

Run OpenAI's new GPT-OSS (open-source) model on Northflank
OpenAI just released GPT-OSS, its first fully open-source large language model family under an Apache 2.0 license. The release includes two models: gpt-oss-20b and gpt-oss-120b, designed for fast, low-latency inference with strong reasoning and instruction-following capabilities.
Northflank makes it simple to deploy and run these models in a secure, high-performance environment.
With our one-click deploy template, you can get started in minutes, without any infrastructure setup required.
TL;DR
- OpenAI released GPT-OSS, a powerful open-source LLM family under Apache 2.0.
- The 120B model delivers top-tier performance and runs smoothly on 2×H100.
- You can deploy it in minutes on Northflank using our one-click stack with vLLM + Open WebUI. No rate limits.
GPT-OSS is a new open-source LLM series released by OpenAI and integrated into Hugging Face Transformers as of v4.55.0. The models use Mixture-of-Experts (MoE) architecture comes with 4-bit quantization (mxfp4) to enable fast, efficient inference.
gpt-oss-20b: 21B total parameters, ~3.6B active per token, fits in 16GB of VRAMgpt-oss-120b: 117B total parameters, ~5.1B active, can run on a single H100 or multiple
These models support:
- Instruction-following
- Chain-of-thought reasoning
- Tool use and structured chat formats
- Inference via Transformers, vLLM, Llama.cpp, Ollama, and the OpenAI-compatible Responses API
The 20B model is optimized for speed and accessibility. It fits on a single 16GB GPU, making it ideal for on-device or low-cost server inference.
The 120B model delivers stronger reasoning and better performance on complex tasks and requires an H100 or multi-GPU setup (which you can get access to using Northflank).
Both use MoE routing with limited active parameters per forward pass, but 120B has a larger expert pool and deeper attention capacity.
