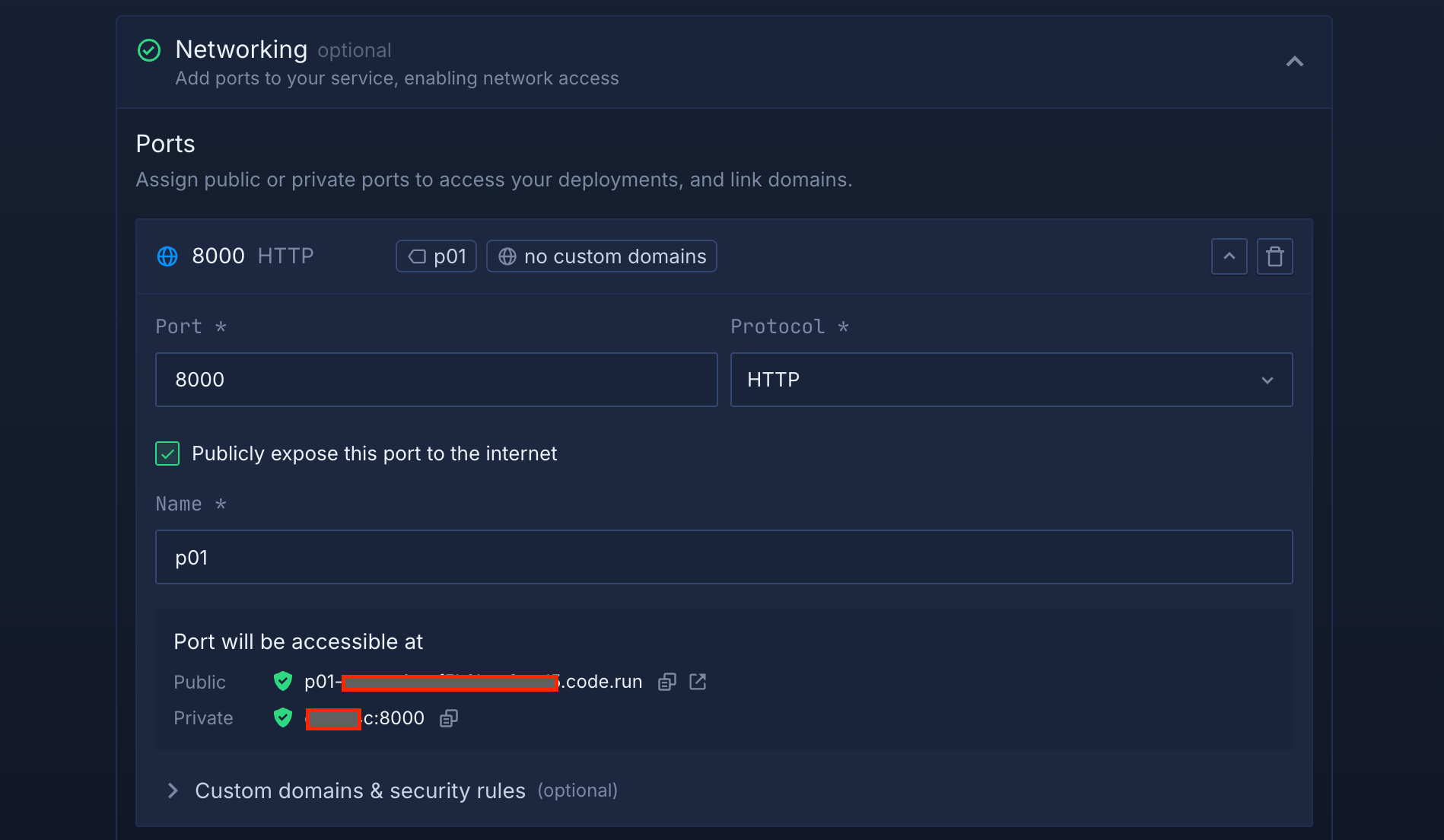 Port configuration with public exposure
Port configuration with public exposure
This tells your container how to start your AI model:
- In the Advanced settings section, find "Docker runtime mode" and click the dropdown
- Select "Custom entrypoint & command" to specify how your container should run
- Enter
bash -cas the custom entrypoint - Enter
