

Top 7 Crusoe alternatives in 2026
Crusoe alternatives offer diverse options for teams looking for different approaches to GPU cloud infrastructure.
Crusoe Cloud is a sustainable AI infrastructure provider with competitive pricing, though some teams need multi-cloud deployment options or different geographic coverage for their specific requirements.
If you're evaluating GPU cloud providers or considering options beyond a single vendor, this guide compares the top alternatives to help you make an informed decision.
See a quick list of the top 7 Crusoe alternatives we'll review in this guide:
-
Northflank - Best for startups and enterprises looking for multi-cloud GPU deployment with unified infrastructure management and no vendor lock-in.
Northflank is a unified cloud platform where you can deploy both CPU and GPU workloads alongside your databases, applications, APIs, background jobs, and CI/CD pipelines on AWS, GCP, Azure, Oracle Cloud, Civo, or bare-metal, all from a single interface with Git-based workflows and preview environments.
-
CoreWeave - Best for AI training and inference requiring Kubernetes-native infrastructure
-
Lambda Labs - Best for researchers and AI teams needing on-demand GPU clusters
-
RunPod - Best for developers needing GPU deployment
-
Nebius - Best for teams needing GPU cloud with technical capabilities
-
Hyperstack - Best for teams requiring specific data residency and managed services
-
Traditional hyperscalers (AWS, GCP, Azure) - Best for organizations already invested in a specific cloud ecosystem
When evaluating GPU cloud providers, consider these criteria to find the best fit for your team's requirements.
- Cost transparency - Look for clear, predictable pricing without hidden fees for networking, storage, or data transfer. Compare hourly rates across GPU types, and evaluate spot vs. reserved instance options. Consider the total cost of ownership, including support, monitoring, and orchestration tools.
- GPU availability and variety - Assess the range of GPU options from consumer cards (RTX series) to enterprise GPUs (A100, H100, H200, GB200). Check availability across regions and the ability to scale from single GPUs to multi-node clusters. Spot instance availability and pricing volatility matter for cost optimization.
- Developer experience - The best alternatives provide intuitive interfaces, robust APIs, CLI tools, and integration with popular ML frameworks. Look for features like Jupyter notebook support, custom Docker containers, Git-based workflows, and orchestration options (Kubernetes, Slurm).
- Performance and reliability - Evaluate uptime SLAs, networking bandwidth (InfiniBand, RDMA), storage performance (NVMe, parallel file systems), and fault tolerance mechanisms. Check independent benchmarks like ClusterMAX ratings for objective performance comparisons.
- Scalability and orchestration - Consider both vertical scaling (single GPU to multi-GPU instances) and horizontal scaling (multi-node clusters). Managed orchestration services, auto-scaling capabilities, and support for distributed training frameworks reduce operational overhead.
- Support and compliance - Production AI workloads require responsive support, security certifications (SOC 2, ISO 27001), and compliance capabilities. Evaluate SLAs, support response times, and whether you get direct access to technical experts.
We've evaluated the following alternatives based on cost-effectiveness, deployment flexibility, developer experience, performance, and scalability to help you find the best fit for your requirements.
Northflank is a unified cloud platform combining GPU compute with complete infrastructure management and multi-cloud flexibility. Built for teams evaluating Crusoe alternatives without vendor lock-in, Northflank lets you deploy your entire stack, including GPU workloads, databases, applications, APIs, background jobs, and CI/CD pipelines, across multiple clouds from a single platform.
