

Modal vs Baseten: Which AI deployment platform fits your stack?
Quick summary
Modal is a serverless platform for running Python functions with GPU access. It's built for batch jobs, workflows, and async tasks.
Baseten focuses on optimized model inference APIs for production workloads.
Both platforms handle their specific use cases well, but have limitations: neither supports full-stack applications, both lack built-in CI/CD, and both use platform-specific abstractions.
Northflank takes a different approach. It's a container-based platform that supports everything from model serving to full applications. Northflank provides built-in Git-based CI/CD, Bring Your Own Cloud (BYOC) without enterprise pricing, GPU orchestration, and production-grade infrastructure.
If you need flexibility beyond isolated functions or model serving, Northflank provides that without sacrificing deployment speed. Try it out directly or book a demo with an Engineer.
You've built something that works. Your model performs well in notebooks, your inference pipeline is reliable, and now you need to deploy it without spending weeks configuring infrastructure.
Modal and Baseten both promise to get you there fast, but they take different approaches. Modal gives you serverless Python functions. Baseten gives you optimized model inference.
Both work well for specific use cases, but as your product grows, you might need something more flexible.
This article breaks down the modal vs baseten comparison, examines where each platform performs best, and introduces Northflank as a production-ready alternative that combines speed with full-stack flexibility.
If you're choosing between these platforms, you'll leave with a clear understanding of which one fits your workflow.
Below is an overview of how the three platforms compare across key features. We'll go into more detail later in the article.
| Feature | Modal | Baseten | Northflank |
|---|---|---|---|
| Primary focus | Python functions & workflows | Model inference APIs | Full-stack apps & AI workloads |
| Deployment model | Serverless functions | Model-as-a-service | Containerized services |
| GPU support | H100, A100, L40S, A10, L4, T4 | Custom inference-optimized GPUs | H100, A100 80GB/40GB, L40S, A10, up to B200. See more supported GPUs here |
| Cold start time | Sub-second | Optimized for inference | Fast startup with warm containers |
| CI/CD integration | External tools needed | Limited native support | Native Git-based CI/CD with preview environments |
| Full-stack support | Functions only | Model serving + basic UI builder | Complete: frontend, backend, databases, workers |
| Networking | Basic (no VPC, limited control) | Managed, inference-focused | Private networking, VPC, custom domains, service mesh |
| BYOC (Bring Your Own Cloud) | No | Enterprise only (requires sales) | Yes, from day one (self-service) |
| Container control | Modal-specific runtime | Limited customization | Full Docker control, BYO images |
| Best for | Async tasks, batch jobs, ML workflows | Model inference at scale | Production AI products, full-stack apps |
| Pricing model | Usage-based (per second) | Usage-based (inference-focused) | Usage-based (transparent per-resource) |
| Vendor lock-in | High (Modal-specific decorators) | Moderate (model-centric abstractions) | Low (standard containers, Bring Your Own Cloud (BYOC) option) |
Before breaking down the comparison, let's look at what each platform does, who uses them, and where their strengths and limitations become apparent in production environments.
Modal is a serverless platform for running Python functions in the cloud. You write a function, add a decorator, and it runs with GPU access. It handles batch processing, scheduled jobs, LLM fine-tuning, and async inference tasks.

The platform is Python-based and scales automatically with sub-second cold starts. Key features include:
- GPU support: H100, A100, L40S, A10, L4, and T4
- Built-in scheduling for cron jobs, background tasks, and retries
- Functions served as HTTPS endpoints
- Network volumes, key-value stores, and queues
- Real-time logs and monitoring
However, the function-centric design comes with trade-offs. You can't deploy full applications with frontends and backends. CI/CD integration requires external tools, and networking capabilities are more limited compared to container-based platforms.
If your project grows beyond isolated Python functions, you may need to supplement with other tools or consider a different approach.
Baseten focuses specifically on model inference. The platform is built for teams that need to serve ML models as production APIs with enterprise-grade performance.

Baseten's inference stack includes custom kernels, advanced caching, and performance optimizations built into the platform. Key features include:
- Deploy open-source models, custom models, or fine-tuned variants
- Autoscaling, monitoring, and reliability built-in
- Dedicated deployments for high-scale workloads
- Support for various model types: LLMs, image generation, transcription, and embeddings
However, the platform's model-first design has limitations. You can't deploy full-stack applications beyond model serving. Bring Your Own Cloud (BYOC) options exist but require enterprise pricing and sales discussions.
If you're building a product that includes background workers, complex APIs, or multiple interconnected services, the platform's scope may not be sufficient
When comparing Modal vs Baseten directly, the fundamental difference is workflow focus.
Modal handles general-purpose Python compute (batch jobs, workflows, training), while Baseten specializes in serving models as inference APIs
Choose Modal if:
- You're running Python workflows, batch processing, or scheduled ML tasks
- You want to prototype quickly without infrastructure setup
- Your workload centers on isolated functions that can scale independently
- You're comfortable with function-as-a-service abstractions
Choose Baseten if:
- You need optimized, production-grade model inference
- You're serving models as APIs at enterprise scale
- You want built-in performance optimizations for LLMs and custom models
- Your primary focus is serving, not training or general compute
Both platforms handle GPU access well, but neither supports deploying full applications. Both lack native CI/CD integration. And both require you to work within their specific abstractions, which can create challenges as your requirements change.
When evaluating modal vs baseten, some teams find they need capabilities beyond what either platform offers. They want deployment simplicity alongside the flexibility to build full products without being constrained to a specific deployment pattern.
Northflank takes a different approach.
Rather than specializing in functions or inference, it provides a developer platform, with support for both AI and non-AI workloads (like your frontend, backend APIs, databases, and background workers) that handles model serving, full-stack applications, and everything in between.
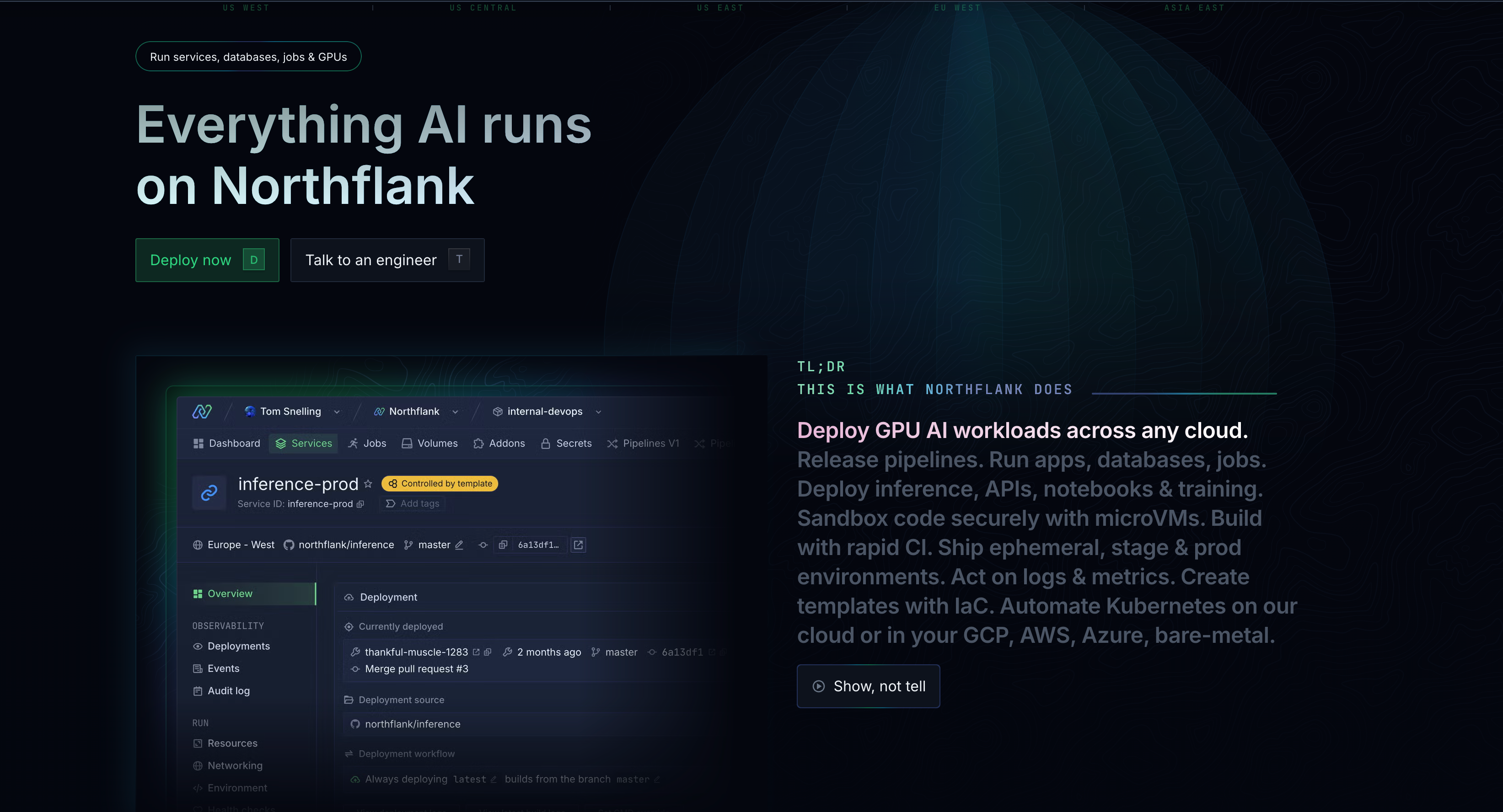
Let’s look at the key differences:
Northflank is built on standard Docker containers. This means you can deploy Python ML workloads, Node.js APIs, React frontends, background workers, and databases from the same platform. You're not limited to framework-specific patterns. If it runs in a container, it runs on Northflank.
