

GPU sandboxes: isolation models and platform support in 2026
- A GPU sandbox is an isolated execution environment where a workload gets access to a GPU with a hardware or syscall-level boundary separating it from the host and other tenants. Most sandbox platforms do not support GPU workloads at all.
- GPU isolation requires hardware-level PCIe device passthrough, IOMMU configuration, and a VMM that supports passing devices through into a VM. Most sandbox platforms use Firecracker, which does not support GPU passthrough, making them CPU-only by design.
- Northflank is one of the few platforms that supports sandboxing both CPU and GPU workloads. Where nested virtualization is available, Northflank uses microVM-based isolation (KVM / Kata Containers) to run GPU workloads, with the GPU passed through into the sandboxed runtime. This is the same execution model as CPU workloads, with strong isolation guarantees.
- Where nested virtualization is unavailable, Northflank falls back to gVisor. GPU workloads still run inside the sandboxed environment, but the isolation boundary is at the syscall level rather than hardware virtualization. The deployment model is the same in both cases.
GPU sandboxes are isolated execution environments that give untrusted workloads access to a GPU while enforcing hardware or syscall-level boundaries between the workload, the host system, and other tenants.
Most sandbox platforms today are CPU-only, and the reason comes down to how GPU hardware virtualization works at the PCIe level.
This article explains the technical constraints that make GPU sandboxing harder than CPU sandboxing, how the nested virtualization requirement shapes which isolation model applies, and which platforms support GPU workloads in sandboxed environments today.
A GPU sandbox is an isolated execution environment that provides a workload with access to a GPU while preventing it from affecting the host system or other tenants.
A bare-metal GPU instance gives a single tenant unrestricted access with no isolation boundary. A GPU-enabled container shares the host kernel and NVIDIA driver namespace with everything else on that host.
A GPU sandbox adds an isolation layer using hardware virtualization or syscall interception, which is what makes multi-tenant GPU execution safe.
CPU sandboxing and GPU sandboxing solve different problems at different layers of the stack. Understanding the distinction explains why most sandbox platforms support only CPU workloads.
CPU workload isolation requires memory isolation, syscall boundaries, and process separation. Both microVMs, which give each workload its own kernel via hardware virtualization, and gVisor, which intercepts system calls in user space, solve this problem well. The problem is well-understood, and multiple viable solutions exist.
GPUs are PCIe devices. To sandbox a GPU workload you need: an IOMMU (Intel VT-d or AMD-Vi) to enforce DMA isolation, preventing one tenant's GPU from reading or writing another tenant's memory over the PCIe bus; VFIO binding to detach the GPU from the host driver and assign it to a specific VM; IOMMU group separation so devices sharing a group are assigned together; and a VMM that supports PCIe device passthrough. On multi-GPU systems with NVLink fabrics, nv-fabricmanager adds further host-level isolation requirements.
Firecracker excludes GPU passthrough as a design decision to minimize its attack surface. It implements only six emulated devices: virtio-net, virtio-block, virtio-balloon, virtio-vsock, serial console, and a minimal keyboard controller.
Because E2B, Fly.io Sprites, and Vercel Sandbox all use Firecracker for isolation, none of them can sandbox GPU workloads. VMMs that support PCIe device passthrough are required for GPU access inside a sandboxed VM. Northflank uses Kata Containers for microVM-based workloads.
See what is AWS Firecracker, Firecracker vs gVisor, and the guide to Cloud Hypervisor.
Nested virtualization determines which isolation path is available for GPU sandboxes. MicroVM-based isolation requires KVM to be present, and most cloud VMs do not expose this since the host hypervisor does not pass the KVM interface through to VMs running on top of it.
Without nested virtualization, hardware-level GPU passthrough through microVMs is not available, and platforms need to use an alternative isolation approach.
Northflank handles this constraint differently depending on the underlying infrastructure.
When nested virtualization is available, Northflank uses microVM-based isolation to run GPU workloads. The GPU is passed through into the sandboxed runtime, and the workload runs inside a hardware-isolated VM with its own kernel. This is the same execution model used for CPU workloads, with strong isolation guarantees. See Kata Containers vs Firecracker vs gVisor and microVM vs gVisor.
When nested virtualization is unavailable, Northflank falls back to gVisor. GPU workloads run inside the sandboxed environment with access to the GPU, but the isolation boundary sits at the syscall level rather than at hardware virtualization. The deployment model is identical across both paths: the same APIs, the same workload definitions, the same platform. What changes is the isolation mechanism applied underneath.
Northflank supports both CPU and GPU workloads in isolated sandbox environments, with the isolation model adapting to the underlying infrastructure as described above.
Sandboxes start in approximately 1 to 2 seconds and support both ephemeral and persistent environments. GPU workloads run on on-demand NVIDIA GPUs including L4, A100 (40GB and 80GB), H100, and H200, with self-service provisioning and no quota requests required.
The same platform also runs APIs, background workers, databases, and GPU inference alongside sandboxes, so teams are not managing separate tooling for each workload type.