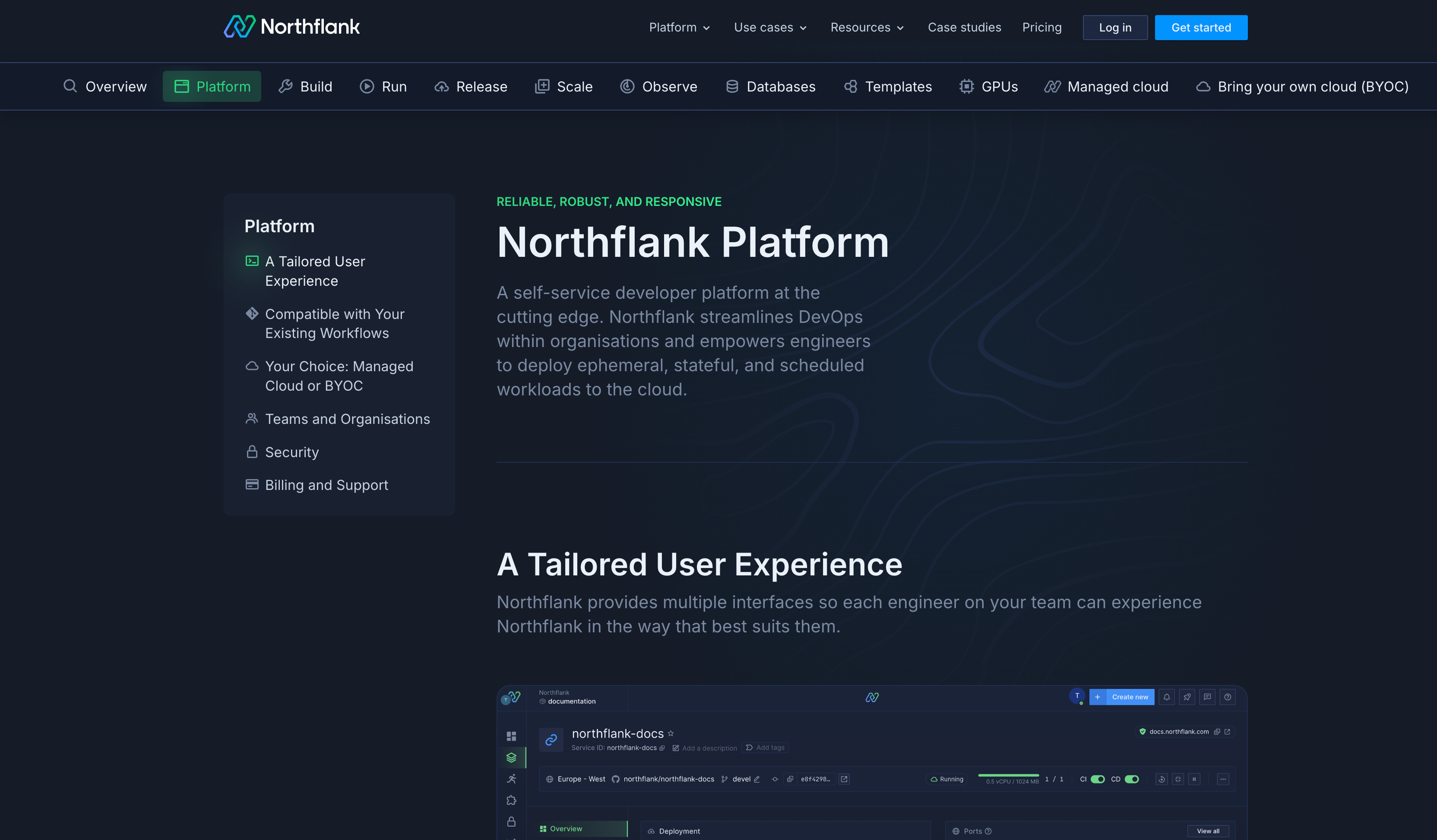
Key features
- Multi-cloud GPU deployment - Deploy GPU workloads on AWS, GCP, Azure, Oracle Cloud, Civo, or bare-metal from a unified platform. Choose from 600 regions without vendor lock-in. Run on Northflank's managed cloud or bring your own cloud account (BYOC) to maintain existing cloud relationships and billing.
- Transparent, predictable pricing - Simple usage-based pricing with per-second billing for CPU, GPU, memory, and storage. No hidden fees for networking, monitoring, or data transfer. Compare costs across providers in real-time and optimize spending with built-in cost analytics. Try out the pricing calculator.
- Unified infrastructure platform - Deploy GPU compute alongside managed databases (PostgreSQL, MySQL, MongoDB, Redis), applications, APIs, background jobs, and CI/CD pipelines on the same platform. Create complete environments with GPUs and supporting infrastructure together.
- Developer-first workflows - Git-based deployments with automatic builds on every commit. Preview environments for pull requests to test changes safely. Connect locally using Northflank CLI without exposing infrastructure publicly. Support for custom Docker containers and popular ML frameworks.
- Built-in observability - Real-time log tailing with filtering and search. Performance metrics for GPU utilization, memory, network, and storage displayed in intuitive dashboards. Configure alerts via Slack, email, or webhooks. No separate monitoring tools needed.
- Enterprise-ready security - Private networking between services without complex VPC configurations. TLS/SSL encryption enabled by default. Fine-grained role-based access controls. Deploy in your own Kubernetes clusters (EKS, GKE, AKS) for maximum control. 24/7 enterprise support.
- Flexible GPU options - Access NVIDIA A100, H100, H200, B200, L4, L40S, and other GPU types across multiple cloud providers. Scale from single GPUs for development to multi-GPU instances for training. Right-size instances without overpaying for unused resources.
