

7 cheapest cloud GPU providers in 2026
This article will help you find the cheapest cloud GPU provider
I've been watching developers cope with GPU costs for years.
Recently, I came across a discussion where developers were searching for cloud GPU providers for fine-tuning and inference workloads. They were asking about reliable options that won't break the budget.
When you're building AI applications, training models, or running inference APIs, you might have encountered the same challenge. GPU costs can quickly become a major expense when scaling workloads.
One thing I've noticed is that with the right strategies and platforms like Northflank, you can access enterprise-grade compute power without the enterprise price tag. Some of these approaches can save you up to 90% compared to standard on-demand pricing.
I'll walk you through 7 best platforms and strategies that can cut down your GPU costs.
Looking for specific GPU availability? Price isn't everything; availability also matters. If you need guaranteed access to specific GPU types, request GPU capacity here.
When selecting a cloud GPU service, price alone doesn't tell the full story.
I've seen teams choose the lowest hourly rate only to encounter unexpected costs and reliability issues that ended up being more expensive in the long run.

So, these are the things you should keep in mind:
1. Look beyond the advertised price
Many platforms advertise low GPU rates but charge separately for CPU, RAM, and storage. A $1.50/hr GPU that requires an additional $0.50/hr for adequate CPU and storage ends up costing more than a $1.80/hr all-inclusive option.
2. Factor in reliability costs
Marketplace providers might list H100s at $0.90/hr, but if your training job gets interrupted three times and you lose 6 hours of progress, you're paying more than a stable $2.50/hr instance that completes the job without interruption.
3. Think about your scaling patterns
If you need GPUs sporadically, pay-per-minute billing can save 40% compared to hourly billing for short tasks. For consistent workloads, reserved instances or committed use discounts become more valuable.
4. Check for hidden fees
Data transfer costs, storage fees, and setup charges can quickly add up. Some providers charge for data ingress/egress, while others include it in their pricing.
5. Check availability and quotas
The cheapest GPU isn't valuable if it's never available when you need it. Major cloud providers often require quota requests that can take days to approve, while some platforms impose spending limits for new users.
The optimal approach is to find a platform that combines competitive pricing with reliability, transparent billing, and the flexibility to scale with your needs.
Now that you know what to look for, let's compare how the major platforms perform on pricing and value.
I've analyzed the most popular GPU configurations across different providers to show you the pricing as of September 2025.
Keep in mind that while some platforms show lower hourly rates, the total value depends on the factors we just discussed - reliability, hidden fees, and availability.
| Platform | A100 (40GB & 80GB) | H100 (80GB) | Available GPUs | Spot/Discount Options | Recommendation |
|---|---|---|---|---|---|
| 🏆 Northflank | $1.42/hr, $1.76/hr | H100 80GB: $2.74/hr | A100 40/80GB, H100, H200, B200, L4, L40S, MI300X | Auto spot orchestration + BYOC (Bring your own cloud) + Production reliability | ⭐ BEST VALUE |
| VastAI | $0.50–$0.70/hr, $0.60–$0.80 (dynamic pricing) | From $1.77/hr | A100 40/80GB, H100, RTX 4090, wide variety | Peer-to-peer marketplace pricing | Budget experiments |