BYOC (Bring Your Own Cloud) deployment is available self-serve across AWS, GCP, Azure, Civo, Oracle Cloud, CoreWeave, and on-premises. Teams with data residency requirements or compliance mandates can deploy GPU sandboxes inside their own VPC using the same isolation model as the managed cloud. Northflank has been running production workloads across startups, public companies, and government deployments since 2021.
Get started with GPU sandboxes on Northflank
- Sandboxes on Northflank: architecture overview and core sandbox concepts
- Deploy sandboxes on Northflank: step-by-step deployment guide
- Deploy sandboxes in your cloud: run sandboxes inside your own VPC
- GPUs on Northflank: GPU workload overview and supported GPU types
- Deploy GPUs on Northflank cloud: step-by-step GPU deployment guide
- Deploy GPUs in your own cloud: GPU workloads inside your own VPC
Get started (self-serve), or book a session with an engineer if you have specific infrastructure or compliance requirements.
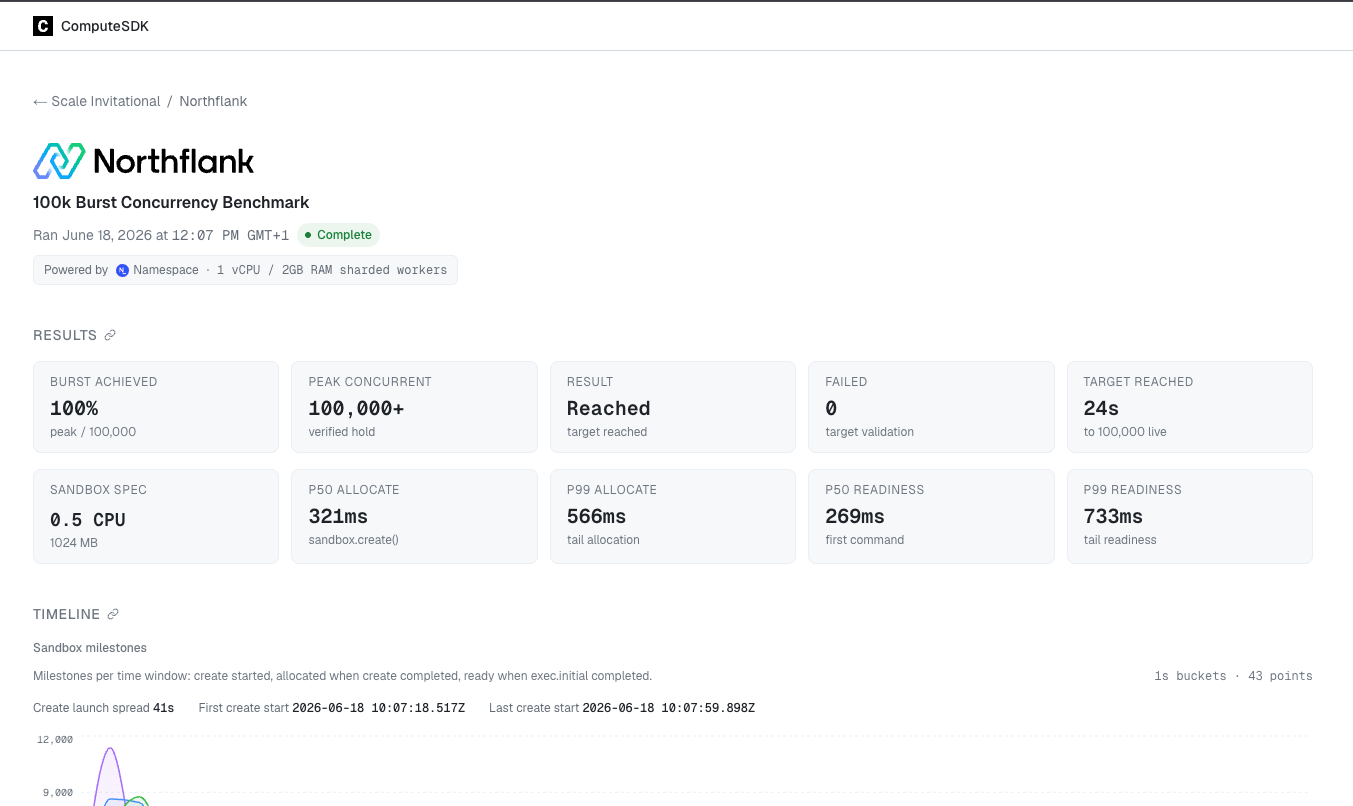
Northflank at 100,000 concurrent sandboxes. In the ComputeSDK 2026 Scale Invitational, Northflank reached 100,000 concurrent live sandboxes in 24 seconds from a cold start with zero failures, the fastest time of any participant. P99 allocate latency was 566ms and P99 readiness was 733ms, compared to 2.69s and 1.42s for E2B and 1.51s and 3.67s for Modal. At scale, tail latency determines the slowest sandbox your system waits on before the full fleet is live. See the full results.