Pricing
Sandbox tier
- Free resources to test workloads
- 2 free services, 2 free databases, 2 free cron jobs
- Always-on compute with no sleeping
Pay-as-you-go
- Per-second billing for compute (CPU and GPU), memory, and storage
- No seat-based pricing or commitments
- Deploy on Northflank's managed cloud (6+ regions) or bring your own cloud (600 BYOC regions across AWS, GCP, Azure, Civo)
- GPU pricing: NVIDIA A100 40GB at $1.42/hour, A100 80GB at $1.76/hour, H100 at $2.74/hour, H200 at $3.14/hour, B200 at $5.87/hour
- Bulk discounts available for larger commitments
Enterprise
- Custom requirements with SLAs and dedicated support
- Invoice-based billing with volume discounts
- Hybrid cloud deployment across AWS, GCP, Azure
- Run in your own VPC with managed control plane
- Secure runtime and on-prem deployments
- Audit logs, Global back-ups and HA/DR
- 24/7 support and FDE onboarding
Use the Northflank pricing calculator for exact cost estimates based on your specific requirements, and see the pricing page for more details
Why choose Northflank
Northflank addresses major Crusoe pain points:
- Multi-cloud freedom - Deploy GPU workloads anywhere without Crusoe's specific data center limitations. Switch providers or go multi-cloud without infrastructure rewrites.
- Unified platform advantage - Manage GPU compute with databases, applications, and CI/CD in one place instead of piecing together separate GPU cloud and infrastructure providers.
- Transparent costs - Predictable per-second billing with real-time cost visibility vs. complex GPU cloud pricing structures. No surprises from networking or egress fees.
- Developer velocity - Git-based workflows, preview environments, and integrated CI/CD reduce time from code to GPU-powered production. No separate orchestration tools required.
- Enterprise flexibility - BYOC (Bring Your Own Cloud) deployment on your own AWS, GCP, Azure, Civo, Oracle Cloud, or bare-metal infrastructure maintains cloud commitments while gaining superior GPU management and unified infrastructure control.
Learn more: GPU Workloads on Northflank | GPU instances on Northflank | Documentation | Request your GPU cluster
CoreWeave provides Kubernetes-native GPU cloud infrastructure for AI training and inference. CoreWeave operates infrastructure at scale for AI labs and organizations across multiple data centers.

Key features
- Kubernetes-native architecture with bare-metal performance
- GPUs including NVIDIA H100, H200, GB200 NVL72, and RTX PRO 6000 Blackwell
- Capability to operate GPU clusters with multiple nodes
- Mission Control software for automated health checks and lifecycle management
- InfiniBand networking with NVIDIA Quantum-2
Best for
AI labs, model training operations, and organizations needing Kubernetes-native infrastructure with capacity guarantees.
Considerations
Focused on reserved capacity arrangements. Kubernetes expertise required to leverage platform capabilities. Less suited for teams needing short-term or on-demand access.
Lambda Labs offers GPU cloud infrastructure with emphasis on simplicity. Known for 1-Click Clusters that provision interconnected GPUs, Lambda serves research teams and AI startups needing compute access.

Key features
- On-demand NVIDIA HGX B200, H100, A100, and GH200 instances
- 1-Click Clusters with pre-configured networking
- Pre-installed ML stack with PyTorch, TensorFlow, CUDA, and Jupyter
- Lambda Private Cloud for dedicated GPU clusters
- NVIDIA Quantum-2 InfiniBand networking for distributed training
- Used by research universities
Best for
Academic researchers, AI startups, teams prototyping models, and organizations wanting GPU access without complex cloud configurations.
Considerations
Limited to Lambda's own infrastructure with no multi-cloud options. Smaller geographic footprint compared to hyperscalers. Fewer features like custom VPC networking or integration with broader cloud services. Suited for compute-focused workloads rather than complex multi-service architectures.
RunPod provides GPU cloud with deployment across multiple regions. Offering GPU instances across 31 regions, RunPod serves developers and small teams needing access to GPUs.

Key features
- GPU deployment across 30+ regions
- Secure Cloud and Community Cloud options
- Serverless GPU with automatic scaling and idle shutdown
- Support for custom Docker containers and pre-built templates
- CLI and API for automation and CI/CD integration
- Spot instances for interruptible workloads
Best for
Individual developers, small ML teams, rapid prototyping, and inference serving.
Considerations
Community Cloud providers may have lower uptime than data centers. Limited support for multi-node clusters. Documentation and tooling less mature than established providers. Suited for smaller workloads rather than training large models.