| RunPod | A100 PCIe 80GB: $1.19/hr (Community), $2.17/hr (Serverless) | $2.79/hr (Community), $3.35/hr (Serverless) | H100, A100 80GB, RTX 4090, L40S, A6000 | Community Cloud + Serverless options | AI-focused workflows |
| TensorDock | A100 80GB: $1.63/hr | $2.25/hr | A100, H100, RTX 6000, 3090 | Global marketplace | Custom configurations |
| AWS | A100 (40GB): ($32.77/hr for 8x GPUs), A100 (80GB): ($40.96/hr for 8x GPUs) | H100 80GB: ($55.04/hr for 8x GPUs) | H100, A100 40GB, L40S, T4 | Up to 90% with Spot Instances | Enterprise at scale |
| Lambda Labs | $1.29/hr, $1.79/hr | H100 80GB: $2.99/hr | H100, H200, A100 40/80GB, B200 | On-demand, reserved instances | Training when available |
| Paperspace | A100 (40GB): $3.09/hr**,** A100 (80GB): $3.18/hr | H100 80GB: $5.95/hr | A100, RTX 6000, 3090 | Limited promotional rates | Development & notebooks |
Prices are representative and may vary by region and availability
Note: The cheapest option isn't always the best value. You need to factor in reliability, ease of use, and hidden costs like data transfer fees.
Before we go into detail for each platform, let me explain the two strategies that can dramatically cut your costs:
Spot instances are unused GPU capacity that cloud providers sell at massive discounts - often 60-90% off regular prices. They can be interrupted with short notice when demand increases. Read more about it in this guide.
BYOC (Bring Your Own Cloud) lets you deploy on your existing AWS, GCP, or Azure accounts, leveraging any credits, enterprise discounts, or committed use agreements you already have. Read more about it in this guide.
The best part is when you combine both strategies with automated orchestration that automatically handles interruptions and finds the cheapest capacity across multiple clouds.
Let me walk you through each platform, starting with the ones that offer the best combination of cost savings and reliability:
I'll be upfront: I'm biased toward platforms that solve major problems, and Northflank consistently delivers the best value for teams building production AI applications.
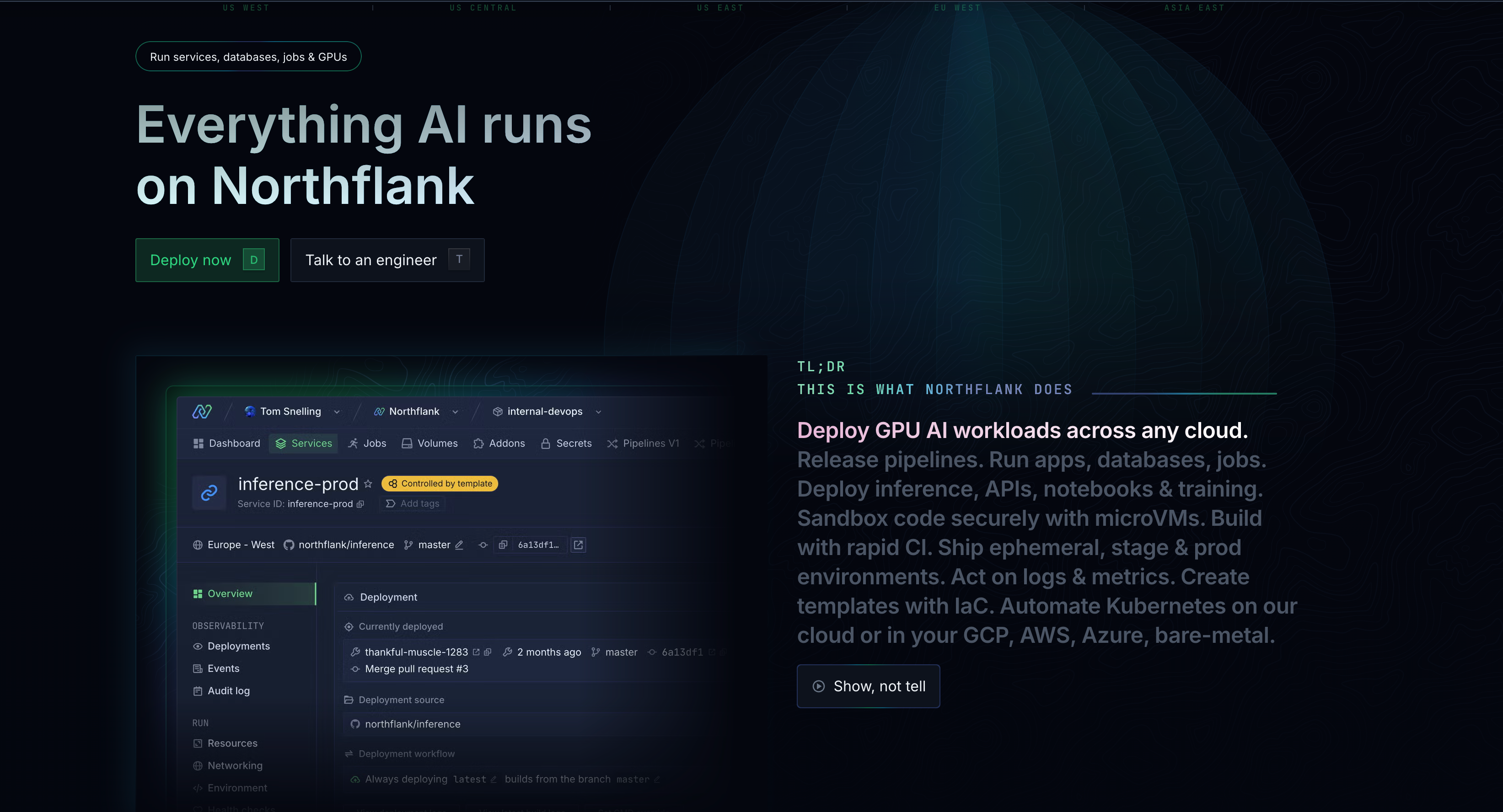
What makes Northflank special:
- Automatic spot optimization: The platform continuously scans across AWS, GCP, and Azure to find the cheapest spot capacity
- BYOC (Bring your own cloud) flexibility: Deploy into your own cloud accounts to use existing credits and enterprise discounts (See how)
- All-inclusive pricing: GPU, CPU, RAM, and storage bundled together with no surprise charges
- Production-ready: Automatic failover when spot instances are reclaimed, so your applications never go down
🤑 Northflank pricing
- Free tier: Generous limits for testing and small projects
- CPU instances: Starting at $2.70/month ($0.0038/hr) for small workloads, scaling to production-grade dedicated instances
- GPU support: NVIDIA A100 40GB at $1.42/hr, A100 80GB at $1.76/hr, H100 at $2.74/hr, up to B200 at $5.87/hr
- Enterprise BYOC: Flat fees for clusters, vCPU, and memory on your infrastructure, no markup on your cloud costs
- Pricing calculator available to estimate costs before you start
- Fully self-serve platform, get started immediately without sales calls
- No hidden fees, egress charges, or surprise billing complexity
The Weights team scaled to millions of users using Northflank's spot GPU optimization, cutting their model loading time from 7 minutes to 55 seconds while slashing costs by 90%.
Best for: Production AI applications that need reliability with maximum cost savings
Learn more: What are spot GPUs? Complete guide to cost-effective AI infrastructure
VastAI operates like Airbnb for GPUs - individual owners rent out their hardware through a competitive marketplace.