When building a product, your inference API is often just one component. You also need a frontend, authentication, data processing pipelines, and scheduled jobs. Northflank supports all of these without requiring multiple platforms.
While Modal and Baseten require external tools for CI/CD, Northflank includes Git integration as a core feature. Connect your GitHub (see how), GitLab (see how), or Bitbucket repository (see how), and each commit triggers automated builds, tests, and deployments.
There are also preview environments (try it out) for pull requests that allow your team to test changes before merging them to production.
Northflank includes private networking, VPC support, RBAC, audit logs, SAML SSO, and more as standard features.
The platform also provides secure runtime isolation for running untrusted AI-generated code, which matters for teams building fine-tuning platforms or AI agents.
For GPU support, the platform offers NVIDIA H100, A100 (40GB and 80GB), L40S, B200, and more.
Also, autoscaling, lifecycle management, and cost optimization are included.
Northflank supports Bring Your Own Cloud (BYOC) without requiring enterprise pricing or sales calls.
You can deploy workloads in your own AWS (try it out), GCP (try it out), Azure (try it out), Civo (try it out), or Oracle (try it out) accounts while keeping the managed platform experience.
This provides cost transparency, data residency control, and the flexibility to optimize your cloud spending.
Modal doesn't offer BYOC. Baseten supports it through enterprise contracts. Northflank makes it self-service.
Northflank uses usage-based pricing: you pay only for the resources your services consume. No hidden fees. You can estimate costs before deploying and track usage in real-time.
The modal vs baseten decision depends on what you're building today and where you're headed.
If you're running isolated Python tasks or need optimized model inference with minimal setup, either platform works well.
But if you're building a product that will grow beyond those use cases, the constraints will become apparent.
Northflank doesn't force you to choose between speed and control. You get both, along with the production-ready infrastructure your team needs to scale confidently.
If you're serving models, running training jobs, or deploying full applications, the platform adapts to your requirements instead of constraining them.
Deploy your AI workload on a platform built for production. Start with Northflank's free tier and experience full-stack flexibility with GPU orchestration, or book a demo to see how Northflank supports your specific use case.


