

H100 vs H200 GPUs: Which Nvidia Hopper is right for your AI workloads?
When you are scaling AI workloads, the GPU you pick decides how fast you train, how much you spend, and how far you can push your models. The NVIDIA H100 has been the standard for high-performance training, powering everything from large-scale LLMs to generative AI. But with the launch of the H200, NVIDIA is pushing that frontier further.
The H200 builds directly on the Hopper architecture of the H100, keeping the same compute foundation but delivering major upgrades in memory and bandwidth. That makes it especially relevant for teams running larger and more memory-hungry models.
This guide breaks down the differences, with benchmarks, real-world use cases, and cost comparisons to help you decide which one fits your stack.
If you're short on time, here’s a quick look at how the H100 and H200 compare side by side.
Planning large-scale H100 or H200 deployments? For projects requiring dedicated capacity or specific availability guarantees, request GPU capacity to discuss your needs.
| Feature | H100 | H200 |
|---|---|---|
| Architecture | Hopper | Hopper (enhanced) |
| Cost on Northflank | $2.74/hr (80 GB) | $3.14hr (141 GB) |
| Tensor cores | 4th Gen + Transformer Eng. | 4th Gen + Transformer Eng. |
| Memory type | HBM3 | HBM3e |
| Max memory capacity | 80 GB | 141 GB |
| Memory bandwidth | 3.35 TB/s | 4.8 TB/s |
| NVLink bandwidth | 900 GB/s | 900 GB/s |
| Multi-instance GPU | 7 instances, ~10 GB each | 7 instances, ~16–18 GB each |
| Power draw (SXM) | Up to 700 W | Up to 1000 W |
| Performance uplift | Baseline | ~30–45% higher inference |
💭 What is Northflank?
Northflank is a full-stack AI cloud platform that helps teams build, train, and deploy models without infrastructure friction. GPU workloads, APIs, frontends, backends, and databases run together in one place so your stack stays fast, flexible, and production-ready.
Sign up to get started or book a demo to see how it fits your stack.
The H100 has become a popular choice for cutting-edge AI training. Built on the Hopper architecture, it introduced FP8 precision, a dedicated transformer engine, and fourth-generation tensor cores.
Key features include:
- 80 GB of HBM3 memory with 3.35 TB/s bandwidth
- 900 GB/s NVLink, supporting large multi-GPU clusters
- MIG support, allowing up to seven isolated GPU slices
- Optimized transformer performance through the Hopper transformer engine
This combination makes H100 extremely versatile: from fine-tuning LLMs to running stable inference at scale, it has been the go-to GPU for teams needing both speed and flexibility.
The H200 doesn’t change the compute architecture of the H100. Instead, it solves the next bottleneck: memory.
Highlights include:
- 141 GB of HBM3e memory — almost double the H100
- 4.8 TB/s bandwidth — 40% faster than H100
- Larger MIG partitions (~16–18 GB each), useful for multi-tenant workloads
- Higher TDP ceiling (up to 700 W SXM / 600 W PCIe), allowing maximum performance under heavy training
The result is a GPU that excels when models no longer fit comfortably on the H100. For large batch sizes, massive context windows, or memory-intensive inference, the H200 delivers a smoother, faster experience.
We’ve looked at the H100 and H200 on their own, but the real question is how they stack up against each other. While both share the same Hopper architecture, the H200 makes targeted upgrades that shift performance in key areas like memory, bandwidth, and scaling. These differences can have a major impact depending on whether you’re training, fine-tuning, or deploying large models. Let’s break them down.
Both GPUs retain the Hopper architecture with the same number of Tensor Cores. The H200 does not add new cores or change the design. It's faster and has a larger memory pipeline that keeps the existing cores fed, improving efficiency and reducing bottlenecks on memory-intensive workloads.
The H200 almost doubles memory capacity and boosts bandwidth to 4.8 TB/s, giving it the ability to handle larger datasets, support longer context windows, and cut training times on memory-bound workloads.