Nebius offers GPU cloud infrastructure with technical capabilities. Using ODM hardware and lightweight virtualization, Nebius maintains Gold-tier performance ratings in independent benchmarks.
Key features
- Provisioning of GPU clusters
- Lightweight VMs with bare-metal class performance using kubevirt
- GPU inventory availability
- Data center presence in Europe for regional compliance
- ODM hardware strategy
Best for
Teams needing GPU cloud with technical capabilities and organizations requiring access to GPUs.
Considerations
Newer entrant with smaller ecosystem than established providers. Less brand recognition may concern procurement teams. Limited geographic presence outside Europe. Smaller customer base means fewer community resources and examples.
Hyperstack provides GPU cloud infrastructure from data centers in Europe. Offering NVIDIA H100, A100, and RTX-series GPUs, Hyperstack serves teams requiring data residency in Europe with managed services.
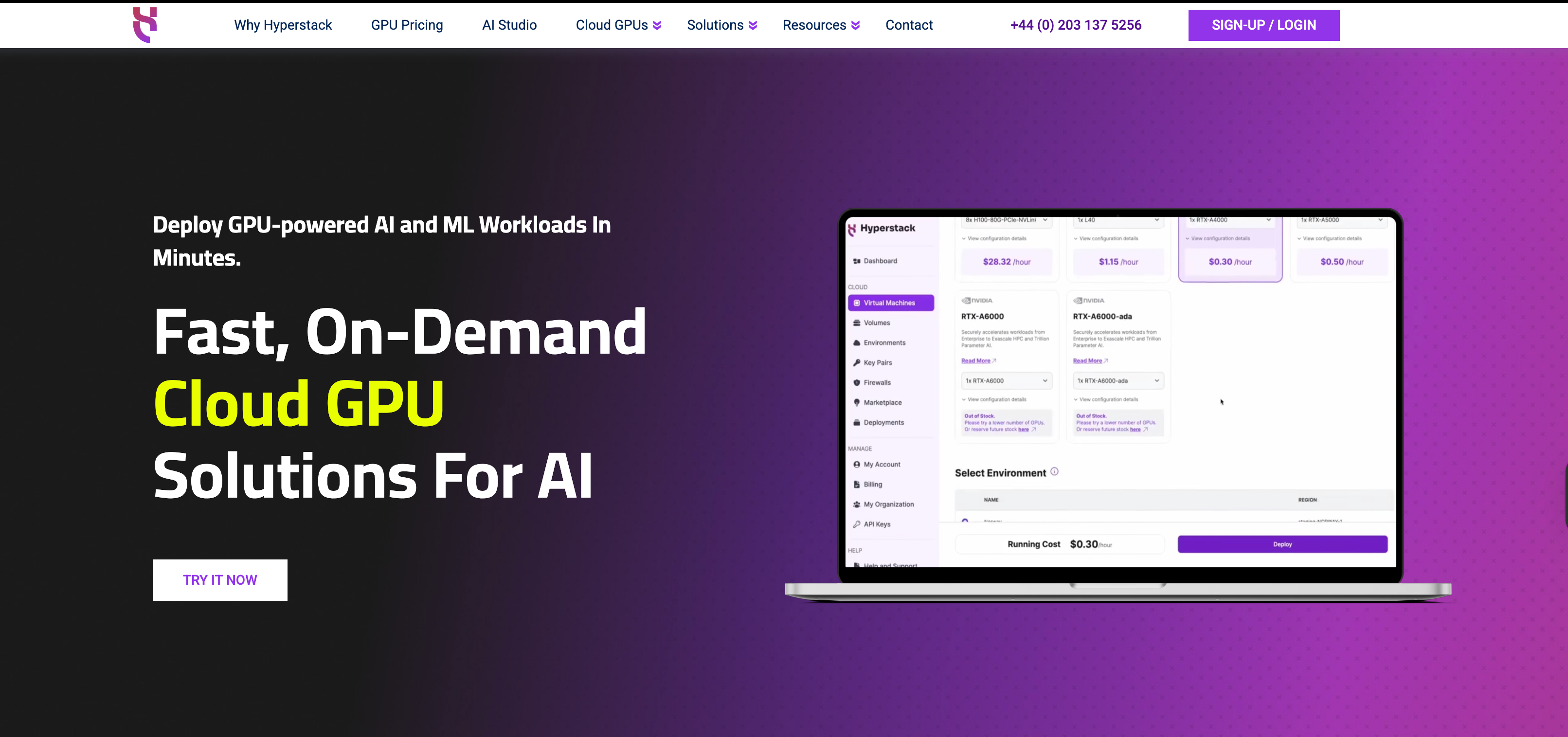
Key features
- Data centers in Europe for GDPR compliance and data residency
- NVIDIA H100, A100, and RTX GPUs
- VPC networking and security controls
- Managed Kubernetes and orchestration services
- Support for custom Docker containers and ML frameworks
- Sales support for accounts
Best for
Organizations requiring data residency in Europe, teams with GDPR compliance needs, and companies wanting regional GPU providers with managed services.