'vllm serve Qwen/Qwen3-4B-Instruct-2507'as the custom command - This configures the container to serve a language model via vLLM
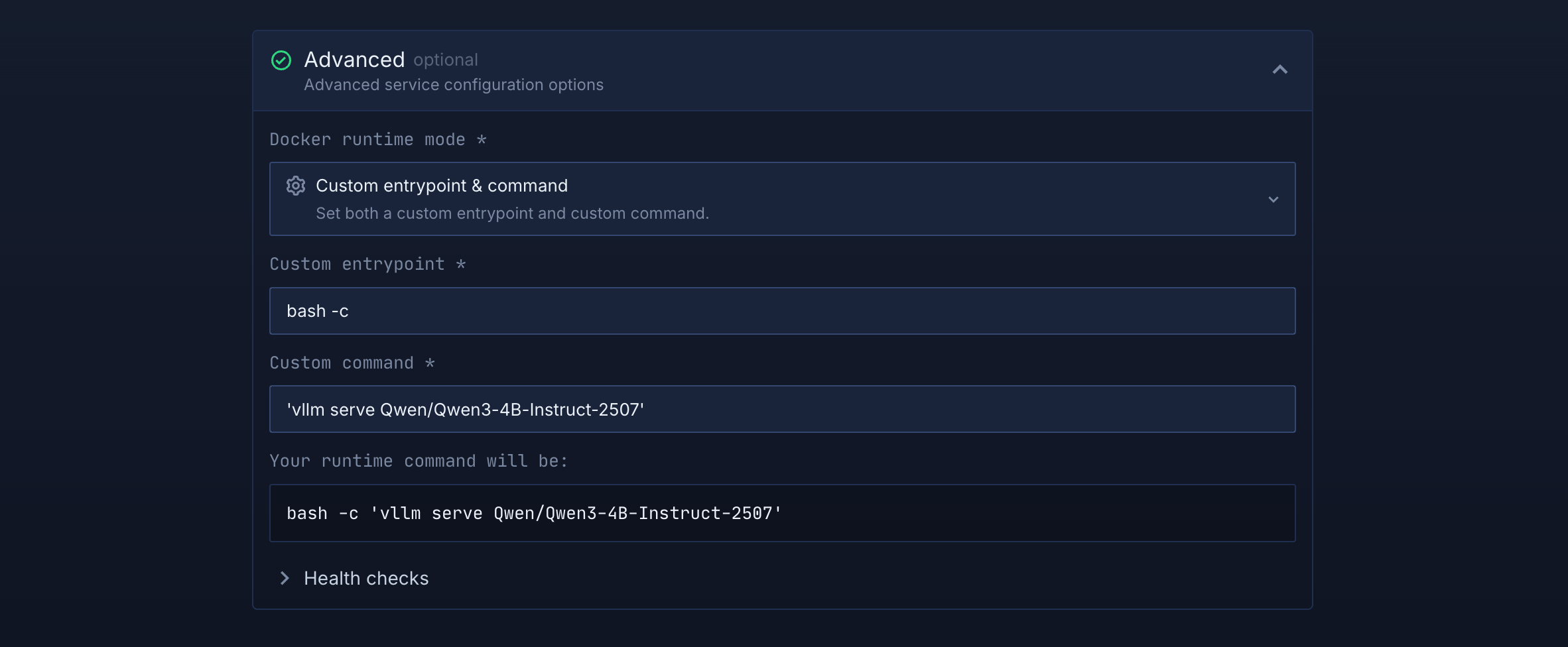 Custom entrypoint and command configuration
Custom entrypoint and command configuration
Click "Create service" to deploy your GPU workload. Northflank will provision the GPU resources, pull your container image, and start your service.
You can monitor the deployment progress in real-time through the dashboard.
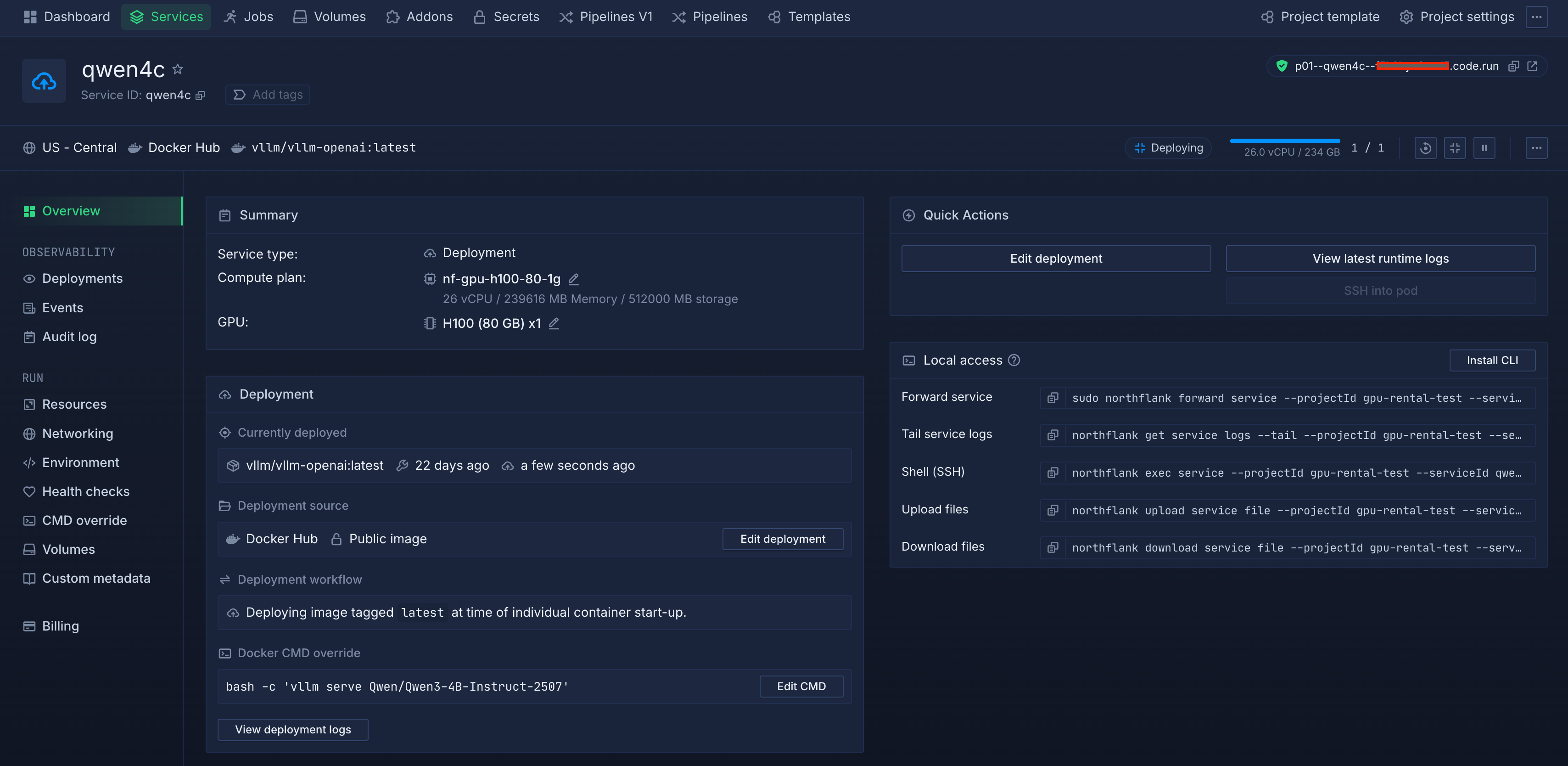
Once your service is deployed, Northflank provides comprehensive usage metering that tracks your GPU consumption by the second. This granular monitoring helps you understand exactly what you're paying for and optimize costs accordingly.
 Showing the metrics
Showing the metrics
The dashboard shows real-time metrics including GPU utilization, memory usage, and network activity. For production workloads, you can enable horizontal autoscaling to automatically adjust the number of instances based on demand.
This ensures optimal performance during traffic spikes while minimizing costs during low-usage periods. The autoscaling configuration allows you to set minimum and maximum instance counts, scaling triggers, and cooldown periods.