Both GPUs use the same 900 GB/s NVLink for multi-GPU training. The H200’s larger and faster memory allows for bigger MIG partitions (up to 16.5 GB each), which improves efficiency in multi-tenant environments and supports smoother scaling of inference across many smaller workloads.
Both come in PCIe and SXM form factors. The SXM versions are capped at the same 700 W TDP, so the H200 does not raise the power ceiling. The H200 delivers better performance per watt on memory-bound workloads thanks to its larger and faster memory, while PCIe remains the more cost-effective and cloud-friendly option.
Because the H200 is still built on Hopper, it runs the same CUDA stack, drivers, and frameworks as the H100, ensuring an upgrade path that delivers performance gains without requiring workflow changes.
On paper, the H200 doesn’t increase compute cores compared to the H100, but its memory and bandwidth upgrades translate into real-world performance gains.
According to NVIDIA’s official benchmarks, the H200 delivers:
- 1.4× speedup on Llama 2 13B inference
- 1.6× uplift on GPT-3 175B
- 1.9× faster performance on Llama 2 70B
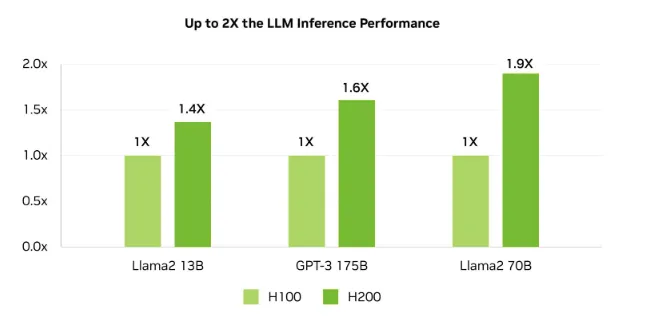
These improvements confirm that for large-model inference workloads, the H200 consistently outpaces the H100, while keeping the same Hopper architecture and software compatibility.
After comparing features and performance, the next question is what it actually costs to run these GPUs in the cloud. Pricing reflects not just the raw hardware, but also how quickly each GPU can finish workloads.
On Northflank, here’s what the current hourly rates look like (September 2025):
| GPU | Memory | Cost per hour |
|---|---|---|
| H100 | 80 GB | $2.74/hr |
| H200 | 141 GB | $3.14/hr |
The H100 remains the more affordable option for teams looking to balance performance and cost. The H200 comes at a premium, but with nearly double the memory and higher throughput, it can shorten training cycles and reduce the total cost of running large-scale workloads.
By now, you’ve seen how the H100 delivers proven performance across a wide range of AI workloads and how the H200 extends that with more memory, higher bandwidth, and faster throughput. Both are strong options, but they’re built for different priorities. The right choice comes down to the size of your models, your budget, and how much you value efficiency at scale. Here’s a breakdown to guide your decision.
| Use Case | Recommended GPU |
|---|---|
| Training vision models | H100 |
| Fine-tuning medium-sized LLMs | H100 |
| Inference with large batch sizes | H200 |
| Serving massive LLMs (70B+) | H200 |
| Multi-tenant GPU usage (MIG) | Both |
| Budget-conscious deployments | H100 |
| Maximum performance at scale | H200 |
| Energy-efficient long-term runs | H200 |
The H200 is not a reinvention of Hopper but an evolution that removes the memory and bandwidth limits of the H100. By expanding VRAM and accelerating data movement, it delivers higher throughput, more efficient scaling, and smoother performance on the largest AI models.
For teams pushing the frontier with cutting-edge workloads, the H200 will feel like a necessary upgrade. For those balancing cost and performance in production, the H100 remains a powerful and proven option.
With Northflank, you can access both. Start experiments on H100s today and seamlessly scale to H200s as your models grow. You can launch GPU instances in minutes or book a demo to see how the platform fits your workflow.


