

What is a GPU cluster? Use cases for AI developers
If you're building AI applications or training machine learning models, you've likely reached the point where a single GPU just isn't enough.
This guide will walk you through everything you need to know about GPU clusters, their benefits, and how to get started without the complexity of Kubernetes.
A GPU cluster is a network of interconnected computers equipped with multiple GPUs working together to handle massive computational workloads.
They're essential for training large AI models, running inference at scale, and processing data that would take an extremely long time on traditional CPU-only systems.
The good news: Northflank lets teams spin up GPU clusters without managing K8s themselves at affordable prices - perfect for model parallelism, training, and scaling inference.
Building a GPU cluster? If you need specific capacity, topology configurations, or multi-GPU setups, request GPU capacity here.
Simply put, a GPU cluster is a collection of computers (called nodes) that are connected together, with each computer equipped with one or more graphics processing units (GPUs).
It's like combining the power of multiple GPUs across different machines to tackle computational tasks that would be impossible or painfully slow on a single GPU.
While your CPU is optimized for handling tasks one after another (sequential processing), GPUs are designed to handle thousands of operations simultaneously (parallel processing)
When you connect multiple GPUs across several machines, you gain massive parallel processing power, which is ideal for AI workloads.
Your GPU cluster consists of two main types of nodes:
- Head node: The control center that manages the entire cluster, schedules jobs, and coordinates resources
- Worker nodes: The workhorses where your actual computations happen, each equipped with GPUs, CPUs, memory, and storage
Each worker node typically includes:
- GPU accelerators (like NVIDIA H100, H200, B200 A100, or L4)
- CPUs for orchestration and non-parallel tasks
- High-bandwidth memory for fast data access
- Network interface cards for high-speed communication between nodes
You'll encounter several different cluster configurations:
- Homogeneous clusters: All GPUs are identical (same model, memory, capabilities)
- Heterogeneous clusters: Mix of different GPU models and capabilities
- On-premises clusters: Hardware you own and manage in your data center
- Cloud-based clusters: Managed by cloud providers like AWS, GCP, or platforms like Northflank
Now that you understand what GPU clusters are, let's look at why they're important for AI teams like yours:
- Massive speed improvements: You can reduce model training time from weeks to days or even hours. Large language models that would take months to train on a single GPU can be trained in days with a properly configured cluster.
- Handle larger models: Modern AI models often exceed the memory capacity of a single GPU. Clusters let you distribute model parameters across multiple GPUs, enabling you to work with models that simply won't fit on one device.
- Better resource utilization: Instead of leaving expensive GPUs idle while waiting for sequential tasks, clusters keep your hardware busy with parallel workloads, maximizing your investment.
- Scalability on demand: You can start small and add more nodes as your computational needs grow, rather than being locked into a fixed configuration.
- Cost efficiency: While the upfront investment seems higher, clusters often provide better performance per dollar for large-scale AI workloads compared to scaling up single-GPU systems.
Managing GPU clusters traditionally means struggling with Kubernetes configurations, resource scheduling, and complex networking setups - tasks that can consume weeks of engineering time.
Northflank's GPU platform removes this complexity entirely.
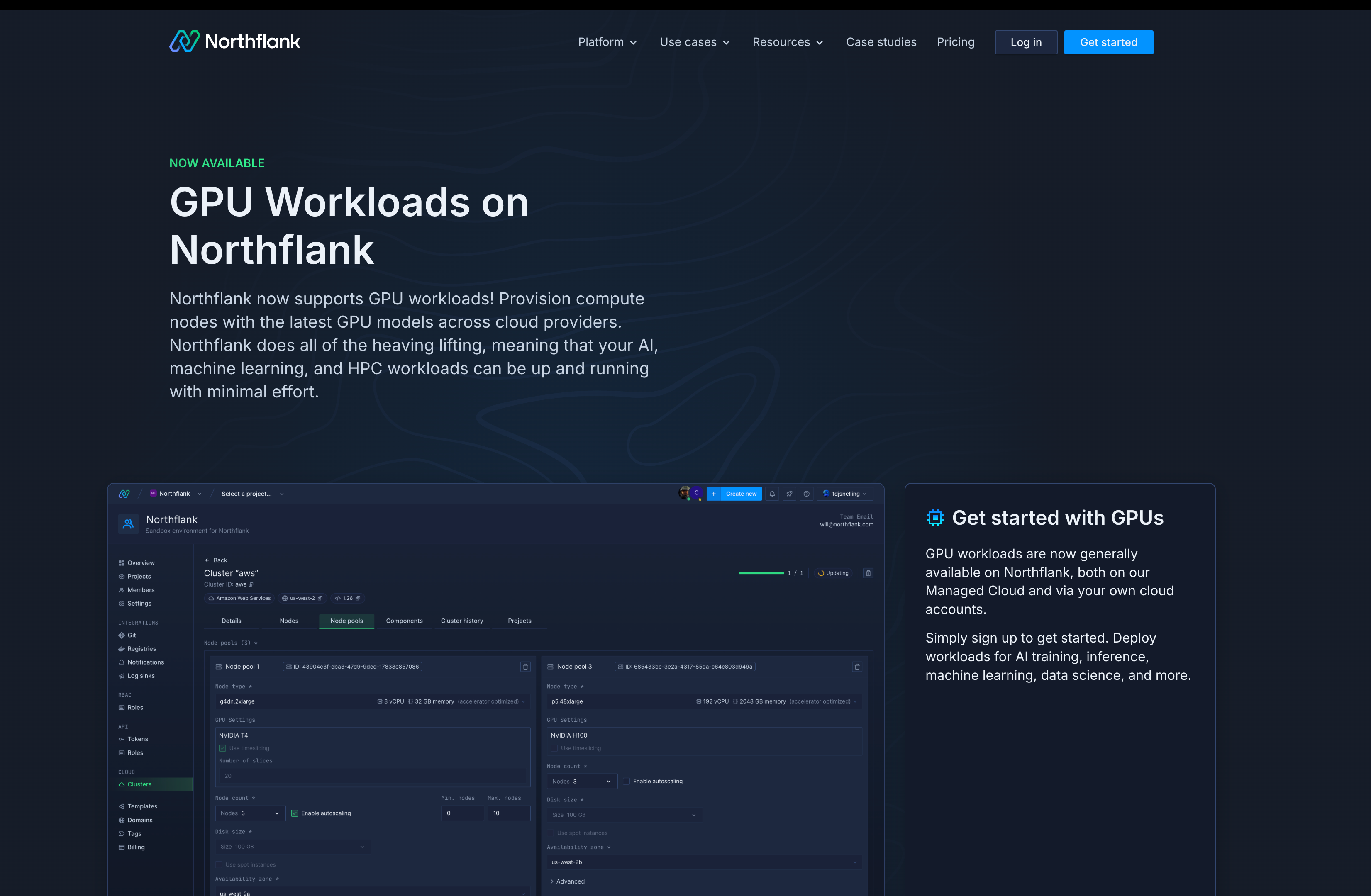
Rather than spending time configuring Kubernetes for GPU workloads, you get:
- One-click cluster deployment: Spin up GPU clusters in minutes, not days
- Automatic scaling: Your clusters dynamically adjust based on workload demands (See how that works)
- Built-in monitoring: Real-time performance metrics and health checks without additional setup (See the guides on Configure health checks and Observability on Northflank)