Your GPU workload is now live and accessible via the generated public endpoint. You can make API calls to your deployed model, monitor performance metrics, and scale resources as needed - all through Northflank's intuitive interface.
After seeing how straightforward the process is, you might be asking about the costs and if rental makes financial sense for your projects.
The cost-effectiveness of GPU rental depends on your usage patterns, but for most AI development scenarios, renting provides significant advantages over purchasing.
Look at this typical scenario:
Training a medium-sized language model might require 100 hours of compute time spread over several weeks. Renting an H100 for $2.74/hour would cost you $274 total, while purchasing the same GPU could cost $25,000 or more.
The break-even point for purchasing versus renting typically occurs when you need consistent, high-utilization access to the same GPU configuration for 6-12 months or longer.
However, this calculation should also factor in maintenance costs, power consumption, cooling requirements, and the opportunity cost of capital tied up in hardware.
For most development teams, especially those working on multiple projects or experimenting with different approaches, rental offers superior flexibility. You can easily switch between GPU models based on specific workload requirements, scale resources for different project phases, and avoid technology obsolescence as new GPU generations are released.
Startups and research teams particularly benefit from the low barrier to entry and ability to validate ideas before making major hardware investments. Even large enterprises often use GPU rental for overflow capacity, testing new configurations, or running workloads in different geographic regions.
Let's address some of the most common questions people have about GPU rental:
-
How does GPU renting work?
GPU rental platforms provide on-demand access to physical GPUs through virtualized environments. You select your desired GPU model, configure your software environment through container images, and pay for actual usage time. The platform handles hardware provisioning, driver management, and infrastructure maintenance. Platforms like Northflank make this process particularly straightforward with its intuitive interface.
-
Is renting a GPU worth it?
For most AI development scenarios, renting offers better cost efficiency and flexibility than purchasing. Unless you need consistent, high-utilization access to the same configuration for 6+ months, rental typically provides superior value while eliminating maintenance overhead.
-
Can you rent a GPU for gaming?
While technically possible, GPU rental platforms are optimized for compute workloads rather than gaming. The network latency and streaming requirements for gaming make dedicated gaming cloud services a better choice for that use case.
-
Why would someone rent a GPU?
The primary reasons include avoiding large upfront hardware costs, accessing latest GPU models without purchasing, scaling compute resources on-demand, and eliminating infrastructure management overhead. This is particularly valuable for AI development, machine learning research, and data processing workloads.
-
How much does it cost to rent a GPU for AI?
Costs vary by GPU model and provider. On Northflank, entry-level GPUs start around $1.42/hour for A100s, while high-end H100 GPUs cost $2.74/hour. Most platforms offer transparent pay-per-second billing.
-
What type of GPU should I rent for deep learning tasks?
For serious deep learning work, NVIDIA H200 or B200 GPUs provide the best performance with optimized Tensor cores. For smaller projects or experimentation, NVIDIA A100 or V100 GPUs offer good price-performance ratios. Northflank offers all these options with simple configuration and deployment.
Now that you've seen the costs, benefits, and step-by-step process, you can see why GPU rental has become the standard for AI development. It gives you flexibility, cost efficiency, and access to the latest hardware without huge upfront investments.
Northflank makes it simple to get started. You can deploy GPU workloads in under 5 minutes with transparent billing and automatic scaling. Don't let hardware constraints limit what you can build.
Get started with Northflank today or book a demo to speak with an engineer about your specific GPU requirements.
Here are additional guides to help you optimize your GPU rental experience and make informed decisions:
- Best GPU for AI - Compare GPU models and find the right one for your AI workloads
- Running AI on cloud GPUs - Learn best practices for deploying AI applications on cloud GPU infrastructure
- GPUs on Northflank (documentation) - Complete technical guide to using GPUs on Northflank
- Rent H100 GPU: pricing, performance and where to get one - Deep analysis of H100 GPU rental options and costs
- Best GPU for machine learning - Choose the optimal GPU for your machine learning projects
- What are spot GPUs? - Save money with spot GPU instances for non-critical workloads
- Configure and optimize workloads for GPUs - Technical guide to maximizing GPU performance