We recommend using GPT-OSS-120B with vLLM for the best performance.
OpenAI’s GPT-OSS models are the first general-purpose LLMs they’ve released with open weights and a permissive Apache 2.0 license. Everything after GPT-2 (like GPT-3, GPT-4, and the o-series) has been closed-source and API-only. GPT-OSS-120B is also the most capable open-weight model they’ve released, using a modern Mixture-of-Experts architecture.
- Open weights
- Apache 2.0 licensing
- Strong performance for agentic and reasoning-heavy use cases
Unlike GPT-3.5 or GPT-4, which are closed-source and API-only, GPT-OSS is available to run locally or in your own infrastructure. That means full control over latency, cost, and privacy, especially when paired with a secure, GPU-ready platform like Northflank.
Self-hosting gpt-oss also means you won’t run into any rate limits. According to OpenAI, gpt-oss 120B’s performance is on par with o4-mini on most benchmarks, which would make it one of the top open-source models, if not the best.
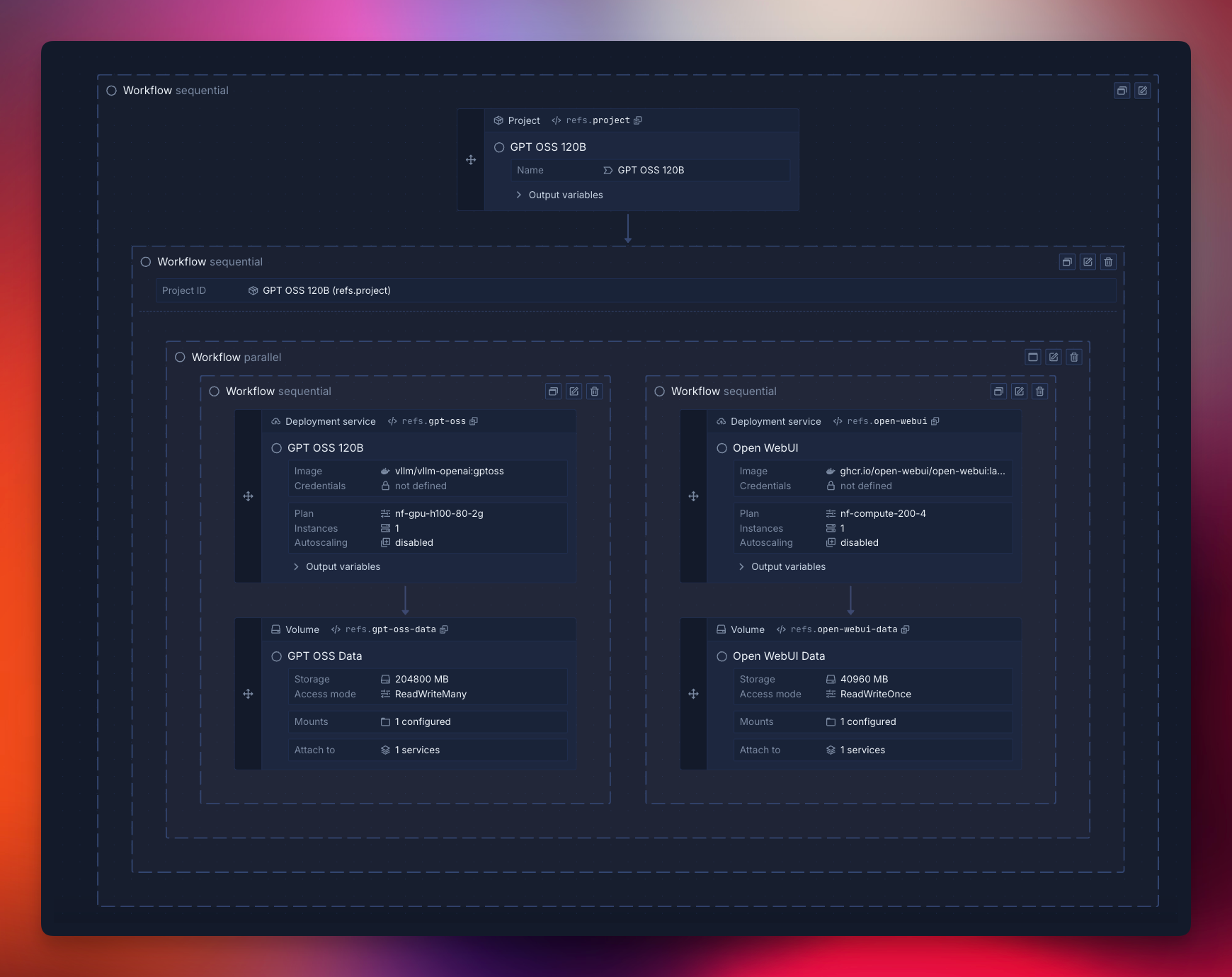
You can deploy GPT-OSS with Open WebUI using Northflank’s stack template in one click.
Sign up and configure your Northflank account.
You can read the documentation to familiarize yourself with the platform.
Northflank provides templates to deploy GPT-OSS with a few clicks.
Deploy the stack to save the template in your team, then run it to create a cluster in Northflank’s cloud with a vLLM service for high-performance inference and an Open WebUI for easy interaction.
For more details on this, see our guide on deploying GPT-OSS.
Below are the steps to deploy manually.
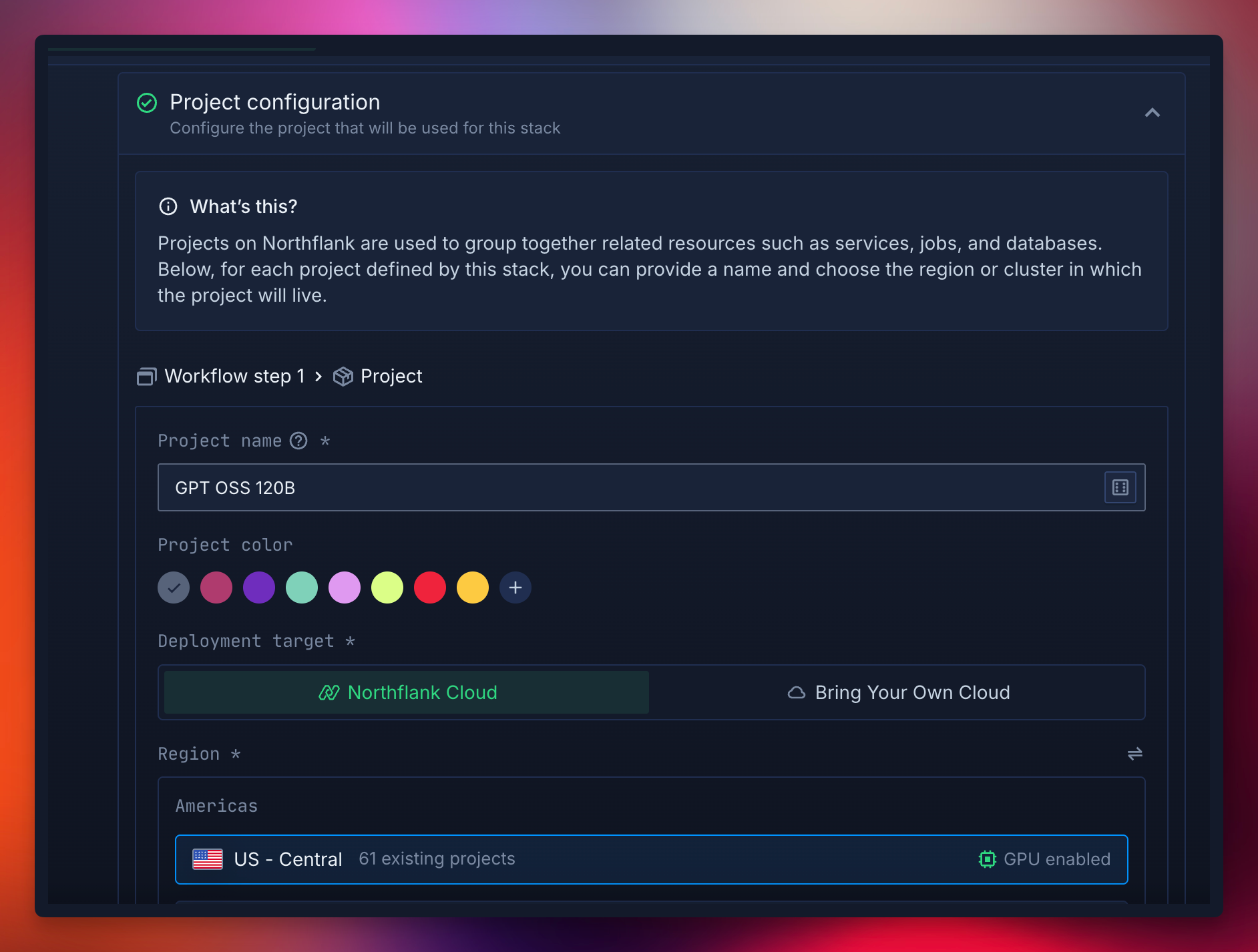
- In your Northflank account, create a new project.
- Name it, select a GPU-enabled region, and click create.
- Create a new service in your project and select deployment.
- Name the service GPT-OSS and choose external image as the source.