Considerations
Limited to geographic presence in Europe. Smaller GPU inventory compared to global providers. Less mature ecosystem and tooling than established alternatives.
AWS, Google Cloud, and Microsoft Azure offer GPU instances as part of comprehensive cloud platforms. While not specialized for AI workloads, hyperscalers provide integration with broader cloud services, global infrastructure, and compliance certifications.
Key features
- AWS - P5 instances with H100 GPUs, SageMaker for managed ML, service integration
- GCP - A2 and A3 instances with A100/H100 GPUs, TPU alternatives, Vertex AI platform
- Azure - NC-series with NVIDIA GPUs, Azure ML integration, Microsoft ecosystem integration
- Data center presence across multiple regions
- Compliance certifications (SOC 2, ISO 27001, HIPAA, PCI-DSS)
- Integration with storage, networking, security, and database services
- Committed to using discounts and spot instances
Best for
Organizations already using AWS/GCP/Azure for infrastructure, enterprises requiring specific compliance certifications, and teams needing integration with other cloud services.
Considerations
Higher costs compared to specialized GPU cloud providers. Complex pricing structures with multiple fees for networking, storage, and data transfer. GPU availability can be limited during high-demand periods. Suited for organizations prioritizing ecosystem integration.
Use this comparison to identify which alternative aligns with your technical requirements and deployment needs.
| Alternative | Best for | Key advantages | GPU options | Pricing model |
|---|---|---|---|---|
| Northflank | Startups to enterprises needing multi-cloud flexibility and unified infrastructure | Multi-cloud deployment across AWS, GCP, Azure, Oracle Cloud, Civo, and bare-metal; unified platform with databases and CI/CD; BYOC option; Git-based workflows | B200, H200, A100, H100, L4, L40S, GH200, and more GPU types across multiple clouds | A100 40GB from $1.42/hr, A100 80GB from $1.76/hr, H100 from $2.74/hr, H200 from $3.14/hr, B200 from $5.87/hr |
| CoreWeave | AI labs needing Kubernetes-native infrastructure | Kubernetes-native architecture | H100, H200, GB200 NVL72, RTX PRO 6000 | Reserved capacity arrangements |
| Lambda Labs | Research teams and academic institutions | 1-Click Clusters, pre-installed ML stack | HGX B200, H100, A100, GH200 | On-demand and reserved options |
| RunPod | Developers needing deployment flexibility | Deployment across 30+ regions, serverless options, Community and Secure Cloud | H100, A100, RTX 4090, RTX 3090 | Per-second billing model |
| Nebius | Teams needing technical capabilities | kubevirt architecture | A100, H100, NVIDIA GPUs | Various pricing options |
| Hyperstack | Organizations with European data residency requirements | Data centers in Europe, GDPR compliance, managed services | H100, A100, RTX-series | Hourly and monthly options |
| Hyperscalers | Organizations invested in cloud ecosystems | Service integration, compliance certifications, global infrastructure | Various NVIDIA GPUs, TPUs (GCP) | Varies by provider |
For teams evaluating alternatives to Crusoe's infrastructure, several options provide different approaches to GPU cloud computing.
Northflank stands out as a unified cloud platform (both CPU and GPU workloads), not just a GPU provider. You get multi-cloud flexibility to deploy on AWS, GCP, Azure, Oracle Cloud, Civo, or bare-metal from a single interface.
Unlike specialized GPU clouds locked to their own infrastructure, Northflank lets you run your entire stack in one place: GPU workloads alongside databases, applications, APIs, background jobs, and CI/CD pipelines. This removes the need to manage separate tools for GPU compute and infrastructure, while transparent per-second billing ensures cost predictability across providers.
From GPUs for training models to databases for your application, everything is managed from one platform with Git-based workflows and preview environments.
- Start with a free account or go straight to request your GPU cluster - Test workloads and infrastructure
- Book a demo with an expert engineer
- Calculate savings with the pricing calculator
- Learn more: GPU Workloads on Northflank | GPU instances on Northflank | Documentation