The pricing advantage:
- H100s available from ~$1.65/hour for interruptible instances
- RTX 4090s available from ~$0.31/hour for interruptible instances
- Interruptible instances with bidding can lead to significant cost savings compared to on-demand pricing
The trade-offs:
- Variable reliability depends on the host
- Limited enterprise features or support without upgrading to a premium tier
- Network latency issues if you choose geographically distributed GPUs
Best for: Experimentation, research projects, and cost-sensitive workloads that can tolerate interruptions
RunPod focuses specifically on AI workloads with pre-configured templates for popular frameworks.

Community Cloud vs Secure Cloud:
- Community Cloud: Better pricing, shared infrastructure. (Example pricing: RTX 4090 from ~$0.34/hr, H100 PCIe from ~$1.99/hr)
- Secure Cloud: Enterprise features with a premium cost. The premium varies by GPU, but can be higher for more powerful cards. (Example pricing: RTX 4090 from ~$0.27/hr more than Community Cloud, A100 80GB from ~$0.45/hr more, H100 PCIe from ~$0.40/hr more) The highest Secure Cloud instance price is for the B200 SXM, at around $5.98/hr.
- Serverless options: Pay only when your code is running. (Example pricing: A100 80GB from $2.17/hr for Flex worker, H100 80GB from $4.47/hr for Flex worker, prices vary by GPU)
Why developers choose RunPod:
- 50+ pre-configured templates for Stable Diffusion, ComfyUI, and popular AI frameworks
- Fast cold-start times (often under a second)
- No data transfer fees
- Active Discord community for support
Best for: AI developers who want managed infrastructure with community support
Learn more: RunPod vs Vast.ai vs Northflank: The complete GPU cloud comparison
TensorDock is a RunPod alternative that offers marketplace pricing with better security and flexibility.

What it offers:
- H100 SXM5 from $2.25/hr with no quotas or spending limits, reflecting a competitive on-demand rate. Spot pricing is also available from $1.91/hr.
- A range of other GPUs, such as RTX 4090s from $0.35/hr and A100s from $0.75/hr.
- 99.99% uptime standard across a global network of locations.
- Full VM control with Windows support, as it uses KVM virtualization.
- KVM isolation for better security than container-based solutions.
Best for: Teams wanting enterprise reliability at marketplace prices
Learn more: 6 best TensorDock alternatives for GPU cloud compute and AI/ML deployment
AWS, Google Cloud, and Azure all offer substantial discounts through their spot/preemptible instance programs.
AWS Spot Instances:
- Pricing: [H100 instances often between ~$3.00–$8.00/hr, A100 instances ~$1.50–$4.00/hr per GPU for 8-GPU instances, depending on supply and demand])
- Up to 90% off on-demand pricing
- Requires quota approval for most GPU types
- Complex management without orchestration tools (Spot instances can be interrupted with a two-minute warning when AWS reclaims capacity)
Azure Spot VMs:
- Pricing: [H100 instance (8x GPUs) spot price ~$28.99/hr, A100 instance (8x GPUs) spot price ~$17.50/hr, T4 instances as low as $0.09/hr per GPU].
- Similar 90% discounts with 30-second interruption notice (the specific percentage depends on the region and instance type. Azure also provides a 30-second warning before eviction.)
- Clearer pricing transparency than AWS (While Azure offers spot price history and an eviction rate advisor, its overall pricing structure is not inherently "better" than AWS)
- Integration with existing Microsoft enterprise agreements
Google Cloud Spot VMs:
- Pricing: [H100 from ~$2.25/hr per GPU, A100 80GB from ~$1.57/hr per GPU, A100 40GB from ~$1.15/hr per GPU].
- Often up to 60–91% savings compared to on-demand instances
- Flexible CPU/GPU configurations (Google Cloud allows for attaching a range of GPUs (including NVIDIA T4s and V100s) to its virtual machines)
- Better for custom setups due to component-based pricing (Google Cloud's pricing model for GPUs is more granular than AWS and Azure, allowing you to pay separately for the GPU and the underlying virtual machine)
The enterprise advantage: These platforms become cost-competitive at scale, especially with enterprise volume discounts and committed use agreements.
Best for: Large enterprises with dedicated DevOps teams and predictable but not time-critical workloads.
Learn more: What are AWS Spot Instances? Guide to lower cloud costs and avoid downtime
Lambda Labs offers straightforward access to high-end GPUs without complex configuration options.