- Use the image path
vllm/vllm-openai:gptoss. - Add a runtime variable with the key OPENAI_API_KEY and click the key to generate a random value. Select length 128 or greater and copy this to the environment variable value.
- In networking, add port 8000 with http protocol and publicly expose it for this guide.
- Select a GPU deployment plan, and choose Nvidia’s H100 from the GPU dropdown with a count of 2 for high-performance inference.
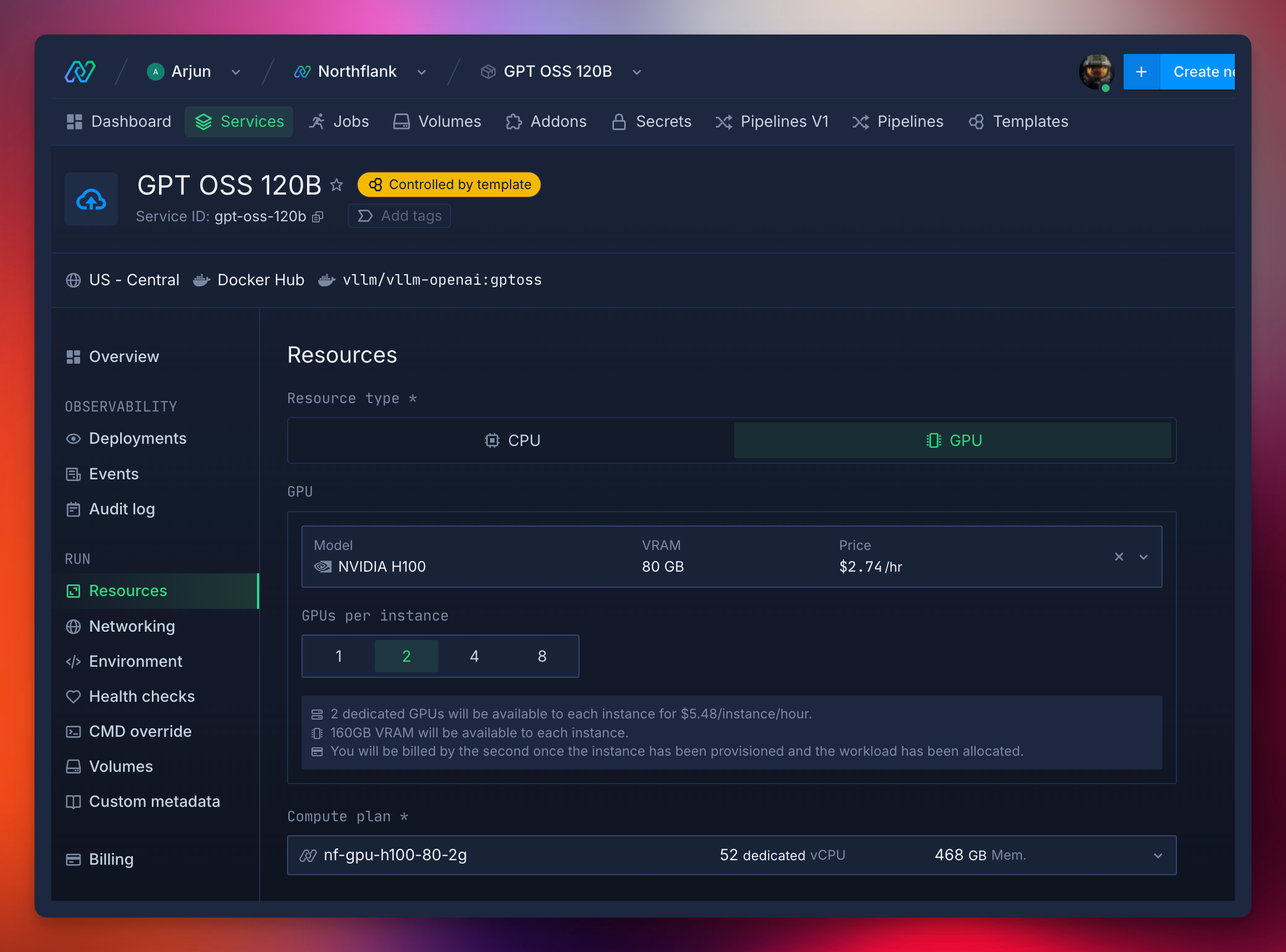
- In advanced options, set a custom command to sleep 1d to start vLLM without loading a default model.
- Click create service.
Containers on Northflank are ephemeral, so data is lost on redeployment. To avoid re-downloading GPT-OSS:
- From the service dashboard, go to volumes.
- Add a volume named vllm-models with 200GB storage.
- Set the mount path to /root/.cache/huggingface for Hugging Face model downloads.
- Click create and attach volume.
- Open the shell in a running instance from the service overview or observability dashboard.
- Download and serve the model with: vllm serve openai/gpt-oss-120b —tensor-parallel-size 2.
To automate this, set the entrypoint to bash -c and command to 'export HF_HUB_ENABLE_HF_TRANSFER=1 && pip install --upgrade transformers kernels torch hf-transfer && vllm serve openai/gpt-oss-120b --tensor-parallel-size 2’
- Run sample queries: Test GPT-OSS with coding prompts, adjusting parameters like output style.
- Keep iterating: One of the best parts of self-hosting is you can adapt as quickly as your business demands.
Use the public code.run URL from the service header (e.g., https://api--gpt-oss-vllm--abc123.code.run/v1/models) to check available models. Interact using OpenAI-compatible APIs in Python or other languages. Here’s a Python example:
-
Create a project directory:
gpt-oss-project/ ├── .env ├── requirements.txt └── src/ └── main.py -
Add to .env:
# The API key in your service's runtime variables OPENAI_API_KEY=your_api_key_here # The URL from your vLLM service's header OPENAI_API_BASE="https://your-vllm-instance-url/v1" # The model you downloaded and served with vLLM MODEL=openai/gpt-oss-120b -
Add requirements.txt
openai>=1.65.1 openapi>=2.0.0 python-dotenv>=1.0.0 -
Add to main.py:
import os from dotenv import load_dotenv from openai import OpenAI load_dotenv() client = OpenAI( api_key=os.environ.get("OPENAI_API_KEY"), base_url=os.environ.get("OPENAI_API_BASE"), ) completion = client.completions.create( model=os.environ.get("MODEL"), prompt="Write a Python function to sort a list" ) print("Completion result:", completion) chat_response = client.chat.completions.create( model=os.environ.get("MODEL"), messages=[ {"role": "user", "content": "Explain how to optimize a Python loop"} ] ) print("Chat response:", chat_response) -
Run locally with python src/main.py or deploy as a Northflank service.
Alright, but how much does it cost to self-host gpt-oss?
Running GPT-OSS-120B at constant load on 2×H100 GPUs with vLLM, here's what you can expect:
Cost per 1M tokens:
- Input tokens: $0.12
- Output tokens: $2.42
GPU cost on Northflank:
- 2×H100: $5.48/hour
Northflank offers some of the most affordable GPU pricing available for production workloads. Unlike other platforms that bundle hidden compute or RAM charges, our pricing is transparent and optimized for high-throughput inference. Perfect for serving large Mixture-of-Experts models like GPT-OSS-120B.
GPT-OSS marks a major shift in how large models can be used and deployed. OpenAI’s decision to release powerful MoE models under a permissive license gives developers real control for the first time and very importantly, no rate limits.
Northflank makes it easy to run GPT-OSS securely and efficiently.
Try it out yourself today here.