- Developer-friendly interface: Deploy your models and training jobs with simple configurations
If you're running workloads on Northflank's cloud GPUs or deploying on your own infrastructure, the platform handles the orchestration complexity.
You can configure and optimize your GPU workloads without needing to become a Kubernetes expert.
This means your team can focus on what counts - building and training better AI models - rather than managing infrastructure.
With simplified cluster management handled, let's see how you can use these powerful systems in your AI projects.
- AI model training: Training large language models, computer vision systems, or recommendation engines requires processing massive datasets. Clusters let you distribute this work across multiple GPUs, significantly reducing training time.
- Model fine-tuning: Even when adapting pre-trained models for your specific use case, clusters accelerate the process and let you experiment with larger, more capable base models.
- Real-time inference: Serving AI models to thousands of users simultaneously requires the parallel processing power that only clusters can provide. This is especially crucial for applications like chatbots, image recognition APIs, or recommendation systems.
- Model parallelism: When your models are too large to fit on a single GPU's memory, clusters let you split the model across multiple devices while maintaining fast inference speeds.
- Research and experimentation: Running multiple training experiments simultaneously, comparing different architectures, or performing hyperparameter searches becomes feasible with cluster resources.
Now is the time to move beyond single-GPU limitations. Let's quickly go over your path forward.
Start by assessing your current bottlenecks - are you waiting days for training to complete, running out of GPU memory, or unable to serve enough concurrent users? This will help you determine your cluster requirements.
Next, review your options: building your own infrastructure requires significant expertise and time, while platforms like Northflank enable you to get started immediately - either through managed cloud resources or by bringing your own infrastructure.
For the fastest path to production, try Northflank's GPU solutions - you can have a cluster running your workloads within hours, not weeks.
Skip the infrastructure complexity. Get started with Northflank's managed GPU clusters and focus on building breakthrough AI applications instead of managing Kubernetes.
Here are the most common questions we hear from AI teams considering GPU clusters.
- What is a GPU cluster? A GPU cluster is a network of interconnected computers equipped with GPUs that work together to handle large-scale computational tasks through parallel processing.
- How big is a typical GPU cluster? Clusters range from just 2-4 GPUs for small teams to thousands of GPUs for large-scale model training. Most AI startups begin with 8-32 GPU clusters.
- What's the difference between a GPU cluster and a supercomputer? Supercomputers are typically purpose-built, fixed installations, while GPU clusters are more flexible and can be assembled from standard hardware or cloud resources.
- How much does a GPU cluster cost? Costs vary widely based on GPU types and cluster size. Cloud-based solutions like Northflank offer pay-as-you-go pricing, while building your own requires significant upfront investment plus ongoing maintenance costs.
- When do you need a GPU cluster vs single GPU? Consider clusters when single GPU memory isn't sufficient for your models, training takes too long, or you need to serve many concurrent users.
- How does Northflank simplify GPU cluster management? Northflank handles all Kubernetes complexity, provides automatic scaling, and offers a developer-friendly interface so you can deploy GPU workloads in your own cloud or managed cloud without infrastructure expertise.
- Northflank GPU Documentation: Complete technical guide for deploying and managing GPU workloads on the platform.
- Deploy GPUs on Northflank Cloud: Step-by-step instructions for getting started with cloud-based GPU clusters.
- Bring Your Own Cloud GPU Setup: Guide for teams who want to use their own cloud infrastructure with Northflank's management layer.
- GPU Workload Configuration Guide: Best practices for optimizing your AI workloads for maximum GPU utilization and performance.