What you get:
- Pre-configured environments with popular ML frameworks
- H100, A100, and A6000 instances optimized for training
- Simple hourly pricing with no hidden fees
- Fast provisioning when capacity is available
Pricing: H100 (from $2.49/hr for 1x H100 PCIe, $3.29/hr for 1x H100 SXM), A100 (from $1.29/hr for 1x A100 40GB), and A6000 (from $0.80/hr for 1x A6000) instances optimized for training
The reliability concern: Lambda Labs frequently experiences capacity shortages, especially for popular GPU types, which can disrupt ongoing projects.
Best for: Training workloads and experimentation when GPU availability isn't a concern
Learn more: Top Lambda AI alternatives to consider for GPU workloads and full-stack apps
Now owned by DigitalOcean, Paperspace focuses on making GPU access simple for developers and researchers.

Key advantages:
- Jupyter notebook integration
- Simple pricing structure
- Good for prototyping and educational use
- Gradient platform for automated ML workflows
On-demand GPU pricing examples:
- H100 80GB: ($5.95/hr)
- A100 80GB: ($3.18/hr)
- A100 40GB: ($3.09/hr)
- RTX 4000 (24GB): ($0.56/hr)
- A6000 (48GB): ($1.89/hr)
- Subscription plans: In some cases, access to high-end GPUs on Paperspace's Gradient platform requires a monthly subscription, such as the Growth plan for $39/month
Limitations for production:
- Limited global presence (only three regions)
- No BYOC support
- Fewer enterprise features compared to alternatives
Best for: Solo developers, researchers, and teams doing early-stage development
Learn more: 7 best DigitalOcean GPU & Paperspace alternatives for AI workloads in 2026
After testing all these platforms, here's my decision framework:
- For production AI applications: Northflank wins for its combination of spot optimization, BYOC support, and automatic failover. You get enterprise reliability at marketplace prices.
- For experimentation and research: VastAI, if you can handle variable reliability. Great for training runs that can be checkpointed and resumed.
- For AI-specific workflows: RunPod provides pre-configured templates and community support. Great middle ground between cost and convenience.
- For maximum control: TensorDock provides enterprise hardware with full VM access, ideal when you need specific OS configurations or security isolation.
The major cloud providers are "cheap, but you may need to buy in bulk." Here's when each approach makes sense:
Bulk purchasing works when:
- You have consistent, predictable GPU usage
- You can negotiate enterprise volume discounts
- Compliance requires dedicated hardware
Pay-as-you-go is better for:
- Variable or seasonal workloads
- Startups with uncertain scaling patterns
- Teams experimenting with different GPU types
For most AI teams, pay-as-you-go with automated orchestration beats bulk purchasing because it provides flexibility without sacrificing savings.
→ If you want maximum savings with minimal complexity: Start with Northflank's spot optimization. You'll get enterprise reliability with marketplace pricing, plus automatic management of interruptions and multi-cloud orchestration.
→ If you're experimenting on a budget: Try VastAI for the lowest possible prices, but have backup plans for when instances become unavailable.
→ If you need AI-specific features: RunPod's templates and community make it easy to get started with popular frameworks.
Like I said earlier, the cheapest hourly rate doesn't always mean the lowest total cost. Factor in reliability, operational overhead, and the cost of downtime when making your decision.
Most successful AI teams end up using multiple platforms - spot instances for training, dedicated capacity for critical inference APIs, and development instances for experimentation.
The platforms that make this multi-cloud strategy seamless, like Northflank, tend to deliver the best long-term value. Try out Northflank for free or book a demo with an Engineer
Here are some additional resources to help you choose the right platform:
Learn more here:


