You can configure autoscaling to automatically respond to increases in activity on your deployments, and ensure you have the resources needed to process your traffic even at peak times.
Horizontal autoscaling allows your services to automatically scale up the number of instances for your deployment. The Northflank load-balancer will evenly distribute incoming traffic between different instances of a deployment.
Configure horizontal autoscaling
To enable autoscaling, expand advanced resource options in your deployment's resource page, or in the resources section when creating your deployment. This is available in combined and deployment services.
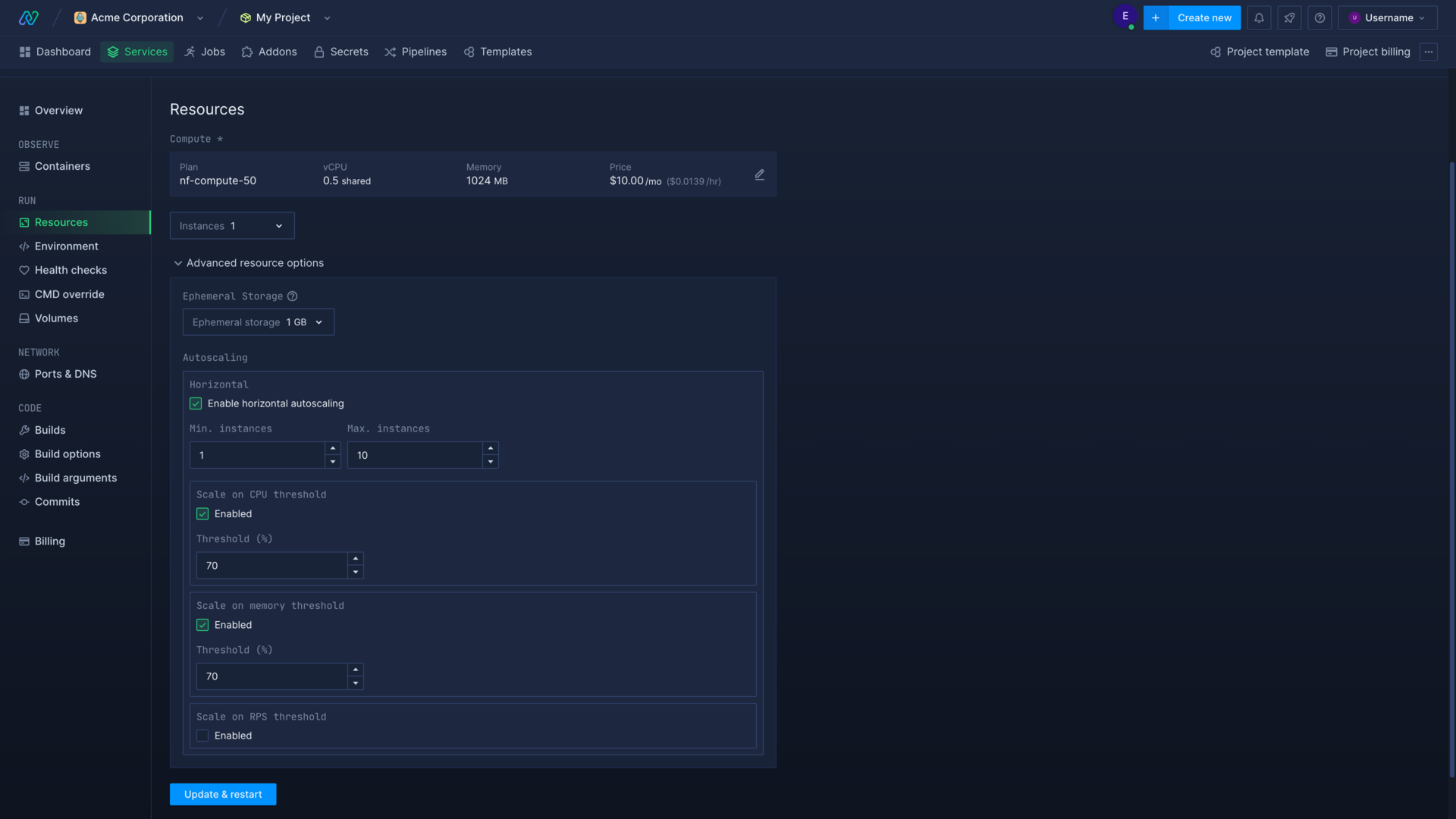
Select enable horizontal autoscaling to turn on autoscaling for the deployment and view the configuration options:
- Minimum instances: set the minimum number of instances the deployment will scale down to. This should be set to the number of instances that can comfortably handle your deployment's normal level of activity.
- Maximum instances: set the maximum instances the deployment can scale up to, to limit your spend
- Scale on CPU threshold: enable and enter the value (% of CPU in use) to trigger scaling when your instances pass the threshold
- Scale on memory threshold: enable and enter the value (% of memory in use) to trigger scaling when your instances pass the threshold
- Scale on RPS (requests per second): enable and enter the value (number of requests per second) to trigger scaling when your instances pass the threshold
You can trigger autoscaling on either CPU or memory usage, RPS, or all. You can monitor the metrics for your containers in the Northflank application, or by using the Northflank API to decide upon the best thresholds to set for your services. If your usage spikes quite quickly, and/or your application takes some time to initialise, you may want to set lower thresholds so that new containers are available before the existing ones reach capacity.
Custom metric autoscaling
If your application has autoscaling requirements based on metrics which are not supported by the platform (e.g. queue latency, tcp opened connections) you have the option to expose your own custom metrics via a Prometheus endpoint within your deployment.
To configure autoscaling on your own custom metrics the following data has to be configured in the autoscaling section of your service:
- The Prometheus endpoint and port exposed by the application have to be specified
- The metric name, metric type (Gauge or Counter) and the scaling threshold value have to be specified
The metrics exposed by your application have to comply with the Prometheus metric structure
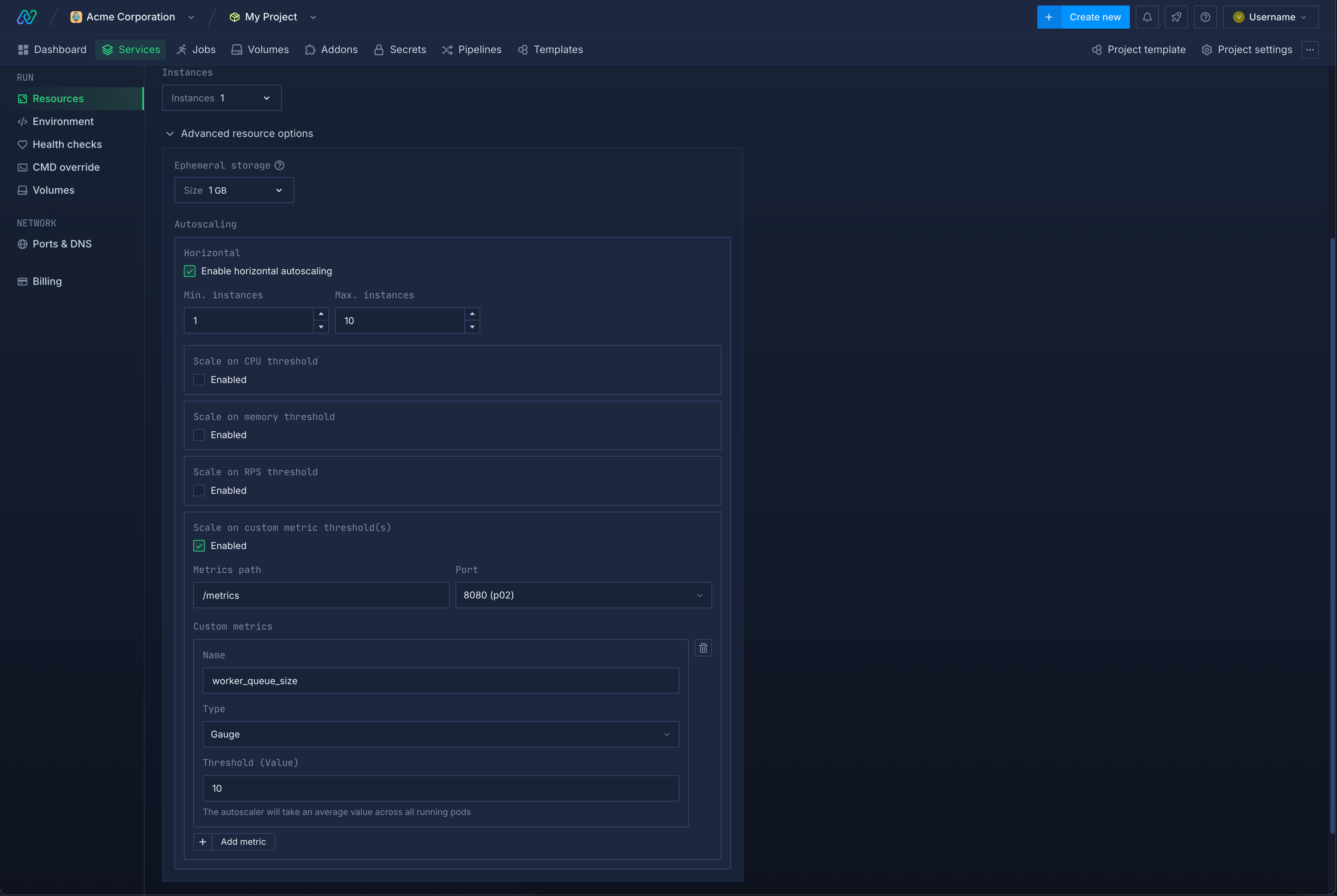
The metric type defines how the values returned by the Prometheus endpoint will be interpreted.
- Gauge: The value will be treated as is (useful for e.g. queue size)
- Counter: Applies a rate() query on the value to measure the rate of change (useful for e.g. message processing rate)
In both cases the resulting value will be averaged across all running pods.
Horizontal autoscaling behaviour
Your deployment will be checked every 15 seconds to calculate whether to trigger autoscaling. The average usage across all your instances is taken for each metric. If you are using more than one metric your deployment will be scaled to the highest number of required instances from any metric.
The required number of instances is calculated using this formula: requiredInstances = ceil[currentInstances * ( currentMetricValue / desiredMetricValue )].
When scaling up, autoscaling will not be triggered again until the new containers are in the running state, which prevents the creation of too many new instances.
Downscaling compares all the checks at 15-second intervals from a moving 5-minute window to ensure capacity is not reduced too quickly based on short-term drops in activity. For example, if a deployment is scaled to 5 instances and checks in the 5-minute window calculate that the deployment can be scaled down to either 1, 3, or 4 instances, then the deployment will be scaled down to 4 instances. If at any point a check returns a higher number of required instances, the deployment will immediately be scaled up.