The table below covers GPU support within the sandboxed execution environment specifically.
| Platform | GPU support | Isolation model | Bring Your Own Cloud (BYOC) | Persistent environments |
|---|---|---|---|---|
| Northflank | Yes | Kata Containers (microVM) / gVisor | Yes, self-serve across multiple clouds | Yes (ephemeral and persistent) |
| Modal | Yes | gVisor | No, managed only | Partial (snapshotting available) |
| E2B | No (CPU only) | Firecracker microVMs | Enterprise only (AWS, GCP) | Yes (pause/resume, indefinite retention) |
| Fly.io Sprites | No (CPU only) | Firecracker microVMs | No, managed only | Yes (persistent NVMe filesystem) |
| Vercel Sandbox | No (CPU only) | Firecracker microVMs | No, managed only | Beta |
| Blaxel | No (CPU only) | Firecracker microVMs | Custom (contact sales) | Yes (standby with state preserved) |
For deeper platform comparisons, see E2B vs Modal vs Fly.io Sprites, E2B vs Modal, and top BYOC AI sandboxes.
Not every GPU workload requires a sandboxed environment. A single-tenant inference service or a dedicated training job on reserved hardware does not need the isolation layer.
GPU sandboxes are relevant when the execution environment is shared, and workloads are untrusted or user-submitted:
- Platforms where multiple tenants submit GPU-accelerated code, and each workload needs isolation from the others
- AI agents calling local inference or embedding generation rather than an external API
- Platforms running user-submitted training jobs or reinforcement learning reward evaluations at scale
- Code execution products that allow users to attach GPUs to notebooks or execution environments
Pricing at scale differs significantly across platforms. The table below shows the total cost for 200 concurrent sandboxes across PaaS and BYOC deployment models, based on an nf-compute-100-4 plan on an m7i.2xlarge infrastructure node. Pricing as of May 2026. Verify current rates on each platform's pricing page before making cost decisions.
| Model | Provider | Cloud cost | Sandbox vendor cost | Total |
|---|---|---|---|---|
| PaaS | Northflank | — | $7,200.00 | $7,200.00 |
| PaaS | E2B | — | $16,819.20 | $16,819.20 |
| PaaS | Modal | — | $24,491.50 | $24,491.50 |
| PaaS | Fly Sprites | — | $35,770.00 | $35,770.00 |
| PaaS | Vercel Sandbox | — | $31,068.80 | $31,068.80 |
| BYOC (0.2 overcommit) | Northflank | $1,500.00 | $560.00 | $2,060.00 |
| BYOC | E2B | $1,500.00 | $10,000.00 | $11,500.00 |
The BYOC row for Northflank reflects a request modifier of 0.2. On BYOC plans, Northflank applies an overcommit so more sandboxes run on the same hardware. For example, with a modifier of 0.2, each sandbox requests 20% of its plan resources as a guaranteed minimum but can burst to the full limit when capacity is available, fitting 40 sandboxes per node instead of 8. This comparison covers CPU sandbox workloads. GPU workload costs depend on GPU type and usage pattern. See the Northflank pricing page for current GPU rates.
Most sandbox providers use Firecracker microVMs, which do not support GPU passthrough. GPU passthrough requires VFIO binding, IOMMU configuration, and a VMM that supports PCIe device passthrough. Firecracker's minimal virtio device set does not include these capabilities.
MicroVM isolation passes the GPU into a hardware-isolated VM; the workload runs its own kernel with a hardware boundary separating it from the host. gVisor intercepts the NVIDIA device calls in user space and proxies them to the host driver. Both provide GPU access inside a sandboxed environment; the isolation boundary differs.
Yes. MicroVM-based GPU passthrough requires KVM, which requires bare metal or a host with nested virtualization enabled. Where nested virtualization is unavailable, gVisor is the fallback. The deployment interface is identical in both cases.
Northflank supports self-serve BYOC deployment across AWS, GCP, Azure, Civo, Oracle Cloud, CoreWeave, and on-premises. GPU sandboxes can run inside your own VPC using the same isolation model as the managed cloud.
Northflank provides on-demand access to NVIDIA L4, A100 (40GB and 80GB), H100, H200, and additional GPU types with self-service provisioning and no quota requests. See the Northflank GPU documentation for the current list.
The following articles cover topics referenced in this piece in more depth.
- Kata Containers vs Firecracker vs gVisor: in-depth comparison of the three primary container isolation technologies
- What is a microVM?: microVM architecture and how it differs from containers and full VMs
- What is gVisor?: gVisor's syscall interception model, execution modes, and use cases
- E2B vs Modal vs Fly.io Sprites: sandbox platform comparison across isolation model, GPU support, persistence, and BYOC
- Self-hosted AI sandboxes: running AI sandbox infrastructure on your own cloud or on-premises
- Top BYOC AI sandboxes: sandbox platforms that support bring-your-own-cloud deployment
- Reinforcement learning agents in secure sandboxes: sandboxed environments for RL reward function evaluation at scale
- Best platforms for running untrusted code: platforms designed for safely executing untrusted workloads

